Python数据分析入门笔记9 |
您所在的位置:网站首页 › 中国男篮历史十大球员身高数据表 › Python数据分析入门笔记9 |
Python数据分析入门笔记9
|
系列文章目录
Python数据分析入门笔记1——学习前的准备 Python数据分析入门笔记2——pandas数据读取 Python数据分析入门笔记3——数据预处理之缺失值 Python数据分析入门笔记4——数据预处理之重复值 Python数据分析入门笔记5——数据预处理之异常值 Python数据分析入门笔记6——数据清理案例练习 Python数据分析入门笔记7——数据集成、变换与规约 Python数据分析入门笔记8——Pandas处理日期时间类型数据 Python数据分析入门笔记 系列文章目录前言预备知识: 一、任务说明1. 数据文件下载:2. 任务要求: 二、任务分析与预处理1. 数据分析流程2. 数据获取与初步处理(1)文件的读取——read_csv()和read_excel()(2)文件的合并——merge()(3)数据的筛选 3. 数据清理(1)检测与处理重复值——duplicated()和drop_duplicates()(2)处理缺失值,统一单位——fillna()(3)检测与处理异常值——3σ和箱型图 三、 任务执行:分析运动员数据1. 计算中国男篮、女篮运动员的平均身高与平均体重,保留一位小数2. 分析中国篮球运动员的年龄分布3. 计算中国篮球运动员的体质指数 总结 前言前面学过了pandas数据清理、数据集成、数据变换和数据规约相关知识,今天用一个运动员基本信息的案例来练习删除重复值、填充缺失值、确认异常值、分组与聚合、轴向旋转和降采样等操作,以达到清理数据、整合数据、减少数据量、变换数据形式的目的。 预备知识:
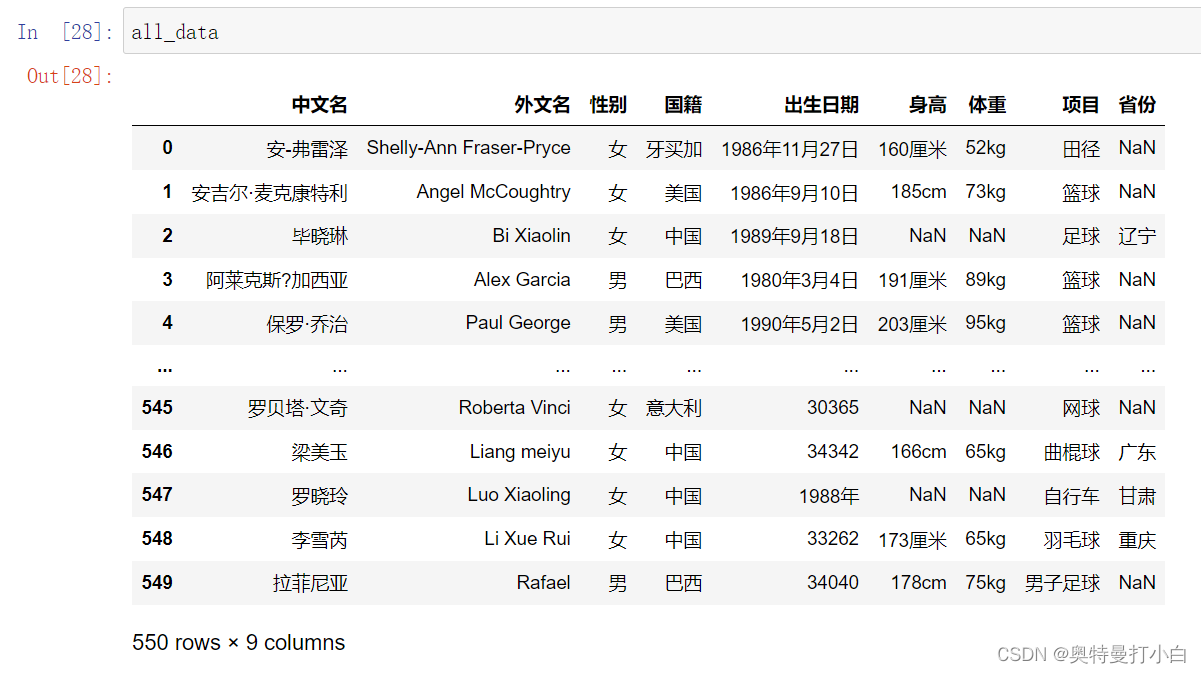
运动员信息采集01.csv 运动员信息采集02.xlsx 运动员信息采集01.csv文件部分内容如下: (1)计算中国男篮、女篮运动员的平均身高与平均体重。 (2)分析中国篮球运动员的年龄分布 (3)计算中国篮球运动员的体质指数 二、任务分析与预处理 1. 数据分析流程在进行数据分析之前,必须事先对数据进行预处理。 首先读取这两个文件,由于文件中含有中文,因此读取csv文件时需要设置编码为‘gbk’。 代码如下: import pandas as pd file_one=pd.read_csv('data/运动员信息采集01.csv',encoding='gbk') file_two=pd.read_excel('data/运动员信息采集02.xlsx') 报错说明——若读取csv的时候未设置中文编码,会报如下错误: UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xd6 in position 0: invalid continuation byte报错说明——若读取excel的时候,设置了encoding,会报如下错误: TypeError:read_excel() got an unexpected keyword argument ‘encoding’一点疑问——读取中文必须gbk吗?为什么utf-8也不识别?read_excel方法中原来是有encoding参数的,取消掉以后如果再遇到编码问题要如何处理? (2)文件的合并——merge()首先观察两个文件中的列索引,万幸的是,两张表中的列索引完全一致,也就是属性方面是匹配的,因此,我们可以直接进入数据集成环节。 这个案例中的合并类似于两个班级表的合并,因此,主键合并可直接用merge方法,选用outer全外连接的方式,保留两张表中所有原始数据。 代码如下: all_data=pd.merge(left=file_one,right=file_two,how='outer') all_data合并后的数据如下: 由于题目要求对中国篮球运动员进行分析,因此需要根据国籍筛选一下,只保留国籍为中国的运动员。 我又忘记怎么写了,先单独筛选国籍看看?
