|
目录
1.任务要求
2.网络爬虫实现原理
3.系统设计与代码实现
3.1 第一题
3.1.1 最初设计方案:采用request+BeautifulSoup 方式
3.1.2 更改后的设计方案:采用request直接获取json格式的html信息。
3.2 第二题
3.2.1 流程图
3.2.1 代码
3.3 第三题
3.3.1 流程图
3.3.2 代码
4.运行结果
4.1 第一题
4.2 第二题
4.3 第三题
5.结果评价
6.不足和改进之处
1.任务要求
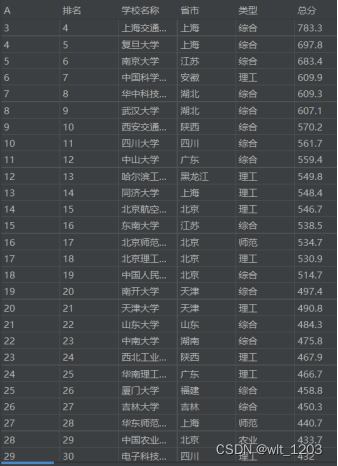
访问网址https://www.shanghairanking.cn/rankings,爬取排行榜数据,分析按区域的大学数量排行,得出有效结论。
爬取主榜数据并保存在文件中。分析每个地区上榜大学的数量,保存在文件中。分析前十名的地区的大学数量,绘制柱状图。说明爬虫爬取过程中可能涉及到的社会、健康、安全、法律以及文化问题,并并评价和说明分析结果对于社会、健康、安全、法律以及文化的影响,符合道德和社会公共利益,理解应承担的责任。
注:本题60分。
2.网络爬虫实现原理

3.系统设计与代码实现
3.1 第一题
