python实现两个Excel表格数据对比、补充、交叉验证 |
您所在的位置:网站首页 › 两个表格数据匹配 › python实现两个Excel表格数据对比、补充、交叉验证 |
python实现两个Excel表格数据对比、补充、交叉验证
|
业务背景
业务中需要用到类似企查查一类的数据平台进行数据导出,但企查查数据不一定精准,所以想采用另一个官方数据平台进行数据对比核验,企查查数据缺少的则补充,数据一致的保留企查查数据,不一致的进行颜色标注。 实现逻辑经过调研,python可以实现表格的合并及数据处理,完成表格的合并及数据对比、数据补充、数据交叉验证。 首先将表格A数据和表格B数据交叉排列,奇数位为表格A的数据,偶数位为表格B数据,每两行为同一公司主体,进行上下数据对比,上一行数据没有的下一行补充,上下两行都有数据就进行对比,相同的不做处理,不同的标注颜色,并把表格B的数据放到大括号中拼接到表格A数据之后,最后删除偶数行的所有数据。 实现效果表格A
表格B
合成后效果:
下载地址:Python Releases for Windows | Python.org 下载时,注意选择自定义下载,并勾选添加路径,如下图:
下载安装完成后,按window+R键输入cmd打开命令行工具,输入python显示python版本即为安装成功。 2. Vscode代码编辑器下载及使用:下载链接:Download Visual Studio Code - Mac, Linux, Windows (1)转换为中文:安装好后可在扩展区搜索Chinese插件下载,页面工具栏即可变成中文,如下图一:
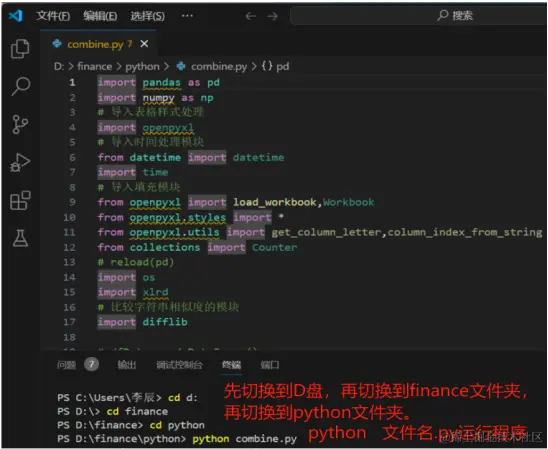
(2)vscode添加python:新建或打开编写的python程序后,vscode右下角会弹出添加python环境的提示,点击添加; (3)代码运行:按ctrl+~键打开终端运行程序,运行代码如下: 切换到运行文件所在目录: cd 目录 运行python文件: python 文件名.py
python 复制代码 # 导入表格数据读取及处理模块 import pandas as pd # 导入数据计算模块 import numpy as np # 导入时间处理模块 # from datetime import datetime # 导入读取和修改excel的模块 from openpyxl import load_workbook,Workbook # 导入表格样式处理模块 from openpyxl.styles import * # 比较字符串相似度的模块 import difflib # 导入表格数据读取及处理模块 import pandas as pd # 导入数据计算模块 import numpy as np # 导入时间处理模块 # from datetime import datetime # 导入读取和修改excel的模块 from openpyxl import load_workbook,Workbook # 导入表格样式处理模块 from openpyxl.styles import * # 比较字符串相似度的模块 import difflib # 表格存放目录 url = "D:\\finance\\rank\\数据表格.xlsx" # 整合后的表格存放目录 # afterUrl = '' # 两个表格的sheetname名称 before = 'ifinds' //表格A名称 after = 'winds' //表格B名称 # 最终整合后表格名称 finalName = '对比数据结果' # 读取两个表格-通过sheet名称读取 data1 = pd.read_excel(url, header = 0, sheet_name = before ) data2 = pd.read_excel(url, header = 0, sheet_name = after ) # 将数据重新赋值,避免修改数据后将原始ifind和wind数据修改 data3 = data1 data4 = data2 # 进行表头重命名以统一表头名称 # 对ifind表格的表头名称重命名 data3 = data3.rename(columns = { '所属国民经济行业门类':'国民一级', '所属国民经济行业大类':'国民二级', '币种':'注册资本币种', '注册资本':'注册资本(万元)','参保人数(人)':'参保人数', '地级市':'城市','企业中文名称':'公司中文名称',}) # 对wind表格的表头名称重命名 data4 = data4.rename(columns = { '企业名称':'公司名称', '公司属性':'企业性质', '国民经济分类门类':'国民一级','国民经济分类大类':'国民二级','国民经济行业-门类':'国民一级','国民经济行业-大类':'国民二级', '所属省份':'省份', '所属城市':'城市', '所属区县':'区/县', '负债及股东权益合计2022':'负债和所有者权益总计2022', '经营活动现金净流量2022':'经营活动产生的现金流量净额2022','负债及股东权益合计2023':'负债和所有者权益总计2023', '经营活动现金净流量2023':'经营活动产生的现金流量净额2023','主体最新信用评级':'最新最低主体评级','是否城投债':'是否城投(THS)', '公司发行股票一览':'股票代码','币种':'注册资本币种','参保人数(人)':'参保人数','注册资本(万元)':'注册资本(万元)','注册资本':'注册资本(万元)','是否城投':'是否城投(THS)','是否城投债':'是否城投(THS)',}) # # wind币种数据英文改中文 if '注册资本币种' in data4.columns: data4['注册资本币种'] = data4['注册资本币种'].replace('CNY', '人民币').replace('HKD', '港元').replace('MOP', '澳元').replace('USD', '美元').replace('EUR', '欧元').replace('IDR', '卢比').replace('RUB', '俄罗斯卢布').replace('AUD', '澳元').replace('GBP', '英镑') # ifind企业性质改变 if '企业性质' in data3.columns: data3['企业性质'] = data3['企业性质'].replace('中央企业', '国企').replace('中央国有企业', '国企').replace('地方国有企业', '国企').replace('国有企业', '国企').replace('民营企业', '私企').replace('私营', '私企').replace('外商独资', '外资企业') # wind企业性质改变 if '企业性质' in data4.columns: data4['企业性质'] = data4['企业性质'].replace('中央国有企业', '国企').replace('地方国有企业', '国企').replace('民营企业', '私企').replace('国有企业', '国企').replace('区县级国有企业', '国企').replace('市级国有企业', '国企').replace('省级国有企业', '国企') # ifind经营状态的改变 