在对数据进行分析之前,我们需要先解决前面发现的数据问题,包括重复值、缺失值和异常值的检测与处理,从而为后期分析工作提供高质量的数据。 (1)检测与处理重复值——duplicated()和drop_duplicates()
因此,检测重复值的代码如下: all_data[all_data.duplicated().values==True]找到以下五条重复值 运行结果如图: 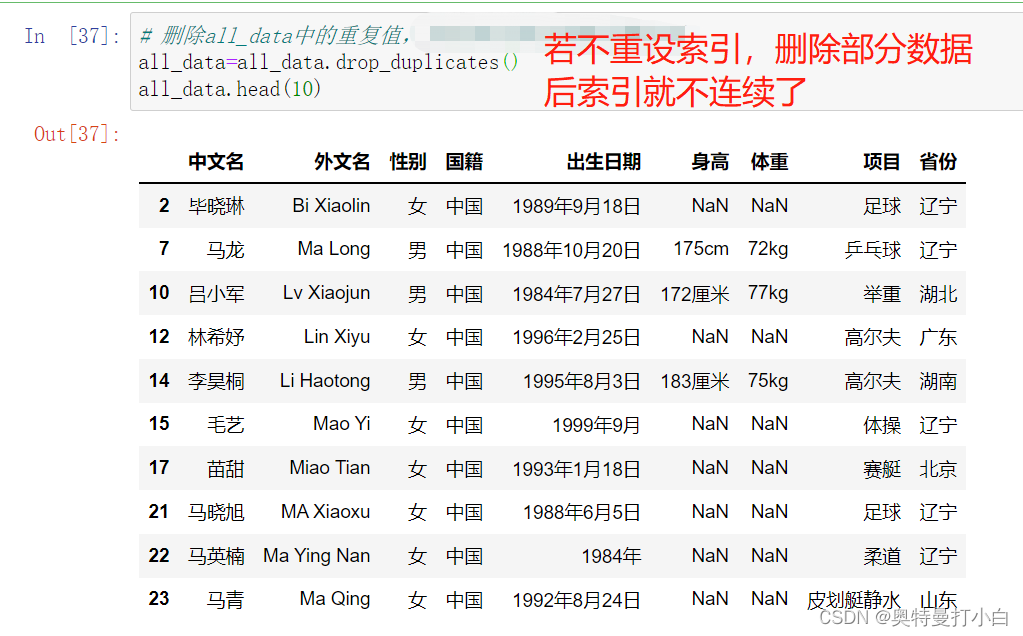 (2)处理缺失值,统一单位——fillna()
(2)处理缺失值,统一单位——fillna()
由于本例只需要分析中国篮球运动员,因此需要进一步筛选项目为“篮球”的数据。 # 筛选出项目为篮球的数据 basketball_data = all_data[all_data['项目']=='篮球']运行结果部分数据如下: 发现“出生日期”这一列没有缺失值,但包含“X年X月X日”、“X年X月”、“X年”和“X”等多种类型的数据。 为保证“出生日期”一列数据的一致性,这里统一将数据修改为“X年”格式,代码如下(虽然要素过多,但研究了半小时后我顿悟了,所以不要直接放弃,加油!): import datetime # ?????这句我不懂 basketball_data=basketball_data.copy() # 将以“X”显示的日期转换成以“X年X月X日”形式显示的日期 # 小白碎碎念:这里的数字值“X”,比如32599、33757等,指的是与1900年1月1日相差的天数,这一句里的第一个datetime是模块名,第二个datetime是里面的对象,strptime是方法名,意为将基准日期转换为年月日的形式 