【论文阅读】投影不完全多视图聚类 |
您所在的位置:网站首页 › 不平衡数据聚类 › 【论文阅读】投影不完全多视图聚类 |
【论文阅读】投影不完全多视图聚类
|
Projective Incomplete Multi-View Clustering
原文链接 在实际情况中总是存在缺少视图的情况,并且基于矩阵分解(MF)的方法通常不能处理新的样本,也没有考虑到不同观点之间信息的不平衡。 为了解决这两个问题,提出了一种新的IMVC方法,该方法为不完全多视图数据聚类任务建立了一种新的简单的图正则化投影共识表示学习模型。与现有的方法相比,本文的方法不仅可以获得一组投影来处理新的样本,而且可以通过学习统一的低维子空间中的共识表示来平衡地探索多个视图的信息。此外,在一致性表示上施加了一个图约束,以挖掘数据内部的结构信息。 PIMVC的目标是共同学习每个视图的投影矩阵和不完全多视图共享的共识特征表示进行聚类。具体而言,PIMVC将传统的多视图MF模型重新表述为多视图投影学习模型。通过将不同观点的客观损失最小化到同一维数的统一子空间中,巧妙地解决了维度多样性导致的不同观点之间的信息不平衡可能导致一种观点主导共识表示学习的问题。此外,为了捕获数据的几何结构,引入了图正则化惩罚项。提出了一种求解目标模型的算法,并从理论上分析了优化算法的计算复杂度和收敛性。 GPMVC
第一项:数据重构 第二项:共享特征表示 第三项:考虑样本之间的相似度 Online MVC
W动态权重矩阵,对缺失的实例分配较小的权重,对未缺失的实例分配较大的权重,以减弱填充造成的不准确性。 Framework of proposed PIMVC
基于MF的方法将原始特征数据分解为基矩阵和潜特征矩阵的乘积,导致其无法处理新样本。此外,不同视图下的数据维度通常不同,导致视图间的信息不平衡,而基于MF的方法在模型优化过程中会加剧这种信息不平衡。这表明多视图联合模型优化可能会更多地关注大维视图的分解损失,而忽略其他小维视图的信息。 为了解决这一问题提出了一种受子空间学习启发的不完全多视图数据的投影一致表示学习模型。与传统的基于MF的方法不同,本文的方法寻求将所有具有不同特征维数的视图投影到同一维数c上,从而将不同维数的不同视图的分解损失转化为同一子空间维数上的损失。这样可以有效降低传统的基于MF的多视图学习模型中由于特征维数差异而导致的信息不平衡的负面影响。 为此,设计了以下针对不完整多视图数据的投影共识表示学习模型: 通过探索数据的几何结构,可以进一步提高聚类性能。考虑到在新的子空间中,最近邻也期望彼此相邻,进一步引入一个简单的图正则化项,如下所示来探索数据的邻居结构: 对于不完整的多视图数据,由于缺少视图,很难直接从第v个视图构建一个完整的图S (v)。可以先从不完全视图构造邻接矩阵W(v),然后根据视图缺失和视图可用信息,通过矩阵变换得到相似矩阵,如下所示: 求导 固定Y更新P将范数转化为迹 本文提出了一种新的IMVC算法——PIMVC。与其他IMVC方法不同,PIMVC将投影学习应用到IMVC中,解决了不同视图之间的信息不平衡问题,并且能够处理新的样本。