3.1.1 最初设计方案:采用request+BeautifulSoup 方式

代码如下:
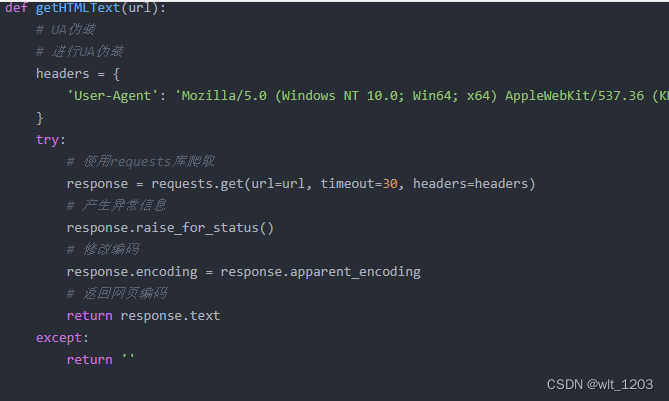
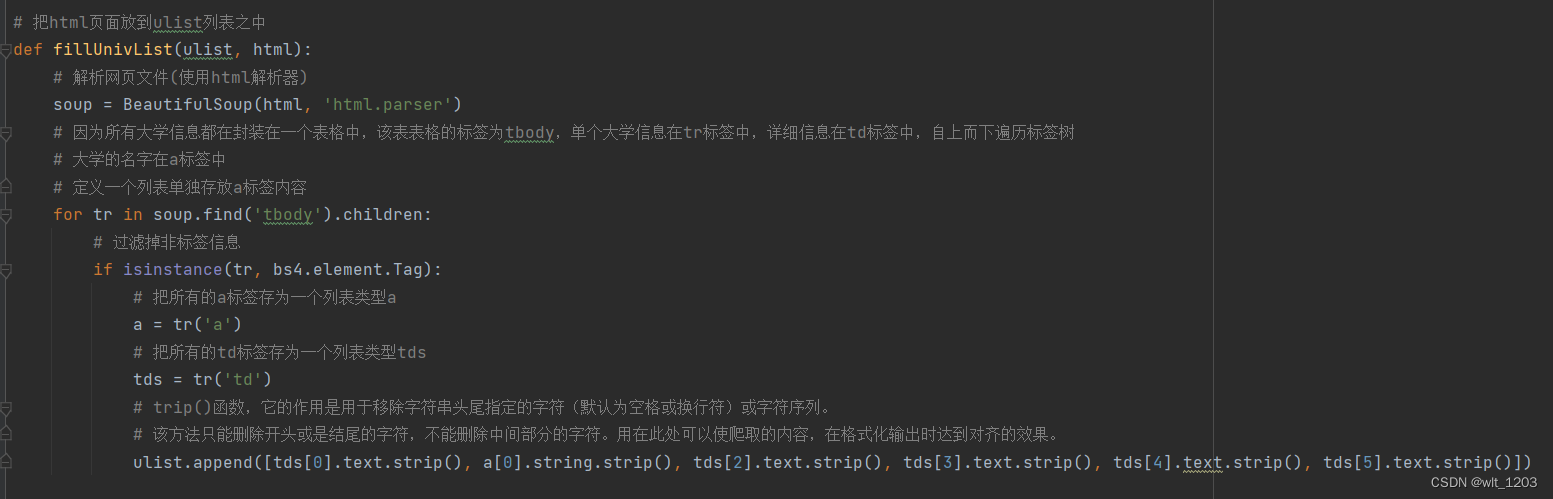
3.1.2 更改后的设计方案:采用request直接获取json格式的html信息。
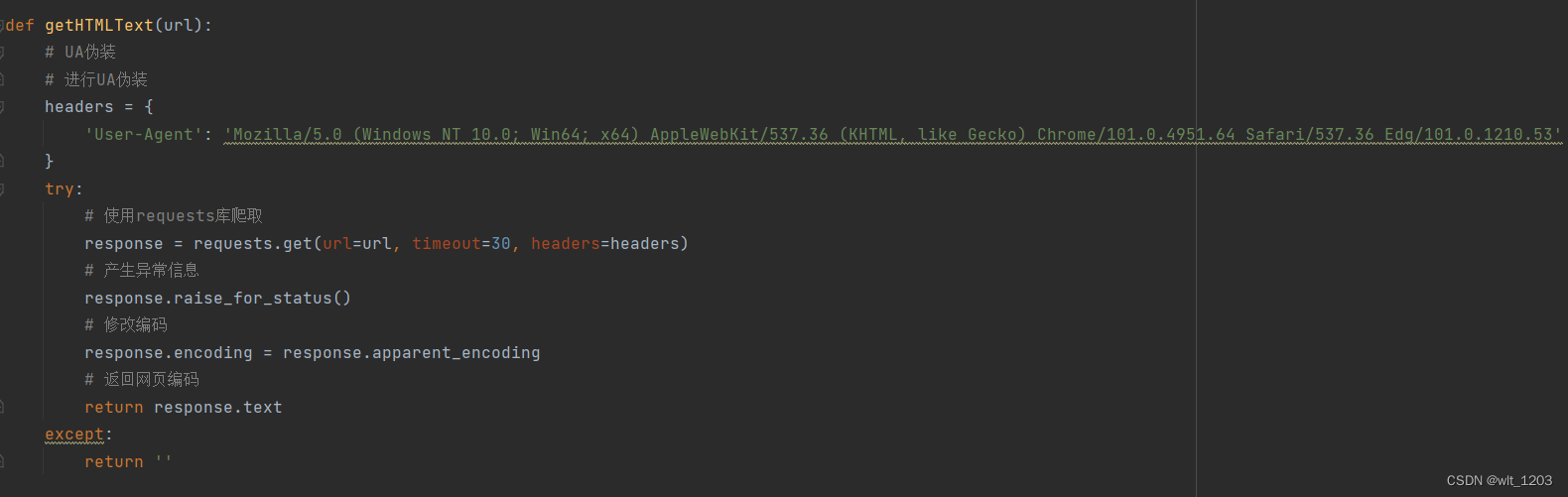
从网络上获取大学排名网页内容 getHTMLText(),先进行UA伪装,随后用requests库爬取获取网页编码。
最后遍历将将内容存储到ulist列表中。
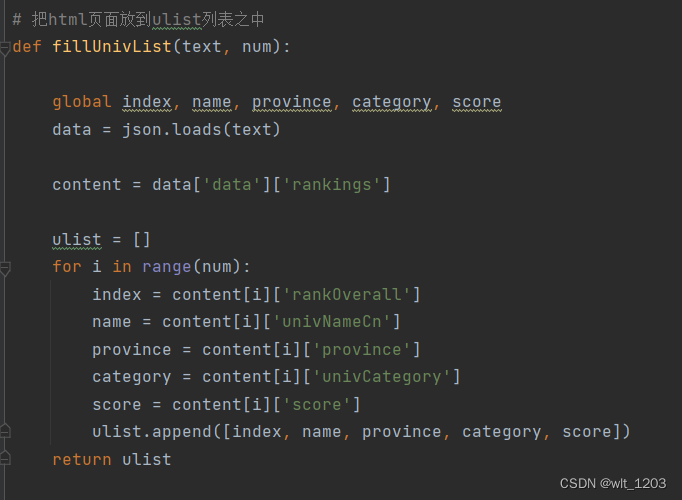
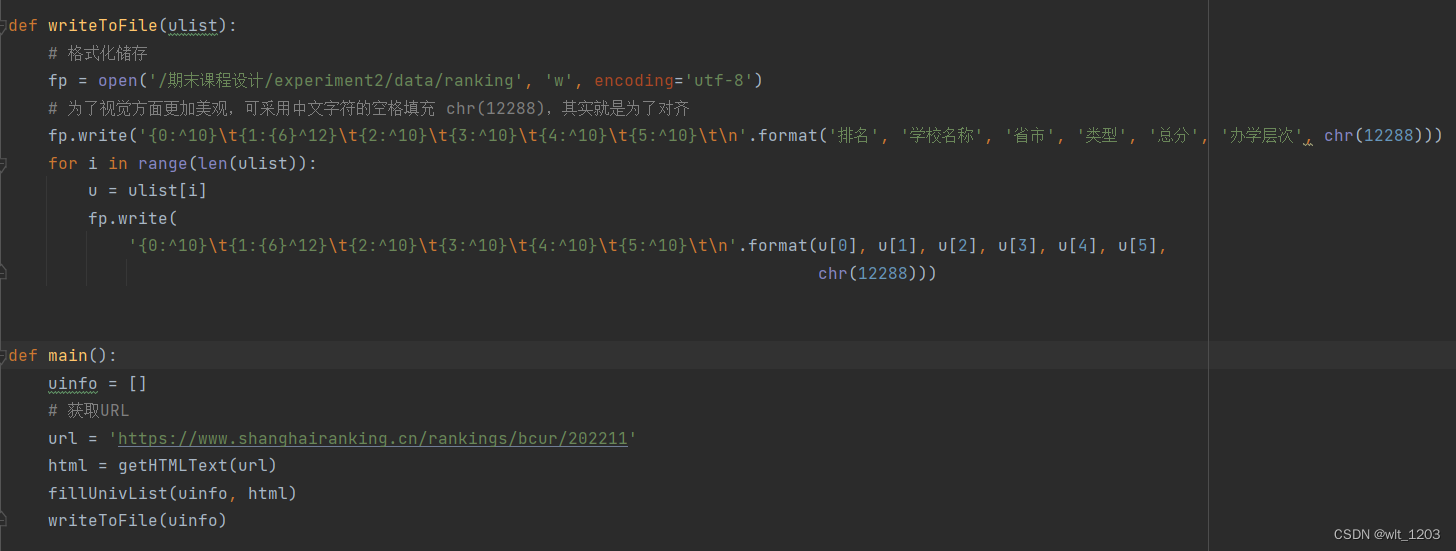
.利用数据结构将结果储存到文件之中WriteToFile(),利用DataFrame存储为.xlsx文件
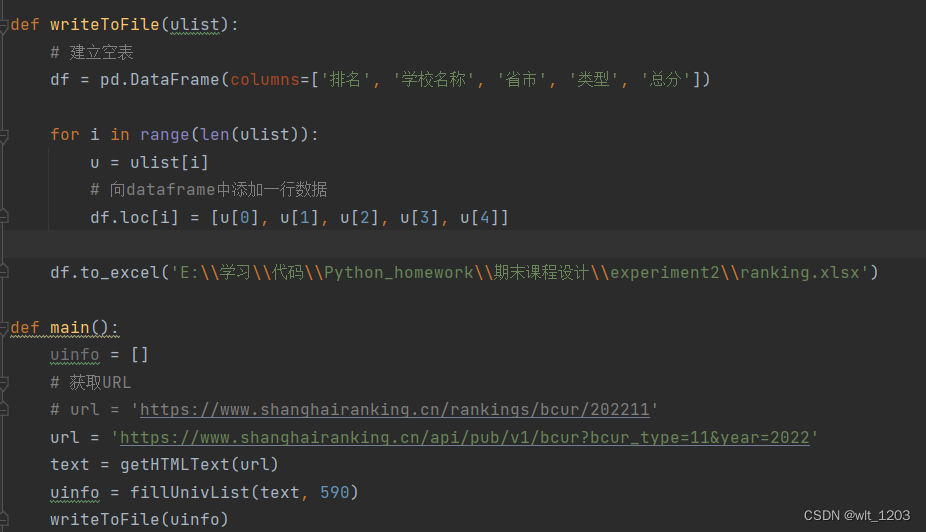
3.2 第二题
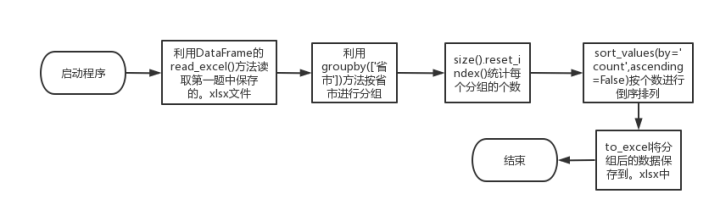
3.2.1 流程图
3.2.1 代码