initial_time=datetime.datetime.strptime('1900-01-01','%Y-%M-%d') # 访问“出生日期”一列的数据 # 小白碎碎念:这个冒号很玄妙,loc[行号, 列号],行号这里的冒号代表全部,列号这里指定了“出生日期”,因此basketball_data.loc[:,'出生日期']取到的是“出生日期”这一列中的所有行的数据 for i in basketball_data.loc[:,'出生日期']: # 只处理纯五位数字的日期,其他X年X月类似文本日期都跳过 if type(i)==int: # 基准日期加上偏移天数,再转换为XXXX年XX月XX日的形式,这里必须是大写的Y,如果小写的话输出格式会变成XX年,后面的.format是格式化输出,花括号里的y,m,d都是占位置用的,实际值是format中的值 new_time=(initial_time+datetime.timedelta(days=i)).strftime('%Y{y}%m{m}%d{d}').format(y='年',m='月',d='日') # 调用replace函数,将原来的数字替换为转换好的新日期 basketball_data.loc[:,'出生日期']=basketball_data.loc[:,'出生日期'].replace(i,new_time) # 为保证出生日期的一致性,这里统一使用只保留到年份的日期,lambda是一个特殊函数,x[:5]意为取前5个字符,即XXXX年 basketball_data.loc[:,'出生日期']=basketball_data['出生日期'].apply(lambda x:x[:5]) # 展示前10条出生日期数据 basketball_data['出生日期'].head(10)检验出生日期格式转换结果,运行如下: ②处理“身高”列的缺失值 “身高”一列存在多个缺失值,建议用填充缺失值——统计方法填充。