通过引入不相关约束,PIMVC不仅避免了无意义的平凡解,而且得到了优化目标模型的解析解。 通过构造一个图正则化约束,PIMVC可以利用数据的几何结构,提高聚类性能。本文还提出了一种交替迭代算法来求解目标学习模型,理论和实验都证明了该算法的收敛性。最后,在四个数据集上的大量实验表明,我们的方法在大多数情况下都能产生最佳的聚类结果。 实际上,PIMVC最重要的作用是学习每个视图的投影矩阵,即原始数据空间与潜在子空间之间的映射关系。在本文中,我们只使用最简单的线性关系来拟合这种映射关系,并取得了很好的效果。深度神经网络具有较强的拟合能力,可以拟合复杂的非线性关系。因此,在未来的工作中,我们将致力于为投影矩阵设计合适的神经网络,以更好地学习映射关系 |
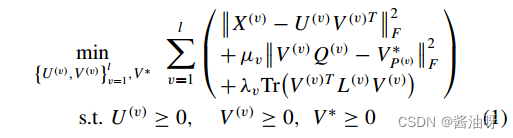 X (v)∈ dv×nv表示第v个视图的非负数据矩阵。U(v)∈ mv×k表示基矩阵,V(v)∈ nv×k表示第v个视图的潜在特征表示,其中k为聚类的个数。Q (v)是一个对角矩阵,V∗∈ n×k是公共特征矩阵,其行可以看作是所有视图共享的每个样本的新表示。L (v)∈ nv×nv是一个拉普拉斯矩阵。µv和λv是V-th视图的惩罚参数。
X (v)∈ dv×nv表示第v个视图的非负数据矩阵。U(v)∈ mv×k表示基矩阵,V(v)∈ nv×k表示第v个视图的潜在特征表示,其中k为聚类的个数。Q (v)是一个对角矩阵,V∗∈ n×k是公共特征矩阵,其行可以看作是所有视图共享的每个样本的新表示。L (v)∈ nv×nv是一个拉普拉斯矩阵。µv和λv是V-th视图的惩罚参数。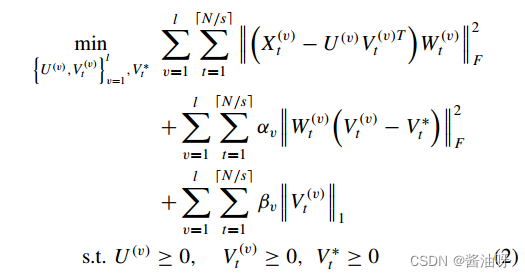 第一项:数据重构 第二项:一致表示 第三项:l1正则化
第一项:数据重构 第二项:一致表示 第三项:l1正则化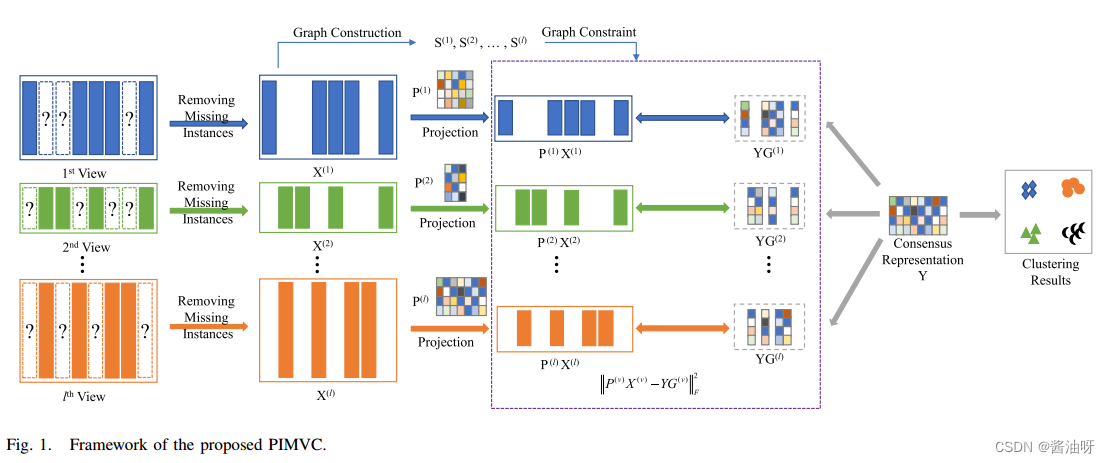
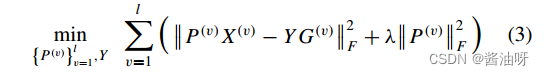 其中X (v) = [x1, x2,…]表示VTH视图中的数据,dv表示VTH视图的维数,nv表示VTH视图中未遗漏的实例数。P (v)∈ c×dv是第v个视图的投影矩阵,它将X (v)映射到空间的 c×nv上,一方面解决了信息不平衡的问题,另一方面起到降维的作用。此外,学习投影矩阵也有利于从复杂高维数据中提取最具判别性的特征,从而提高聚类性能。C是子空间的维数,也可以简单地设置为期望簇的个数。Y∈λ c×n为多视图数据的共识特征表示,n为完整数据的样本数,G (v)是第v个视图的缺失索引矩阵,用于将多视图数据的共识特征表示映射到特定于视图的特征表示。