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
# (2)分析每个地区上榜大学的数量,保存在文件中。
ranking = pd.read_excel('E:\\学习\\代码\\Python_homework\\期末课程设计\\experiment2\\ranking.xlsx')
r_group = ranking.groupby(['省市'])
r = r_group.size().reset_index()
new_col = ['province', 'count']
r.columns = new_col
# print(r)
df = r.sort_values(by='count', ascending=False)
df.to_excel('E:\\学习\\代码\\Python_homework\\期末课程设计\\experiment2\\regionalRanking.xlsx')
3.3 第三题
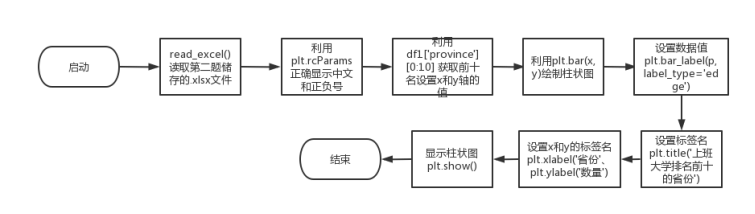
3.3.1 流程图
3.3.2 代码
# (3)分析前十名的地区的大学数量,绘制柱状图。
df1 = pd.read_excel('E:\\学习\\代码\\Python_homework\\期末课程设计\\experiment2\\regionalRanking.xlsx')