由于男篮和女篮运动员体质不同,所以这里需要先以“性别”做区分,男性缺失值用男性的平均值填充,女性缺失值用女性的平均值填充。 此处要素过多,待研究。 # 筛选男篮运动员数据 # male_data=basketball_data[basketball_data['性别']=='男'] # 疑问1:为何要用lambda? male_data=basketball_data[basketball_data['性别'].apply(lambda x:x=='男')] # 疑问2:为什么要拷贝一下这个对象?用它本身不可以吗? male_data=male_data.copy() # 计算身高平均值(四舍五入取整) # 小白解读:计算平均身高前,要先删掉空值数 male_height=male_data['身高'].dropna() # 小白解读:round方法是四舍五入,astype(int)是类型转换,mean()是求平均数 fill_male_height=round(male_height.apply(lambda x:x[0:-2]).astype(int).mean()) # 小白解读:上一步求出来的是小数,先强制转化成int整数,再转换成字符串型,才能在最后加上同为字符串类型的“厘米”单位 fill_male_height = str(int(fill_male_height))+'厘米' # 填充缺失值 # 小白解读:将“身高”一列中,所有的缺失值都填充为男性身高平均值 male_data.loc[:,'身高']=male_data.loc[:,'身高'].fillna(fill_male_height) # 为方便后期使用,这里将身高数据转换为整数 male_data.loc[:,'身高']=male_data.loc[:,'身高'].apply(lambda x:x[0:-2]).astype(int) # 重命名列标签引用 male_data.rename(columns={'身高':'身高/cm'},inplace=True) male_data接下来处理女篮数据 import numpy # 筛选女篮运动员数据 female_data=basketball_data[basketball_data['性别'].apply(lambda x:x=='女')] female_data=female_data.copy() # 由于身高数据格式差异大,也没有现成工具,所以只能用字典手动处理 data={'191cm':'191厘米', '1米89公分':'189厘米','2.01米':'201厘米','187公分':'187厘米','1.97M':'197厘米','1.98米':'198厘米','192cm':'192厘米'} female_data.loc[:,'身高']=female_data.loc[:,'身高'].replace(data) # 计算女篮运动员平均身高 female_height=female_data['身高'].dropna() fill_female_height=round(female_height.apply(lambda x:x[0:-2]).astype(int).mean()) # 强制转换成整数,再转换成字符串,最后加上单位“厘米” fill_female_height=str(int(fill_female_height))+'厘米' # 