if '经营状态' in data3.columns: data3['经营状态'] = data3['经营状态'].replace('在业', '存续') # ifind和wind的企业规模的改变 if '企业规模' in data3.columns: data3['企业规模'] = data3['企业规模'].replace('L大型', '大型企业').replace('M中型', '中型企业').replace('S小型', '小型企业').replace('XS微型', '微型企业').replace('L(大型)', '大型企业').replace('M(中型)', '中型企业').replace('S(小型)', '小型企业').replace('XS(微型)', '微型企业') if '企业规模' in data4.columns: data4['企业规模'] = data4['企业规模'].replace('大型', '大型企业').replace('中型', '中型企业').replace('小型', '小型企业').replace('小微企业', '小型企业') # 参保人数数据取整函数 def newList(inputList): result = [] for num in inputList: if pd.isnull(num) or num == "--": num = 0 result.append(int(num)) return result # 调用函数 # ifind参保人数取整 if '参保人数' in data3.columns: data3['参保人数'] = newList(data3['参保人数']) # wind参保人数取整 if '参保人数' in data4.columns: data4['参保人数'] = newList(data4['参保人数']) # 保留两位小数的函数 def rateList(inputList): result = [] for num in inputList: num = float(num) if pd.isnull(num) or num == "--": num = 0 num = "{:.2f}".format(num) result.append(num) return result # 将wind的财务数据缩小10000倍 or value[:5] == '负债和所有' for value in data4.columns: if value[:5] == '所有者权益' or value[:4] == '营业收入' or value[:4] == '利润总额' or value[:4] == '资产总额' or value[:5] == '经营活动产': data4[value] = data4[value].apply(lambda x: x/10000) # 将ifind的财务数据保留两位 大股东持股比例、 注册资本(万元) for value in data3.columns: if value[:5] == '所有者权益' or value[:5] == '负债和所有' or value[:4] == '营业收入' or value[:4] == '利润总额' or value[:4] == '资产总额' or value[:5] == '经营活动产'or value[:5] == '注册资本(' or value[:5] == '大股东持股': data3[value] = rateList(data3[value]) # 将wind的财务数据保留两位 for value in data4.columns: if value[:5] == '所有者权益' or value[:5] == '负债和所有' or value[:4] == '营业收入' or value[:4] == '利润总额' or value[:4] == '资产总额' or value[:5] == '经营活动产'or value[:5] == '注册资本(' or value[:5] == '大股东持股': data4[value] = rateList(data4[value]) # # 经营范围重复度高于50%则取ifind的经营范围数据,否则标识出来 # 计算重复度的方法 # pdData3 = pd.DataFrame(data3) pdData4 = pd.DataFrame(data4) def string_similar(s1, s2): return difflib.SequenceMatcher(None, s1, s2).quick_ratio() if '经营范围' in data3.columns: for index in range(0, len(data3['经营范围']), 1): # 调用方法 if string_similar(str(data3['经营范围'][index]), str(data4['经营范围'][index])) > 0.5: # pdData4.loc[index,'经营范围'] = data3['经营范围'][index] data4['经营范围'][index] = data3['经营范围'][index] # wind省份数据北京、天津、重庆、上海添加‘市’字的函数 def addword(addData): result = [] for value in addData: if value == '北京' or value == '上海' or value == '天津' or value == '重庆': value = value + '市' result.append(value) return result # 调用函数 if '省份' in data4.columns: data4['省份']= addword(data4['省份']) # wind地市级去掉北京、重庆、上海、天津的函数 def deleteword(addData): result = [] for value in addData: if value == '北京市' or value == '上海市' or value == '天津市' or value == '重庆市': value = '0' result.append(value) return result # 调用函数 if '城市' in data4.columns: data4['城市']= deleteword(data4['城市']) # wind的股票代码去掉股票简称函数 def removeName(word): result = [] for value in word: value = str(value).split('(')[0] result.append(value) return result # 调用去掉股票简称的函数 if '股票代码' in data4.columns: data4['股票代码'] = removeName(data4['股票代码']) # 有股票代码的将上市公司信息改为是,否则改为否 pdData3 = pd.DataFrame(data3) if '股票代码' in data3.columns: for index in range(0, len(data3['股票代码']), 1): # 如果wind股票代码单元格的字符长度大于2,则将代码编号改为是,否则改为否 if len(str(data3['股票代码'][index])) > 2: pdData3.loc[index:, '是否上市'] = "是" else: pdData3.loc[index:, '是否上市'] = "否" # 如果wind股票代码单元格的字符长度大于2,则将代码编号改为是,否则改为否 if '股票代码' in data4.columns and len(str(data4['股票代码'][index])) > 2: pdData4.loc[index:, '是否上市'] = "是" else: pdData4.loc[index:, '是否上市'] = "否" # 合并两个表格数据,并且ifind数据在前,wind数据在后 result = pd.concat([data3, data4], ignore_index = True) # 得到的合并表格的标题,重新创建新表格,添加表头 dfNew = pd.DataFrame(columns = result.columns) # 获取合并的两个表格的索引,通过索引使两个表格的数据交叉排列 data3 = data3.set_index(np.arange(1, data3['序号'].count()+1, 1), drop = False) data4 = data4.set_index(np.arange(1, data4['序号'].count()+1, 1), drop = False) # 合并两个表格的索引到一个表格 for i in np.arange(1, data3['序号'].count()+1, 1): dfNew.loc[2*i-2] = data3.loc[i] dfNew.loc[2*i-1] = data4.loc[i] # 遍历判断:如果第一行数据为nan或为0,就把第二行的数据填充到第一行, for column in np.arange(0, dfNew.shape[0]): if column % 2 == 0: for index in range(len(dfNew.iloc[column].values)): if pd.isnull(dfNew.iloc[column].values[index]) or str(dfNew.iloc[column].values[index]) == '0' or str(dfNew.iloc[column].values[index]) == '0.00' or str(dfNew.iloc[column].values[index]) == '0.0': dfNew.iloc[column, index]= dfNew.iloc[column+1].values[index] # # 定义list,用来存储数据不同的列的下标数据 rowsList = [] columnsList = [[] for _ in range(dfNew.shape[0])] # 如果第二行数据和第一行数据不同,就把wind的数据添加括号拼接到ifind后 for row in np.arange(0, dfNew.shape[0]): if row % 2 == 0: rowsList.append(row) for index in range(len(dfNew.iloc[row].values)): if pd.notnull(dfNew.iloc[row+1].values[index]): # 处理因中英文括号导致的差异 if(str(dfNew.iloc[row].values[index]).replace('(','(').replace(')',')') != str(dfNew.iloc[row+1].values[index]).replace('(', '(').replace(')',')') and str(dfNew.iloc[row+1].values[index]) != '0' and str(dfNew.iloc[row+1].values[index]) != '0.00' and str(dfNew.iloc[row+1].values[index]) != '0.0') : dfNew.iloc[row, index] = str(dfNew.iloc[row].values[index]) + '{' + str(dfNew.iloc[row+1].values[index]) + '}' # 每一行的列的添加有问题 columnsList[row].append(index) else: dfNew.iloc[row, index] = str(dfNew.iloc[row].values[index]) # 将三个表格导出为三个sheet writer = pd.ExcelWriter(url) dfNew.to_excel(writer, sheet_name = finalName, index = False) data1.to_excel(writer, sheet_name = before, index = False) data2.to_excel(writer, sheet_name = after, index = False) writer._save() writer.close() # # 添加不同数据组的高亮 wb = load_workbook(url) sheet1 = wb['对比数据结果'] for row in rowsList: for column in columnsList[row]: sheet1.cell(row + 2,column + 1).fill = PatternFill('solid', fgColor = Color('9dff00')) # # 删除wind行的数据 第二行 deleteRow = [] for i in np.arange(dfNew.shape[0] + 5,2, -1): if i%2 == 1: sheet1.delete_rows(i) # # 导出添加样式后的表格 wb.save(url) wb.close() print("恭喜你,合并完成!")注意事项 1.注意两个表格第一列的表头为序号,第一列传入从1开始的序号作为合并数据的排列下标,否则程序会报错; 2.两组表格排列顺序要一致; 3.注意程序运行前要将表格关闭,表格被占用时程序不能运行会报错; 4.将两张表格放到一个excel文件的两个sheet中,对比数据表格放到第三个sheet中,注意名称要和代码里对应上; 总结我基本上已经处理到了表格合并遇上的大多问题,代码也添加了详细注释,欢迎大家来积极提出问题,共同解决问题。 作者:熊猫超不想吃cookies 链接:https://juejin.cn/post/7350283506927206439 来源:稀土掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 |





【本文地址】
今日新闻 |
推荐新闻 |