数据分析(jupyter lab版):柱状图 |
您所在的位置:网站首页 › 两组数据怎么做柱形图分析 › 数据分析(jupyter lab版):柱状图 |
数据分析(jupyter lab版):柱状图
|
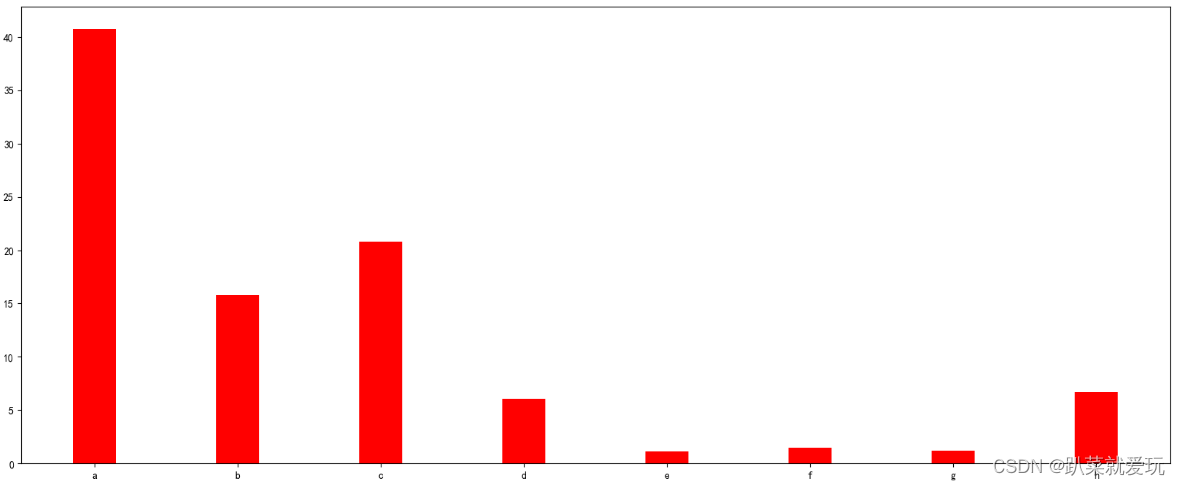
柱状图利用柱子的高度,反映数据的差异。肉眼对高度差异很敏感,辨识效果非常好。柱状图的局限在于只适用中小规模的数据集。 柱状图主要分为两种:普通柱状图、横向柱状图,分组柱状图和堆叠柱状图 丰富图表见(数据分析(jupyter lab版:丰富图表)) 普通柱状图
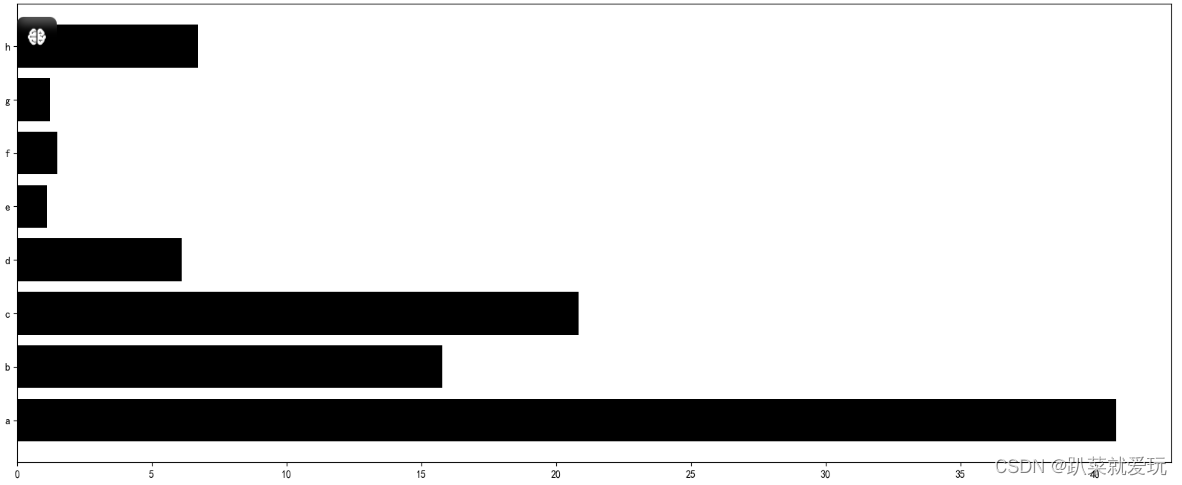
横向柱状图
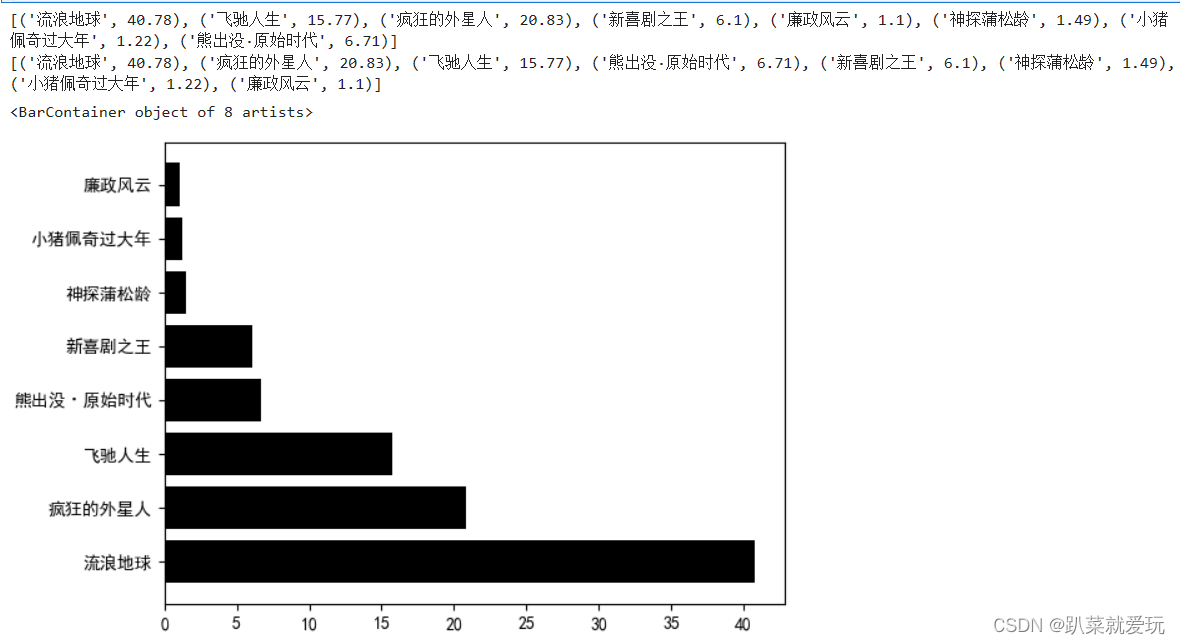
为了将图表显示的更为明显,所以我们可以对横向柱状图的柱体进行排序操作。这项操作可以对各个部分的图表进行使用。 代码进行排序,排序的依据是元素的第二个值(索引为1的值),并且以降序(reverse=True)的方式进行排序。