填充缺失值 female_data.loc[:,'身高']=female_data.loc[:,'身高'].fillna(fill_female_height) # 为方便后期使用,这里将身高数据转换为整数 female_data['身高']=female_data['身高'].apply(lambda x:x[0:-2]).astype(int) # 重命名列标签索引 female_data.rename(columns={'身高':'身高/cm'},inplace=True) female_data
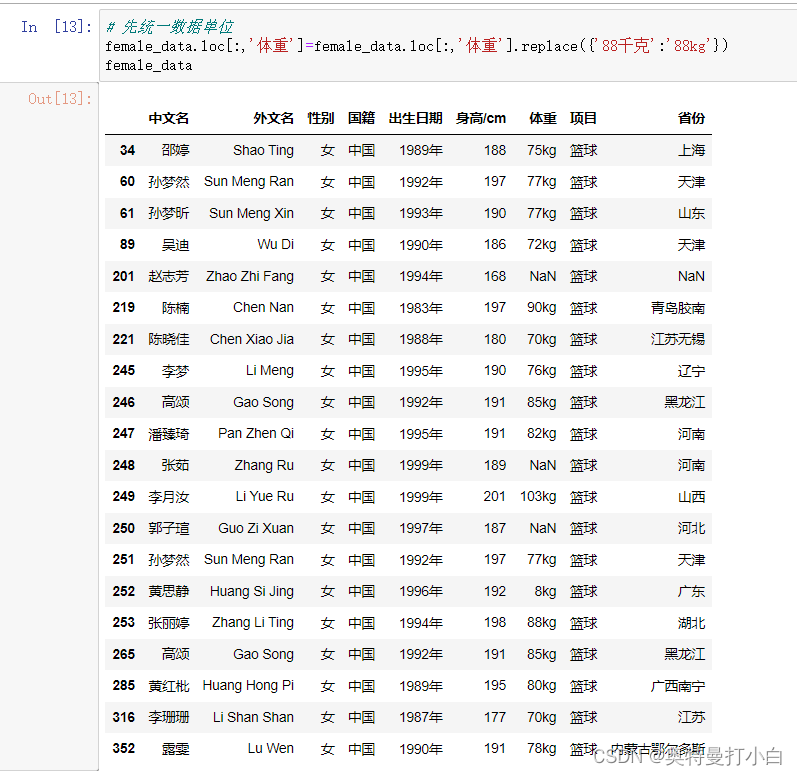
③处理“体重”列的缺失值 观察前面两次的输出结果,发现女篮运动员数据中“体重”一列存在缺失值,且该列中行索引为253的数据与其他行数据的单位不统一。 因此,这里先替换行索引为253的数据使之与其他数据具有相同的单位,代码如下: # 先统一数据单位 female_data.loc[:,'体重']=female_data.loc[:,'体重'].replace({'88千克':'88kg'}) female_data
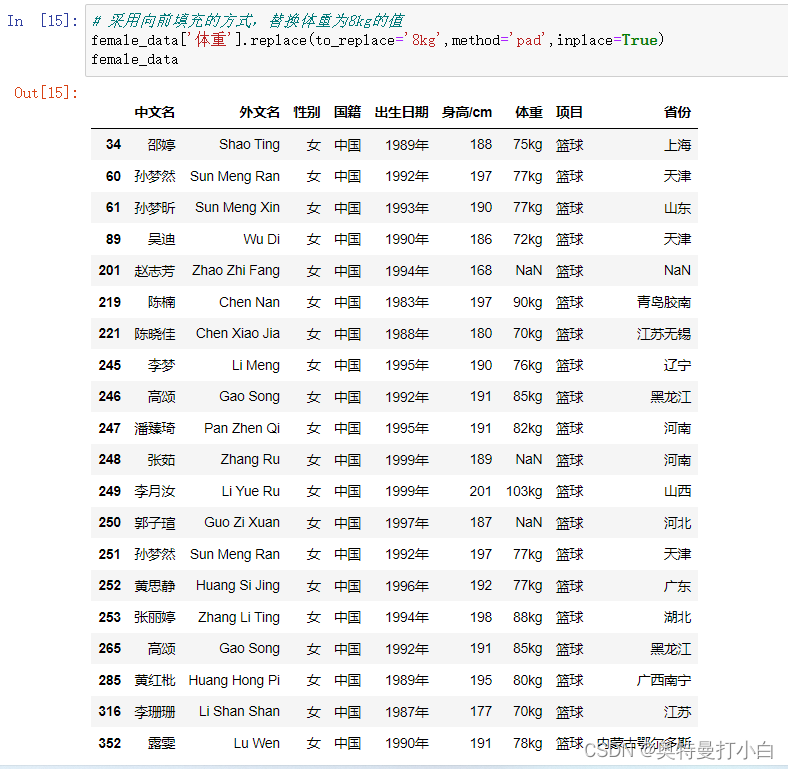
对比可知,248和250行的缺失数据已填充成功。 体重列缺失值处理完后的完整数据如下图所示: 为提高后期计算的准确性,需要对整租数据做异常值检测,这里通过箱型图和3σ原则两种方式分别检测“身高/cm”和“体重/kg”两列数据。 使用箱型图检测男篮运动员的身高数据 from matplotlib import pyplot as plt # 设置中文显示 plt.rcParams['font.sans-serif']=['SimHei'] # 使用箱型图检测男篮运动员“身高/cm”一列是否有异常值 male_data.boxplot(column=['身高/cm']) plt.show()
