Python计算机视觉(三) |
您所在的位置:网站首页 › 两个图片拼接在一起 › Python计算机视觉(三) |
Python计算机视觉(三)
|
1. 基本原理
图像拼接是计算机视觉中的重要分支,它是将两幅以上的具有部分重叠的图像进行拼接从而得到较高分辨率或宽视角的图像。本文将结合python+opencv实现两幅图像的拼接。 图像拼接一般步骤: 1.根据给定图像/集,实现特征匹配 2.通过匹配特征计算图像之间的变换结构 3.利用图像变换结构,实现图像映射 4.针对叠加后的图像,采用APAP之类的算法,对齐 特征点 5.通过图割方法,自动选取拼接缝 6.根据multi-band blending策略实现融合 1.1 SIFT算法匹配特征SIFT特征包括兴趣点检测器和描述子,对于尺度、旋转和亮度都具有不变性。 使用SIFT算法获得基准图像img1和源图像img2的特征,使用opencv中的FLANN匹配算法进行特征匹配,选取优质的匹配点,可视化匹配结果。 代码: # 图像拼接 import cv2 as cv import numpy as np import matplotlib.pyplot as plt # 读取待拼接图像 MIN = 10 img1 = cv.imread('jm1.jpg') img2 = cv.imread('jm2.jpg') # 统一图像大小 height1 = int(img1.shape[0]) width1 = int(img1.shape[1]) dim = (width1, height1) img2 = cv.resize(img2, dim, interpolation=cv.INTER_AREA) # 创建SIFT特征点检测 sift = cv.SIFT_create() # 检测兴趣点并计算描述子 kp1, describe1 = sift.detectAndCompute(img1, None) kp2, describe2 = sift.detectAndCompute(img2, None) # 使用OpenCV中的FLANN匹配算法进行特征匹配,并返回最近邻和次近邻匹配的结果 FLANN_INDEX_KDTREE = 0 indexParams = dict(algorithm=FLANN_INDEX_KDTREE, trees=5) searchParams = dict(checks=50) flann = cv.FlannBasedMatcher(indexParams,searchParams) matches = flann.knnMatch(describe1, describe2, k=2) # 储存特征匹配最好的优质匹配点对 '''基于距离阈值选择优质匹配点对,如果最近邻m的距离小于0.65倍的次近邻n的距离, 则认为这个匹配点对是优质的,将它存储在good列表中。''' good = [] for m,n in matches: if m.distance < 0.65 * n.distance: good.append(m) # 可视化特征匹配结果,并保存 pic3 = cv.drawMatches(img1=img1, keypoints1=kp1, img2=img2, keypoints2=kp2, matches1to2=good, outImg=None) cv.imwrite(r'/Users/xionglulu/Downloads/project1/m11.jpg', pic3)结果:  特征匹配图
特征匹配图