具体来说,lambda函数a: a[1]表示对每个元素a,取其索引为1的值作为排序的依据。在这里,代码的索引是指以第一个print打印的列表为依据,将列表的每一项元素的数字取出进行降序排列。
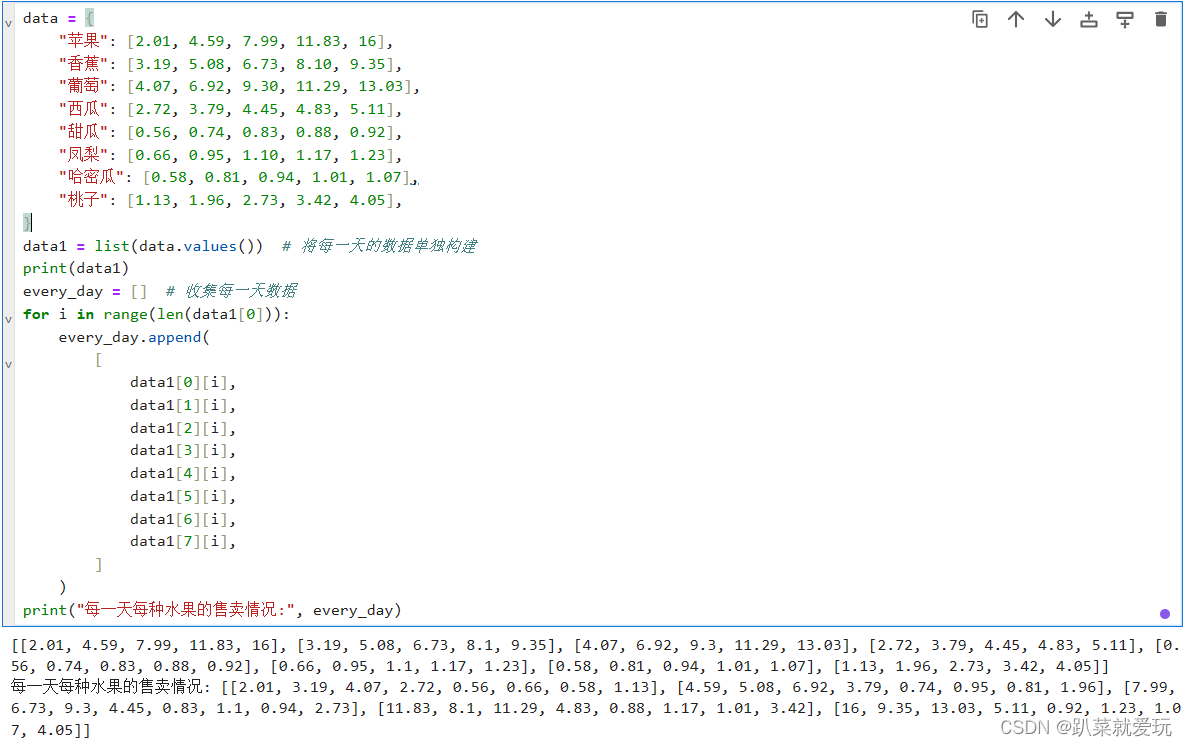
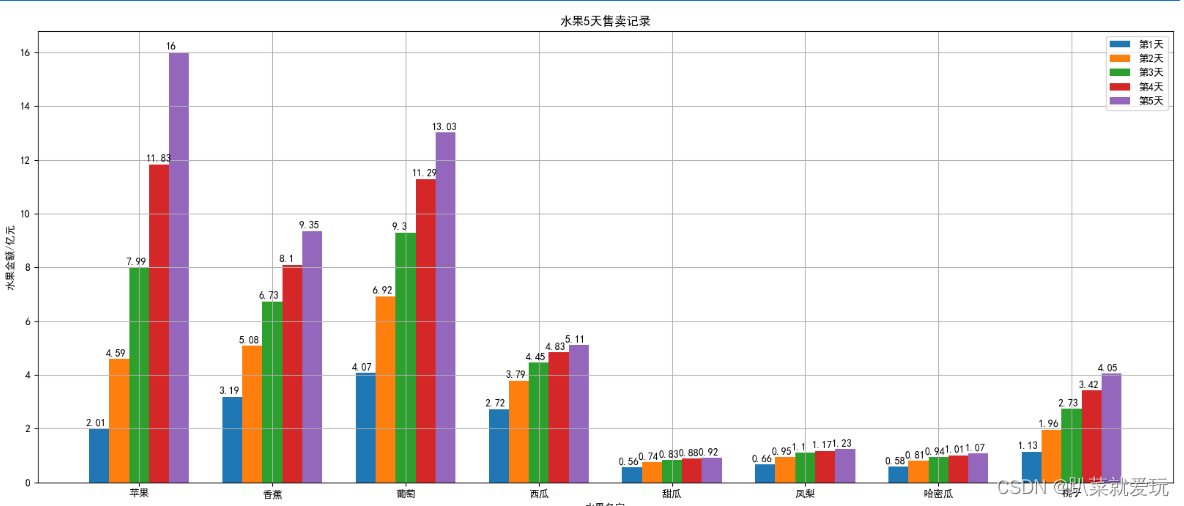
分组柱状图 分组柱状图,又叫聚合柱状图。当使用者需要在同一个轴上显示各个分类下不同的分组时,需要用到分组柱状图。分组柱状图将单个或多个数据集的柱形彼此并排显示,适合不同类别的数据对比,或者将大类别中各个小类别同时进行对比。 这里我们引用五天时间的水果的售卖情况数据。 在每次进行数据分析时,我们都要先思考哪些数据做x轴,哪些数据做y轴,这样便于我们后面的代码书写。
for money, x in zip(day_money, xs): plt.annotate(money, xy=(x, money), xytext=(x - 0.1, money + 0.1)) 这段代码是用来在图表中添加数据标签的。通过将每个数据点的金额和对应的x坐标传入zip()函数,然后使用plt.annotate()函数在图表中添加标签。具体来说,xy参数指定了标签的位置,xytext参数指定了标签文本的位置偏移量,偏移量是指每一根柱子上的数字的位置改变,这样就可以在图表中显示每个数据点的具体数值。 什么是zip()函数呢?zip函数是Python内置函数之一,用于将多个可迭代对象(如列表、元组等)中对应位置的元素打包成一个元组,并返回一个zip对象。这个zip对象可以进一步转换为列表、元组等数据结构,或者用于迭代操作。 所以,zip(day_money, xs)实际上就是将 day_money 和 xs 中对应位置的元素打包成元组的形式,以(day_money, xs)元组的形式用于后续的操作。
堆叠柱状图 堆叠柱状图非常适合用来对比不同类别数据的数值大小,同时对比每一类别数据中,子类别的构成及大小。
如果需要继续往上堆叠,只需要在以上代码中的继续添加+group3[i],就可以实现四个堆叠,以此类推即可。
|




【本文地址】
今日新闻 |
推荐新闻 |