|
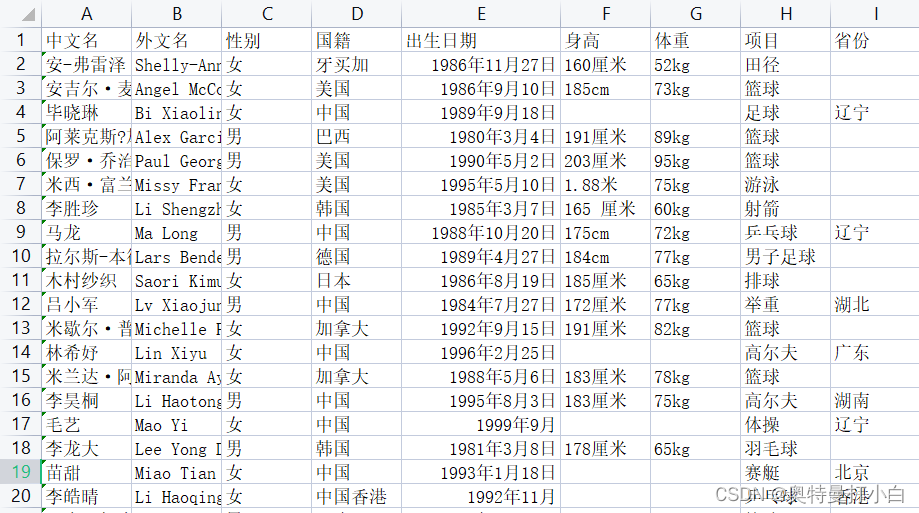 运动员信息采集02.xlsx
运动员信息采集02.xlsx 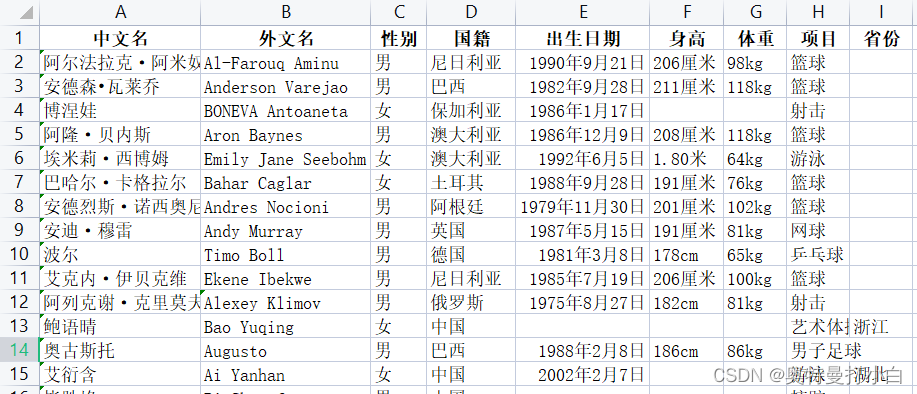
 一堆布尔值,所以,我想要的应该是all_data中,布尔值为True的那些数据。 完整代码如下:
一堆布尔值,所以,我想要的应该是all_data中,布尔值为True的那些数据。 完整代码如下: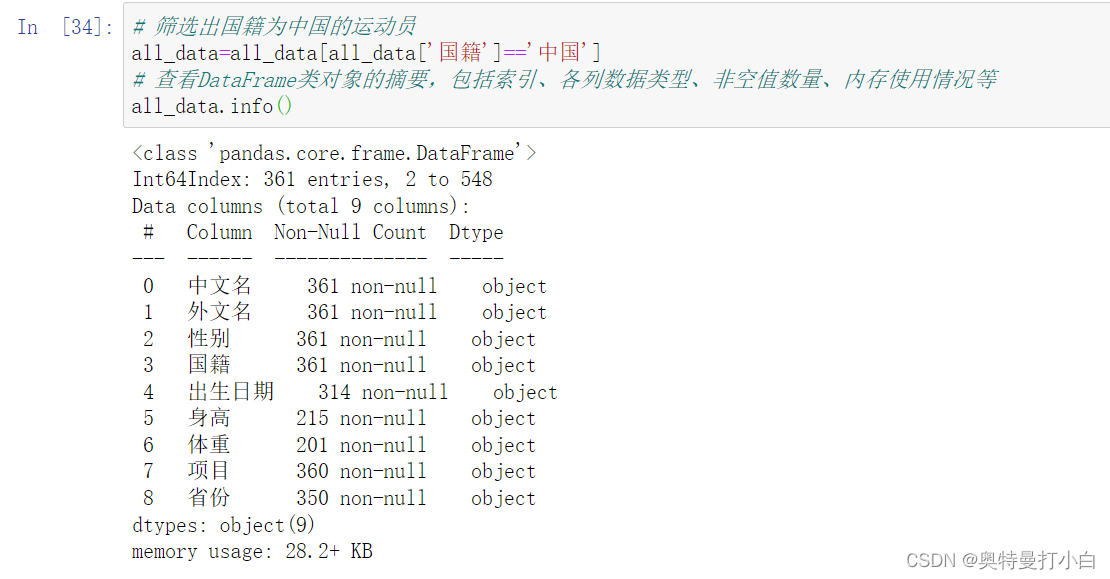 观察输出结果可知,数据中后5列的非空值数量不等,说明可能存在缺失值、重复值等;所有列的数据类型均为Object型,因此后续需要先对部分列进行数据类型转换操作,之后才能计算要求的统计指标。 进入下一步,数据清理。
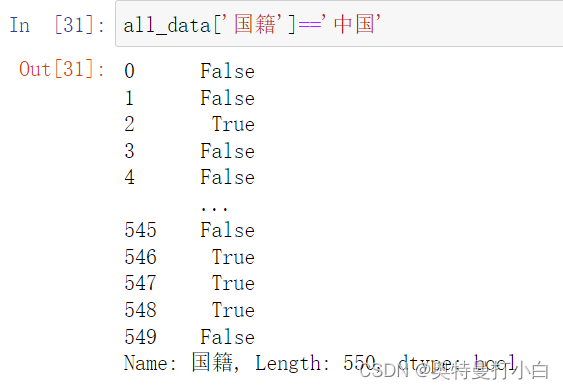
观察输出结果可知,数据中后5列的非空值数量不等,说明可能存在缺失值、重复值等;所有列的数据类型均为Object型,因此后续需要先对部分列进行数据类型转换操作,之后才能计算要求的统计指标。 进入下一步,数据清理。 如图,执行all_data.duplicated()方法只能拿到一堆布尔值,True代表重复,False代表没重复,要想看到里面到底有哪些重复值,需要筛选all_data中检测值为True的项。
