Python爬虫入门之2022软科中国大学排名爬取保存到csv文件 |
您所在的位置:网站首页 › 中国10大大将排名表格 › Python爬虫入门之2022软科中国大学排名爬取保存到csv文件 |
Python爬虫入门之2022软科中国大学排名爬取保存到csv文件
|
一、实验方案设计
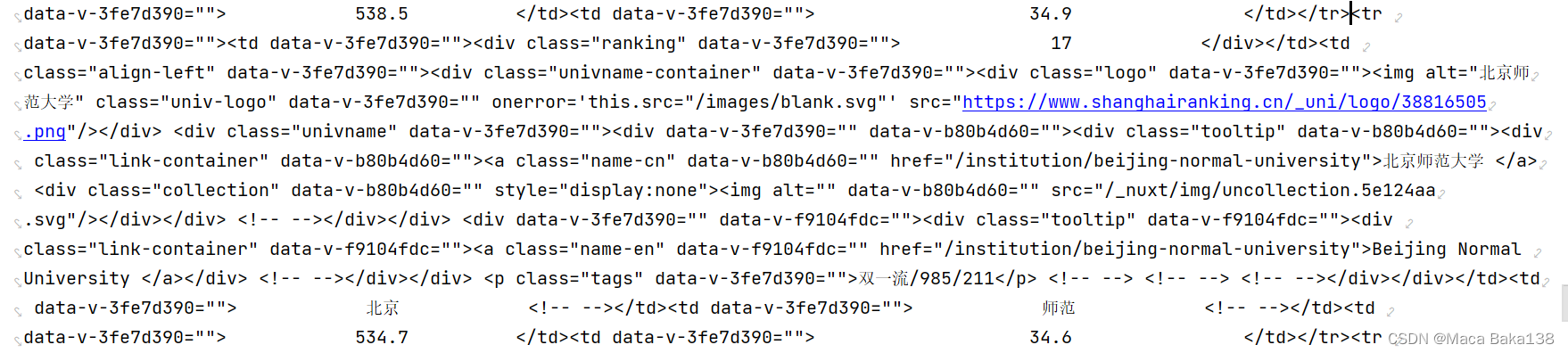
1、获得“2022软科中国大学排名”数据,从【软科排名】2022年最新软科中国大学排名|中国最好大学排名网页中获得排名数据信息,并将数据保存到csv文件中。 2、调用两个CSV文件,将他们合成一个文件,并按排名先后对其进行排序 3、将合并文件储存为txt文件和json文件 二、实验过程记录 1、获得“2022软科中国大学排名”数据我们采用爬虫的方式在网站上进行数据收集,首先导入实验所需的包 import requests import re from bs4 import BeautifulSoup import pandas as pd import time下面进行数据收集操作,定义相关函数: getHTMLText(url)该函数用来获取网页源代码,参数为网站链接,Timeout设置为30,解码方式为'utf-8'。 函数代码如下: 如果出现错误则返回空值,不会报错中断程序运行。 def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = 'utf-8' return r.text except: return ""观察网页HTML发现,我们需要的每条学校信息在标签之间,学校的每条属性在之间,下面是以北京师范大学为例的展示:
因此我们从HTML文件中获取学校信息,其中参数为源代码的HTML解析 def fillUnivList(soup): data = soup.find_all('tr') for tr in data: ltd = tr.find_all('td') if len(ltd)==0: continue singleUniv = [] for td in ltd: STR = td.find_all(string=re.compile(".")) singleUniv.append(STR) singleUniv.append(td.string) allUniv.append(singleUniv)将获取的每条数据放入我们建立的数组中。 获得数的数组后,我们定义函数所需的数据写入csv文件,writeUnivList(num,num1)其中参数是获取大学的排名,例如我们写(0,10)就是找1-10的大学信息,写入csv中,我们选取了排名,名称,属性等7个属性值作为CSV输出。当然也可以根据需要选择重要属性,其中我们就忽略了学校英文名称的信息。 def writeUnivList(num,num1): result = {"排名": [], "学校名称": [], "评价": [], # 985/211/双一流 "省市": [], "类型": [], # 理工/综合/师范/农业 "总分": [], "培养规模": [] } for i in range(num,num1): u=allUniv[i] rank = u[1].replace(' ', '') name = u[2][1].replace(' ', '') value = u[2][10].replace(' ', '') city = u[4][0].replace(' ', '') type = u[6][0].replace(' ', '') score = u[8][0].replace(' ', '') scale = u[10][0].replace(' ', '') result["排名"].append(rank) result["学校名称"].append(name) result["评价"].append(value) result["省市"].append(city) result["类型"].append(type) result["总分"].append(score) result["培养规模"].append(scale) return result最后通过主函数对上面的函数进行调用返回DataFrame后的数据,同时我们也将源代码中的回车和空格进行的删除。 