结果分析:SIFT算法对图像特征点的提取更全面,但在匹配时也存在错误,对于相似度过高的点匹配效果并不好。通过改变距离阈值大小,可以改变匹配点对数量,阈值越小,匹配数量越少,同时准确率也越高。 1.2 RANSAC算法 RANSAC(Random Sample Consensus,随机抽样一致性)算法是一种用于估计模型参数的迭代算法,其主要目的是从包含噪声和异常值的数据集中估计出最优的模型参数。 RANSAC算法的基本思想是随机选择一组数据点来拟合模型,然后使用该模型来计算所有数据点与模型的拟合误差。如果某个数据点与模型的误差小于一个阈值,则将其视为内点,否则视为外点。算法重复这个过程,直到找到满足一定置信度的最优模型。 RANSAC算法的步骤如下: 1.从数据集中随机选择一组数据点,根据这些数据点拟合模型。 2.对于所有的数据点,计算其与模型的误差,并将误差小于一个阈值的数据点视为内点,否则视为外点。 3.如果内点的数量大于指定的阈值,则使用所有内点重新估计模型,并计算内点的误差。如果内点的数量小于指定的阈值,则返回步骤1。 4.如果当前模型的内点数量大于之前的模型,则将当前模型作为最优模型,并更新内点的阈值和置信度。 5.重复步骤1到4,直到达到指定的迭代次数或置信度。 本文图像拼接采用RANSAC算法计算出特征点之间的单应性变换矩阵,每次随机选取4个特征点对,然后通过透视变换将img2映射到img1。 1.3 APAP算法在图像拼接融合的过程中,受客观因素的影响,拼接融合后的图像可能会存在“鬼影现象”以及图像间过度不连续等问题。为解决这一问题,可以采用APAP算法。 APAP算法步骤如下: 1.SIFT得到两幅图像的匹配点对 2.通过RANSAC剔除外点,得到N对内点 3.利用DLT和SVD计算全局单应性 4.将目标图划分网格,取网格中心点,计算每个中心点和目标图上内点之间的欧式距离和权重 5.将权重放到DLT算法的A矩阵中,构建成新的W*A矩阵,重新SVD分解,自然就得到了当前网格的局部单应性矩阵 6.遍历每个网格,利用局部单应性矩阵映射到全景画布上,就得到了APAP变换后的目标图 7.最后就是进行拼接线的加权融合 1.4 最大流最小割方法找最佳拼接缝当两张图像拼接完成后,可能会出现情况:两张图像之间的过度不连续,也就是存在拼接缝隙,拼接线两侧的灰度变化较为明显。最大流最小割方法可以解决这个问题。 最大流 给定指定的一个有向图,其中有两个特殊的点源S(Sources)和汇T(Sinks),每条边有指定的容量(Capacity),求满足条件的从S到T的最大流(MaxFlow)。 最小割 割是网络中定点的一个划分,它把网络中的所有顶点划分成两个顶点集合S和T,其中源点s∈S,汇点t∈T。记为CUT(S,T),满足条件的从S到T的最小割(Min cut)。 1.5 multi-band blending算法在找完拼接缝后,由于图像噪声、光照、曝光度、模型匹配误差等因素,直接进行图像合成会在图像重叠区域的拼接处出现比较明显的边痕迹。这些边痕迹需要使用图像融合算法来消除。其中一种方法为Multi-Band Blending。 Multi-Band Blending的基本原理如下: 1.图像金字塔 首先,对于两张待融合的图像,需要将它们分别构建成图像金字塔。图像金字塔是一种分层存储图像的数据结构,它可以将图像分解为多个不同尺度的子图像,从而实现图像的分层处理。 2.拉普拉斯金字塔 在构建完图像金字塔后,需要对每个图像金字塔层进行拉普拉斯变换。拉普拉斯变换可以将每个图像金字塔层分解为一个高频分量和一个低频分量。高频分量包含图像的细节信息,低频分量包含图像的整体结构信息。 3.融合 在得到每个图像金字塔层的拉普拉斯变换后,可以对它们进行融合。Multi-Band Blending算法采用了加权平均的方法,即对于每个拉普拉斯金字塔层,将它们的高频分量进行加权平均,将它们的低频分量进行简单平均,从而得到最终的融合结果。 4.重构 最后,需要对融合后的图像金字塔进行重构。重构的过程就是将每个拉普拉斯金字塔层进行反变换,从而得到最终的融合图像。 2.代码实现 # 图像拼接 import cv2 as cv import numpy as np import matplotlib.pyplot as plt # 读取待拼接图像 MIN = 10 img1 = cv.imread('jm1.jpg') img2 = cv.imread('jm2.jpg') # 统一图像大小 height1 = int(img1.shape[0]) width1 = int(img1.shape[1]) dim = (width1, height1) img2 = cv.resize(img2, dim, interpolation=cv.INTER_AREA) # 创建SIFT特征点检测 sift = cv.SIFT_create() # 检测兴趣点并计算描述子 kp1, describe1 = sift.detectAndCompute(img1, None) kp2, describe2 = sift.detectAndCompute(img2, None) # 使用OpenCV中的FLANN匹配算法进行特征匹配,并返回最近邻和次近邻匹配的结果 FLANN_INDEX_KDTREE = 0 indexParams = dict(algorithm=FLANN_INDEX_KDTREE, trees=5) searchParams = dict(checks=50) flann = cv.FlannBasedMatcher(indexParams,searchParams) matches = flann.knnMatch(describe1, describe2, k=2) # 储存特征匹配最好的优质匹配点对 '''基于距离阈值选择优质匹配点对,如果最近邻m的距离小于0.65倍的次近邻n的距离, 则认为这个匹配点对是优质的,将它存储在good列表中。''' good = [] for m,n in matches: if m.distance < 0.65 * n.distance: good.append(m) # 可视化特征匹配结果,并保存 pic3 = cv.drawMatches(img1=img1, keypoints1=kp1, img2=img2, keypoints2=kp2, matches1to2=good, outImg=None) cv.imwrite(r'/Users/xionglulu/Downloads/project1/m11.jpg', pic3) # RANSAC算法计算单应性矩阵 if len(good) > MIN: src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2) tge_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2) M, mask = cv.findHomography(src_pts, tge_pts, cv.RANSAC, 2) # 源图像img2图像扭曲(透视变换) warpimg = cv.warpPerspective(img2, np.linalg.inv(M), (img1.shape[1] + img2.shape[1], img2.shape[0])) cv.namedWindow("warpimg", cv.WINDOW_NORMAL) cv.imshow('warpimg',warpimg) # 拼接图像 direct = warpimg.copy() direct[0:img1.shape[0], 0:img1.shape[1]] = img1 rows, cols = img1.shape[:2] left = 0 right = cols # 找到img1和warpimg重叠的最左边界 for col in range(0, cols): if img1[:, col].any() and warpimg[:, col].any(): left = col break # 找到img1和warpimg重叠的最右边界 for col in range(cols - 1, 0, -1): if img1[:, col].any() and warpimg[:, col].any(): right = col break # 图像融合 res = np.zeros([rows, cols, 3], np.uint8) for row in range(0, rows): for col in range(0, cols): if not img1[row, col].any(): res[row, col] = warpimg[row, col] elif not warpimg[row, col].any(): res[row, col] = img1[row, col] else: # 重叠部分加权平均 srcimgLen = float(abs(col - left)) testimgLen = float(abs(col - right)) alpha = srcimgLen / (srcimgLen + testimgLen) res[row, col] = np.clip(img1[row, col] * (1 - alpha) + warpimg[row, col] * alpha, 0, 255) warpimg[0:img1.shape[0], 0:img1.shape[1]] = res img3 = cv.cvtColor(direct, cv.COLOR_BGR2RGB) plt.imshow(img3), plt.show() img4 = cv.cvtColor(warpimg, cv.COLOR_BGR2RGB) plt.imshow(img4), plt.show() cv.waitKey() cv.destroyAllWindows() else: print("not enough matches!")结果:  映射结果图
映射结果图
 阈值为2图像拼接结果图
阈值为2图像拼接结果图
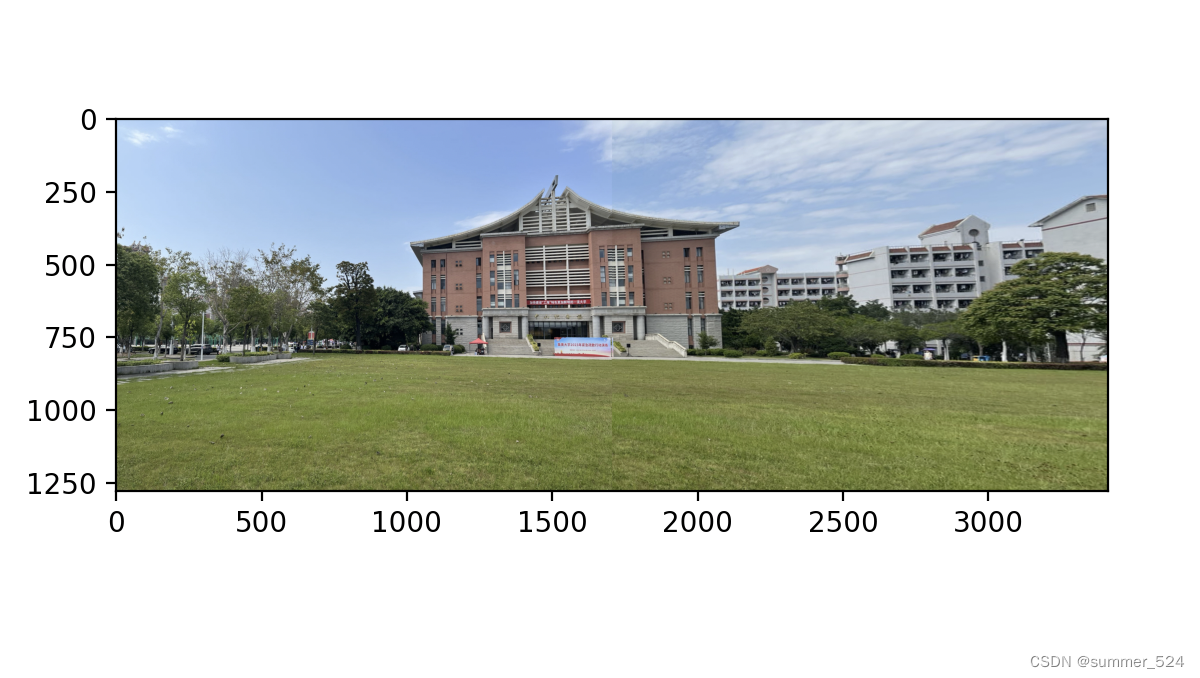 阈值为10图像拼接结果图
阈值为10图像拼接结果图
 阈值为2图像融合结果图
阈值为2图像融合结果图
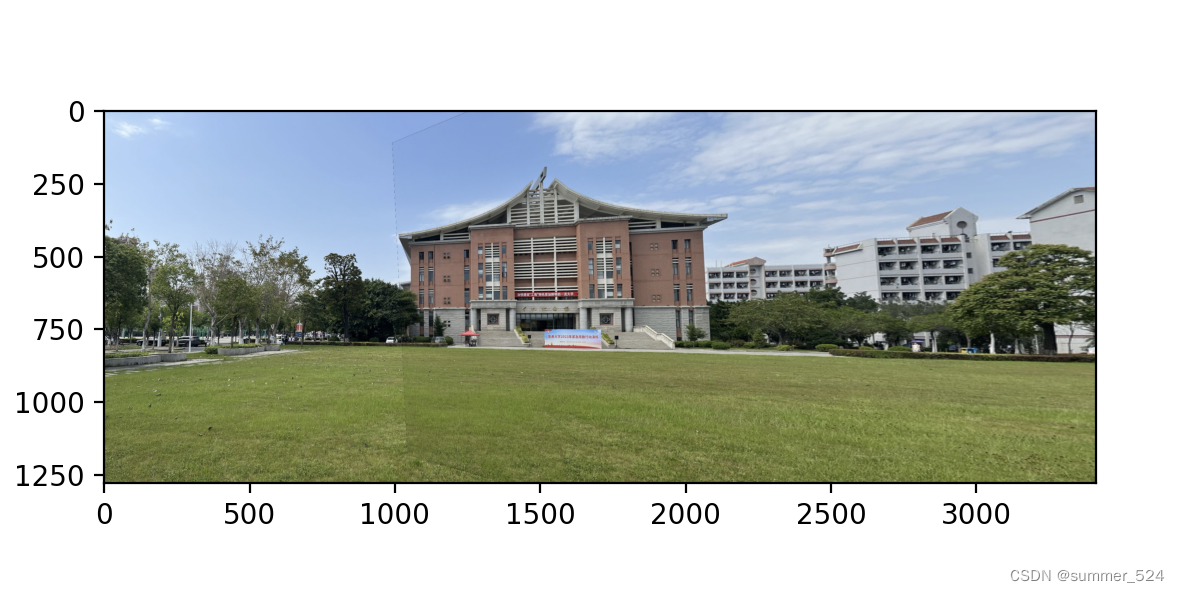 阈值为10图像融合结果图
阈值为10图像融合结果图
结果分析: 1.拍摄时的角度、光线、曝光程度和远近程度等对图像匹配结果都会有影响。 2.SIFT算法进行特征匹配时,对于高度相似的特征点匹配效果并不好;RANSAC算法计算单应性矩阵时通过设置不同阈值选择内点,匹配的效果也不同;实验中阈值为2时,匹配效果比较好,但是映射时图像变形比较严重;实验中阈值为10时,变形缓解但是匹配效果并不好。 3.在进行图像融合时,本实验对重叠部分采用的是加权平均法,可以看出拼接缝两侧的颜色过渡比较自然,但仍可以采用Multi-Band Blending算法更好的融合,尽可能消除拼接缝。 下面介绍另一种方法实现图像拼接与融合,使用opencv库中的cv2.Stitcher_create()函数创建了一个stitcher对象,并使用stitcher.stitch((img1, img2))函数将两张图像img1和img2拼接在一起。 cv2.Stitcher_create()函数接受一个可选的参数mode,用于指定拼接模式。mode的取值可以是以下两个常量之一: cv2.STITCHER_PANORAMA:全景拼接模式。 cv2.STITCHER_SCANS:扫描线拼接模式。 stitcher.stitch()函数返回一个包含两个元素的元组,其中第一个元素是一个整数,表示拼接的状态,第二个元素是一个numpy数组,表示拼接后的图像。 代码: import cv2 # 读取待拼接图像 img1 = cv2.imread('/Users/xionglulu/Downloads/project1/jm1.jpg') img2 = cv2.imread('/Users/xionglulu/Downloads/project1/jm2.jpg') # 创建stitcher对象并将两张图像拼接在一起 stitcher = cv2.Stitcher_create() (status, stitched) = stitcher.stitch((img1, img2)) # 显示拼接后的图像 cv2.namedWindow("stitched image", cv2.WINDOW_NORMAL) cv2.imshow("stitched image", stitched) cv2.waitKey() cv2.destroyAllWindows()结果:  全景图
全景图
结果分析:这种方法获得的全景图几乎完美,图像没有发生变形,没有明显拼接缝,而且颜色过渡均匀,但是存在一个问题,它似乎并不能对所有指定图像进行拼接处理,对拍摄角度相差不大的图像运行会出错,具体原因还有待考证。
|
【本文地址】
今日新闻 |
推荐新闻 |