如图,执行all_data.duplicated()方法只能拿到一堆布尔值,True代表重复,False代表没重复,要想看到里面到底有哪些重复值,需要筛选all_data中检测值为True的项。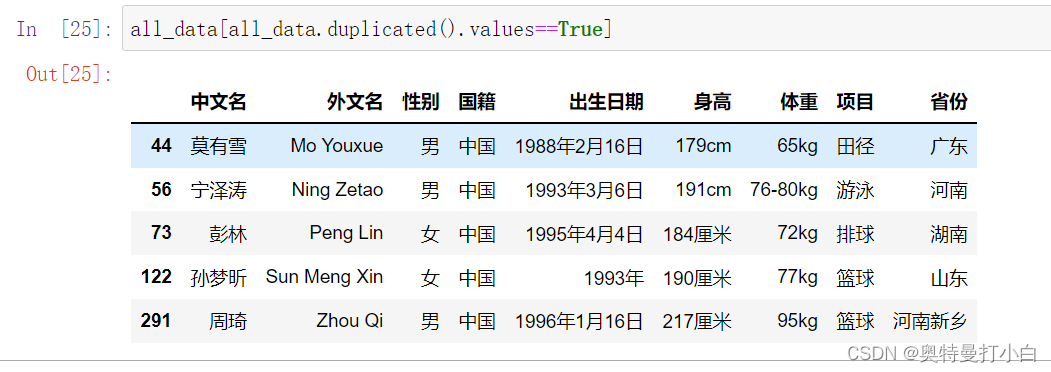 调用drop_duplicates()方法删除重复值,ignore_index参数设置为True,删除重复值后重新设置索引,代码如下:
调用drop_duplicates()方法删除重复值,ignore_index参数设置为True,删除重复值后重新设置索引,代码如下: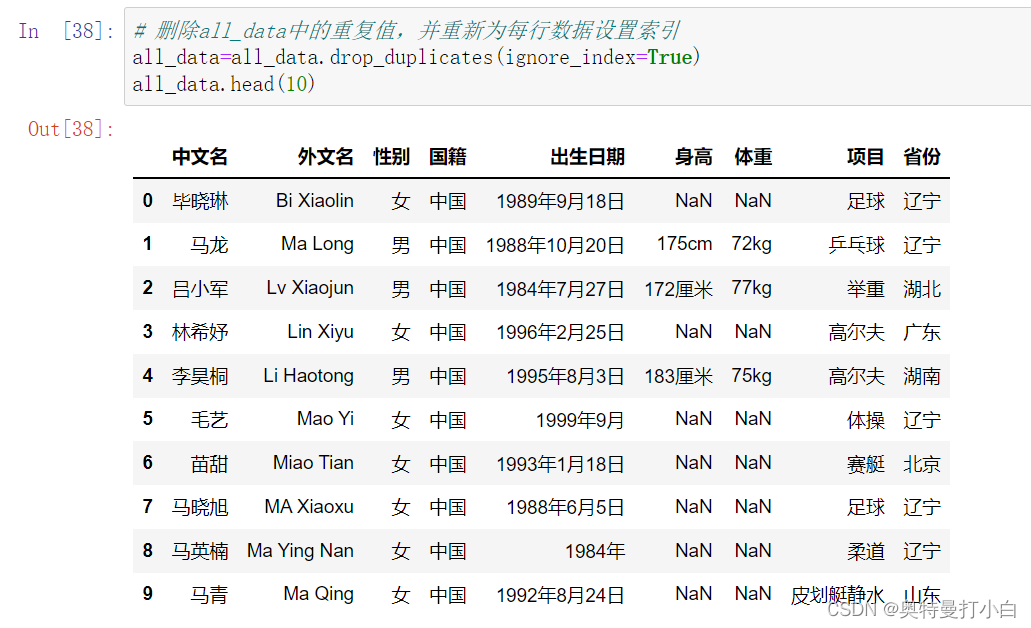
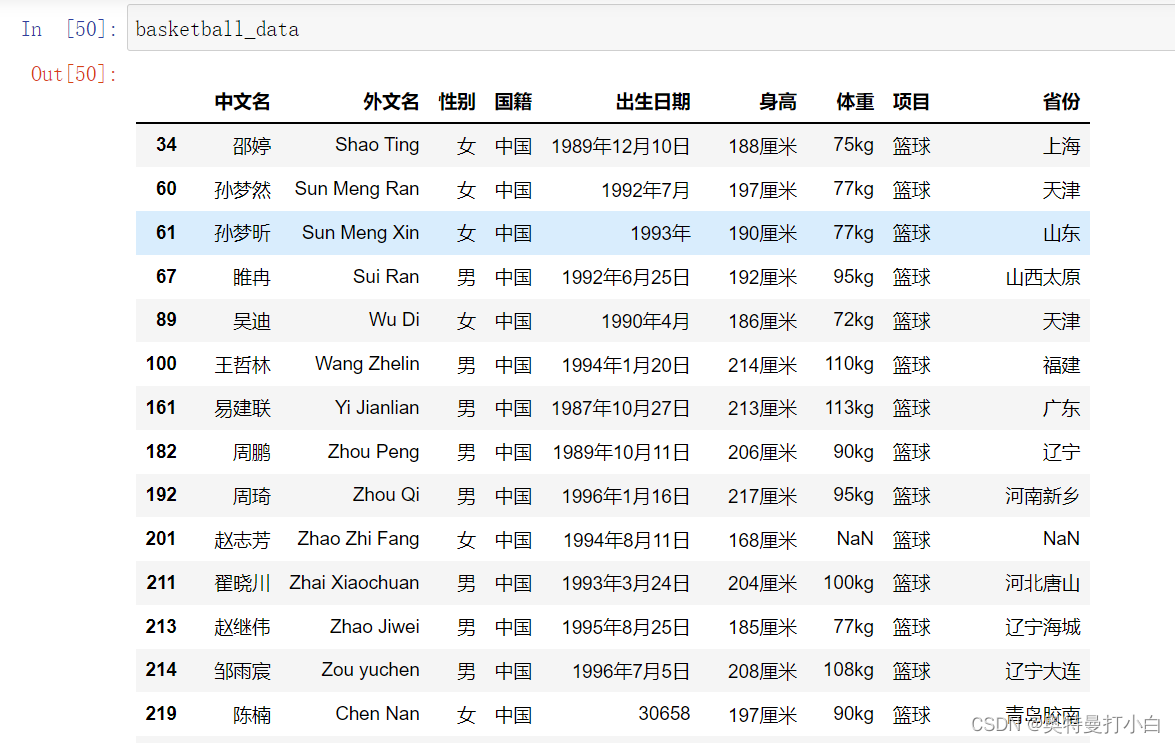 ①处理“出生日期”列的缺失值 单独查看“出生日期”列的数据,看是否有缺失?
①处理“出生日期”列的缺失值 单独查看“出生日期”列的数据,看是否有缺失? 到此出生日期转换完毕。
到此出生日期转换完毕。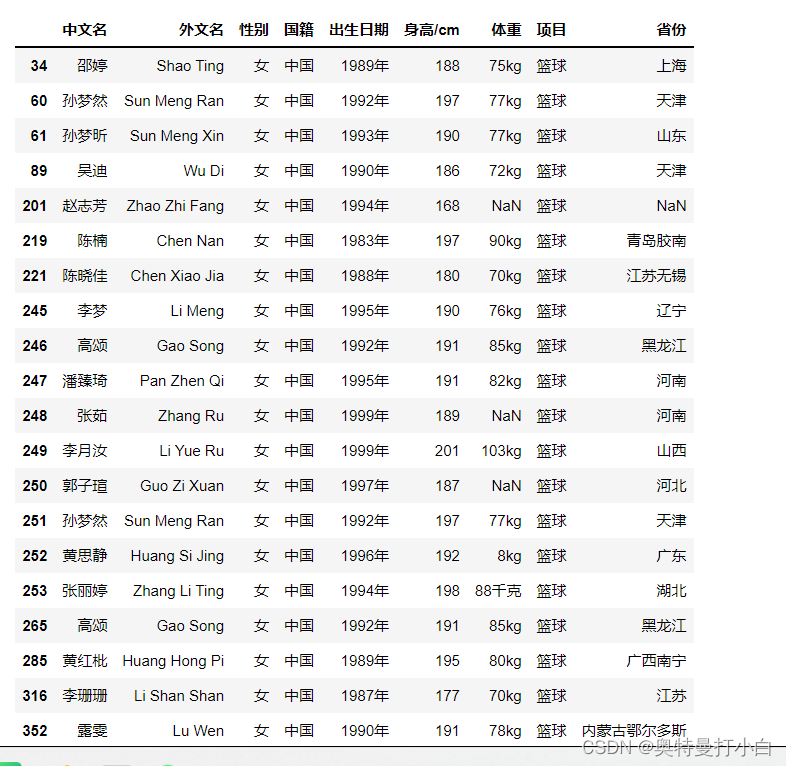
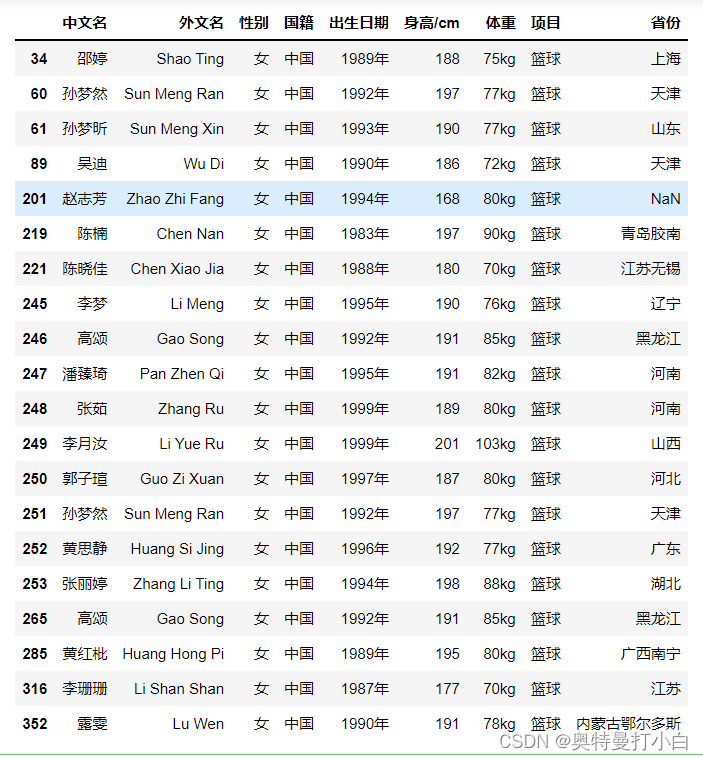
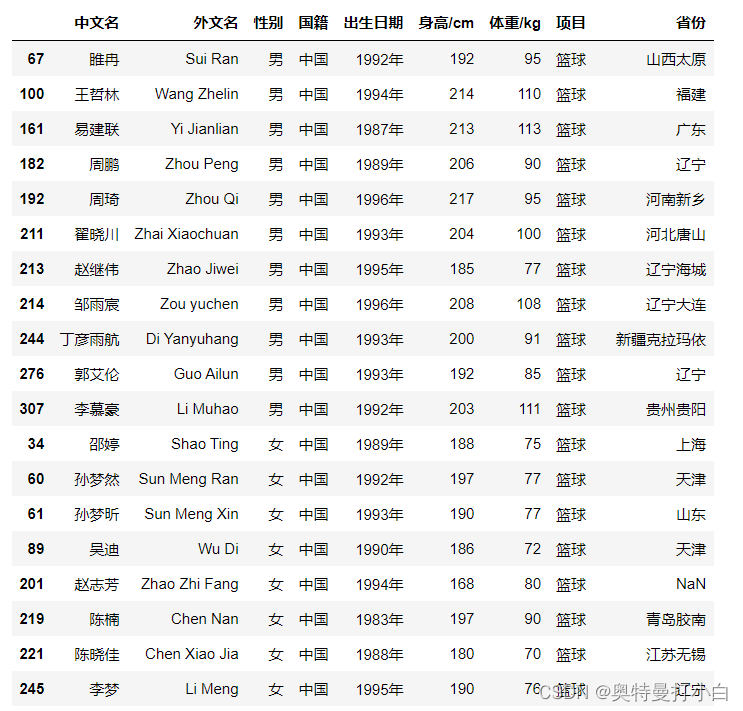
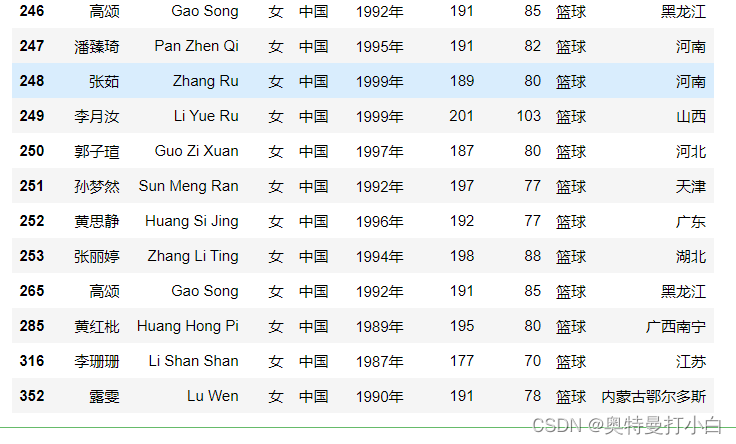
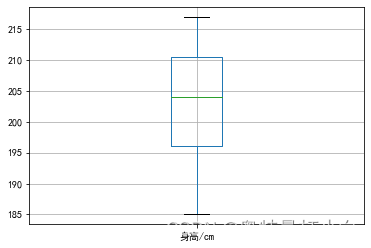
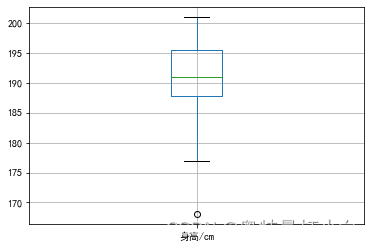 观察以上两个箱型图可知,女篮运动员的身高数据中存在一个小于170的值,经核实后确认该值为非异常值,可直接忽略。
观察以上两个箱型图可知,女篮运动员的身高数据中存在一个小于170的值,经核实后确认该值为非异常值,可直接忽略。【本文地址】