def main(num,num1): url = 'https://www.shanghairanking.cn/rankings/bcur/2022' html = getHTMLText(url).replace('\n', '').replace(u'\xa0', '') soup = BeautifulSoup(html, "html.parser") fillUnivList(soup) df = pd.DataFrame(writeUnivList(num,num1)) return df分别写入Univrank1-10.csv文件和Univrank11-20.csv文件,同时调用进度条函数增加输出的可视化。 def Bar(): scale = 50 print("执行开始".center(scale // 2, '-')) #t = time.perf_counter() for i in range(scale + 1): a = '*' * i b = '.' * (scale - i) c = (i / scale) * 100 #t -= time.perf_counter() print("\r{:^3.0f}% [{} -> {}] ".format(c, a, b), end=' ') time.sleep(0.02) #print("\n" + "执行结束".center(scale // 2, '-')) Bar() #main(0,10).to_csv("Univrank1-10.csv", index=False,encoding="utf_8_sig") main(20,30).to_csv("Univrank30-40.csv", index=False,encoding="utf_8_sig") print("\n文件写入成功!!!") print("执行结束".center(50 // 2, '-')) 2、合并两个文件 import pandas as pd r1= pd.read_csv('Univrank1-10.csv', encoding='utf-8') # 文件1 r2= pd.read_csv('Univrank11-20.csv',encoding='utf-8') # 文件2 def Combition(r1,r2): df = pd.concat([r1, r2]) df.drop_duplicates() # 数据去重 df = df.sort_values(axis=0, by="排名", ascending=True) #排名升序排列 #df = df.sort_values(axis=0, by="总分", ascending=False)#按总分降序排列 return df # r1.to_csv('Univrank.csv', index=False, header=True) # 第一个csv文件保留表头 # r2.to_csv('Univrank.csv', index=False, header=False, mode='a+') # 第2个csv文件不保留表头,追加到合并文件后面 Combition(r1,r2).to_csv('Univrank.csv',index=False, encoding="utf_8_sig")将两个文件打开,定义一个Combition(r1,r2)函数,参数为需要合并的两个文件,利用concat()合并后,进行sort排序,可以用排名的升序或者总分的降序进行排列。 3、转存为txt文件将csv文件写入txt有多种方式1)可以直接进行格式转换2)一行一行写入3)一个一个写入,为保证写入文件的整齐,我们采用一个一个写入的方式,由于中文字符不能直接利用center或者ljust进行对其,在尝试多种方法后我们定义一个函数用来中文格式化对齐: import os def duiqi(string,length): difference = length - len(string) # 计算限定长度时需要补齐多少个空格 if difference == 0: # 若差值为0则不需要补 return string elif difference < 0: print('错误:限定的对齐长度小于字符串长度!') return None new_string = '' space = ' ' for i in string: codes = ord(i) # 将字符转为ASCII或UNICODE编码 if codes |
【本文地址】
今日新闻 |
推荐新闻 |