# 正确显示中文和负号
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置x和y轴的值
x = df1['province'][0:10]
y = df1['count'][0:10]
# 绘制柱状图
p = plt.bar(x, y)
# 设置标签值
plt.bar_label(p, label_type='edge')
# 标题名
plt.title('上榜大学排名前十的省份')
# x轴标签名
plt.xlabel('省份')
# y轴标签名
plt.ylabel('数量')
# 显示柱状图
plt.show()
4.运行结果
4.1 第一题
4.2 第二题
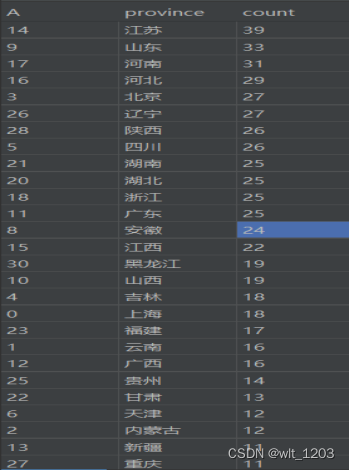
4.3 第三题
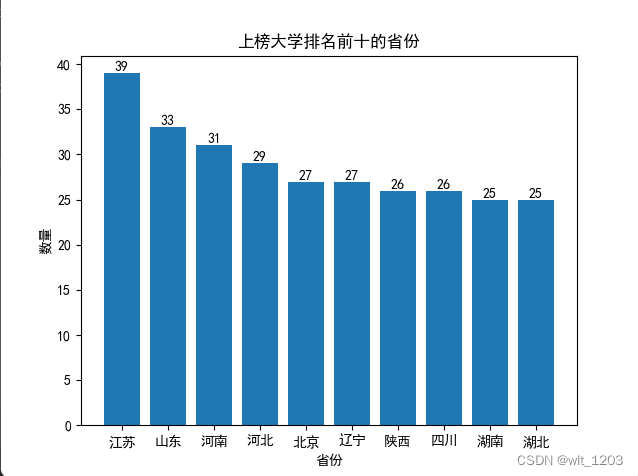
由得出的柱状图可以得出,高校数量排行前十名的省份,其中绝大多数是人口和经济大省,除了北京作为我国的首都,但是他是我国的政治和文化中心,这就很正常了。
5.结果评价

6.不足和改进之处

|