其中X (v) = [x1, x2,…]表示VTH视图中的数据,dv表示VTH视图的维数,nv表示VTH视图中未遗漏的实例数。P (v)∈ c×dv是第v个视图的投影矩阵,它将X (v)映射到空间的 c×nv上,一方面解决了信息不平衡的问题,另一方面起到降维的作用。此外,学习投影矩阵也有利于从复杂高维数据中提取最具判别性的特征,从而提高聚类性能。C是子空间的维数,也可以简单地设置为期望簇的个数。Y∈λ c×n为多视图数据的共识特征表示,n为完整数据的样本数,G (v)是第v个视图的缺失索引矩阵,用于将多视图数据的共识特征表示映射到特定于视图的特征表示。  模型(3)的另一个优越特性是它处理新样本的能力。当有一个新的样本P, P (v)∈R dv×1是它的第v个视图,而gv表示P (v)的第v个视图的缺失或可用信息时,可以简单地得到它的共识特征表示:
模型(3)的另一个优越特性是它处理新样本的能力。当有一个新的样本P, P (v)∈R dv×1是它的第v个视图,而gv表示P (v)的第v个视图的缺失或可用信息时,可以简单地得到它的共识特征表示: 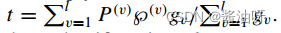 然后,可以使用最简单的分类器,即k-最近邻分类器,通过视图的数据计算t和共识表示Y对应的欧氏距离,有效地获得新样本p的标签。此外,也可以选择一些流行的监督分类器,如稀疏表示、支持向量机、线性回归等作为后处理方法,对新样本获得更高的分类性能。 为了避免平凡解,引入不相关约束,新模型变为:
然后,可以使用最简单的分类器,即k-最近邻分类器,通过视图的数据计算t和共识表示Y对应的欧氏距离,有效地获得新样本p的标签。此外,也可以选择一些流行的监督分类器,如稀疏表示、支持向量机、线性回归等作为后处理方法,对新样本获得更高的分类性能。 为了避免平凡解,引入不相关约束,新模型变为: 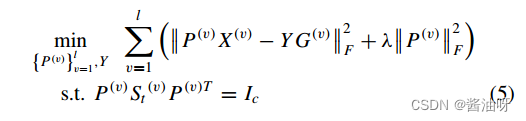 St (v)是一个散点矩阵,定义为X(v) H X(v)T,从第v视图构造,H在本文中被简单地设置为单位矩阵。考虑到nv小于dv时散点矩阵不是正定的,对散点进行了修正矩阵St (v) = X(v) H X(v)T + λI。否则,模型(5)也可能陷入平凡解。这里,散点矩阵和矩阵P (v)的Frobenius范数共用一个参数λ,这是减小参数的小技巧,求解起来更容易。
St (v)是一个散点矩阵,定义为X(v) H X(v)T,从第v视图构造,H在本文中被简单地设置为单位矩阵。考虑到nv小于dv时散点矩阵不是正定的,对散点进行了修正矩阵St (v) = X(v) H X(v)T + λI。否则,模型(5)也可能陷入平凡解。这里,散点矩阵和矩阵P (v)的Frobenius范数共用一个参数λ,这是减小参数的小技巧,求解起来更容易。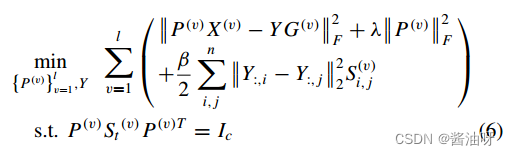 S (v) i,j表示第i个实例与第j个实例在第v个视图中的相似度。在该模型中,当第i和第j个实例具有最近邻关系时,S (v) i,j = 1;否则,S (v) i,j = 0。
S (v) i,j表示第i个实例与第j个实例在第v个视图中的相似度。在该模型中,当第i和第j个实例具有最近邻关系时,S (v) i,j = 1;否则,S (v) i,j = 0。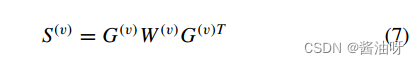 G是缺失指示矩阵。
G是缺失指示矩阵。【本文地址】