【python爬虫】动漫之家漫画下载(scrapy) |
您所在的位置:网站首页 › 下载漫画图片的浏览器叫什么 › 【python爬虫】动漫之家漫画下载(scrapy) |
【python爬虫】动漫之家漫画下载(scrapy)
|
【python爬虫】动漫之家漫画下载(scrapy)
好久没有更新自己的CSDN,最近在沉迷爬虫,一开始学习爬虫的时候一直想要做一个下载漫画的(毕竟是死宅),但是在掌握下载图片的技术之后,并没能马上实现这个技术,因为一般这种网站,都会用js把漫画的链接各种加密,打乱,所以比较麻烦,在学了selenium之后,倒是可以成功下载了,但是总觉得少了点什么,但是要破解js,又觉得有点难度,本文将带领大家从另一个角度考虑这个问题,希望对大家之后的爬虫之路有所启发。 ps(这里是注意的点): 这次爬取的网站是动漫之家爬取时使用scrapy框架(使用scrapy框架是因为他使用了异步下载模式,这样下载漫画比较快),但是如果只是想要学习从另一个角度考虑问题的,可以继续往下文看,因为也不是很难本文用于技术交流,如果侵犯版权立即删除,任何人不能用于商业用途先说说代码的运行模式,这里需要用户输入需要下载漫画的网址和名字(网址一定要准确,但是名字可以随意),一开始本来想要用漫画名字下载的,但是发现漫画的名字在网址中有不同的格式(有利用漫画名全拼的也有用漫画名字首字母的),所以就暂时放弃这种方法(等之后自己的技术更为精湛,再回来修改) 这里以漫画https://manhua.dmzj.com/womenyiqiwufaxuexi/ (我们无法一起学习)为例 这样子前期工作就ok了,接下来就是重点了 自己创建一个py文件,文件名没有关系(但是这个文件放的位置最好和我的一样),我在这个项目里面创建的py文件名字是dmzj_start.py,这个文件是用来启动这个scrapy框架的爬虫的,内容如下: from scrapy import cmdline import sys if __name__ == '__main__': manhua_url = input("请输入网址:").strip() manhua_names = input("请输入漫画名:").strip() cmdline.execute(str("scrapy crawl dmzj_spider -a manhua_url=%s -a manhua_names=%s"%(manhua_url,manhua_names)).split()) # cmdline.execute(str("scrapy crawl dmzj_spider -a manhua_url=%s -a manhua_names=%s"%(sys.argv[1],sys.argv[2])).split())前两个input用于输入漫画的网址和漫画的名字(ps:网址一定要对,但是名字可以随意) 在dmzj_spider.py中开始分析网页 这里有一点是需要注意的,我们现在利用的是app的网页来下载漫画的,但是直接用app的网页来下载那么对于用户的体验也太糟糕了(用户还得专门找到对应的app端网址,太麻烦了),那么这种麻烦的事情当然由我们来做了,用户只要输入pc端的网址就可以了,既然是同一部漫画,那么他们之间肯定存在联系 这个是pc端的网址 这里要说一点,现在我们说的这种模式是日漫的模式,国漫那边更简单,我们贴上网址对比一下 pc端 到这里,我们通过pc端的网址,成功获得app端的网址,进行了一点点优化 在前面已经说过了,每一话的链接都在这个script中 至此,我们已经得到每一话里面所有图片的链接了,那么接下来的事情便是把他们下载下来,再根据每一话的将他们分别保存好,这样就大功告成了 打开piplines.py开始写代码,先定义了一开始输入漫画名字的文件夹,如何再根据每一话创建文件夹,之后再下载每一张图片 import os import requests class DmzjScrapyPipeline(object): def process_item(self, item, spider): headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', 'cookie': 'UM_distinctid=16706eb86dcd8-02bc2f02cd5057-333b5602-100200-16706eb86dd6e5; bdshare_firstime=1542009358470; laravel_session=eyJpdiI6InJZMTQrZFlRVFphOVlXU2R0dFwvRnl3PT0iLCJ2YWx1ZSI6IjFJZGdacHA5YkJSRzhHSWJoVklwaTNiaTl0dHRCMzFwSzRGT0oxWm81MXl5aGtkT0lDVHFQRTlBcUJkN3hEQ2xWXC9yZWRxbjJzNSthVWg2VFBVbXRUZz09IiwibWFjIjoiZmZiY2Q0YjkyZTAwMzBjNDk4YjAwZmVkYTg1NzY3NmY4MzU5YjM2NjQzZTdlNTExMWI3ZmJiYTMyNjhlN2YwMSJ9; CNZZDATA1255781707=1633799429-1542006327-%7C1542011727; CNZZDATA1000465408=1899900830-1542005345-%7C1542012974', 'referer': 'https://m.dmzj.com/info/zuizhongwochengleni.html' } # path = os.path.dirname(os.path.dirname(__file__)) #path是下载的地址,可以根据需要把这里改掉,这里设定的是当前目录 path = './' #确认漫画的目录是否存在 manhua_name = os.path.join(path,item['big_title']) # print("="*40) # print(manhua_name) # print("=" * 40) if not os.path.exists(manhua_name): os.mkdir(manhua_name) # 确认每一话的目录是否存在 catapot_name = os.path.join(manhua_name,item['title']) if not os.path.exists(catapot_name): os.mkdir(catapot_name) #开始逐一下载一话中所有的图片 #capter为该话中图片的具体名字 for pic_url in item['pic_urls']: capter = pic_url.split('/')[-1] response = requests.get(pic_url, headers=headers).content with open(catapot_name+r'\\'+capter,'wb') as fp: fp.write(response) fp.close() print("正在下载"+item['big_title']+" "+item['title']+" "+capter) return item写到这里就已经完全ok了,接下来就在dmzj_start.py运行 |
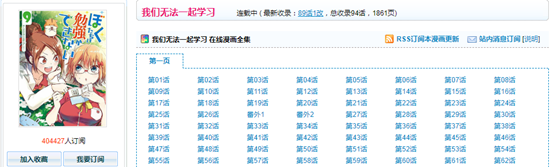 来到漫画的目录,一开始的想法是利用爬虫把每一话的遍历一次,再进去具体页面进行下载,但是这种想法很快就破产了,在具体页中,我们能通过f12迅速找到漫画图片的网址
来到漫画的目录,一开始的想法是利用爬虫把每一话的遍历一次,再进去具体页面进行下载,但是这种想法很快就破产了,在具体页中,我们能通过f12迅速找到漫画图片的网址 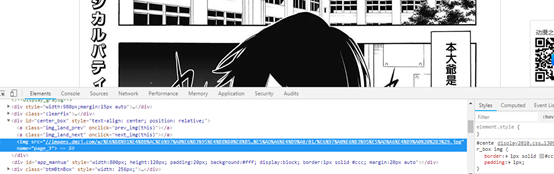 但很可惜,这是通过js动态加载出来的,也就是我们是没有办法直接获取这个网址,一开始的想法当然是寻找出这个链接的规律,但是很可惜,这个链接的规则也是十分的复杂
但很可惜,这是通过js动态加载出来的,也就是我们是没有办法直接获取这个网址,一开始的想法当然是寻找出这个链接的规律,但是很可惜,这个链接的规则也是十分的复杂 
 漫画图片的名字都有各自的规则,应该还有一些是js随机弄出来的数字,所以破解出来暂时对我来说是不现实的,这个时候似乎就只剩下用selenium一个办法了,可是这样又稍微有点不爽,总觉得好像输了,执着(钻牛角尖)的我在机缘巧合之下发现,动漫之家是有app的,这时候灵机一动,打开浏览器,www.baidu.com,成功让我找到客户端的网址,顺便一提(网址是这个https://m.dmzj.com/ ),于是乎,我们便成功来带了app所在的网页
漫画图片的名字都有各自的规则,应该还有一些是js随机弄出来的数字,所以破解出来暂时对我来说是不现实的,这个时候似乎就只剩下用selenium一个办法了,可是这样又稍微有点不爽,总觉得好像输了,执着(钻牛角尖)的我在机缘巧合之下发现,动漫之家是有app的,这时候灵机一动,打开浏览器,www.baidu.com,成功让我找到客户端的网址,顺便一提(网址是这个https://m.dmzj.com/ ),于是乎,我们便成功来带了app所在的网页  而在源代码中,我们发现了这样一个script
而在源代码中,我们发现了这样一个script  这个就是这个漫画的目录了,再来到具体页,查看源代码,发现了另外一个script,这是这一话所有的图片链接
这个就是这个漫画的目录了,再来到具体页,查看源代码,发现了另外一个script,这是这一话所有的图片链接  聪明的同学到这里已经完全知道接下来应该怎么做了,那么就可以开始用这种思路来挑战一下自己的爬虫技术把,还没有懂的同学也没有关系,接下来我会好好讲解一下,之后也会将代码贴在GitHub,有兴趣的同学可以下载来看看。 使用scrapy进行爬虫,scrapy框架目录结构如下:
聪明的同学到这里已经完全知道接下来应该怎么做了,那么就可以开始用这种思路来挑战一下自己的爬虫技术把,还没有懂的同学也没有关系,接下来我会好好讲解一下,之后也会将代码贴在GitHub,有兴趣的同学可以下载来看看。 使用scrapy进行爬虫,scrapy框架目录结构如下:  在使用命令行创建scrapy之后,首先是在setting.py中将机器人协议改为false,设置请求头,还有将piplines的注释取消掉
在使用命令行创建scrapy之后,首先是在setting.py中将机器人协议改为false,设置请求头,还有将piplines的注释取消掉 

 将要传输的内容在item.py中定义好
将要传输的内容在item.py中定义好 这个是app端的网址
这个是app端的网址  很显然,pc端网址是通过漫画名字的拼音来确定的,而app段却是一段看不懂的数字,这串数字应该不是随机生成的,而是这一步漫画在对方服务器数据库里面的id之类的东西,那么这个东西在pc端是否也可以找到呢?
很显然,pc端网址是通过漫画名字的拼音来确定的,而app段却是一段看不懂的数字,这串数字应该不是随机生成的,而是这一步漫画在对方服务器数据库里面的id之类的东西,那么这个东西在pc端是否也可以找到呢? 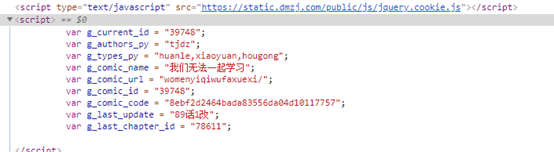 果不其然,这就是两者之间的联系,那么剩下的事情就简单了,靠强大的正则表达式就可以解决问题了,贴上代码。
果不其然,这就是两者之间的联系,那么剩下的事情就简单了,靠强大的正则表达式就可以解决问题了,贴上代码。 app端
app端  一对比发现网址基本一样,那么正则表达式就可以完美解决这个问题了
一对比发现网址基本一样,那么正则表达式就可以完美解决这个问题了 而每一话中的所有图片在另外一个script中
而每一话中的所有图片在另外一个script中  再次通过正则表达式,将这些被故意打乱的数据进行清洗,得到我们想要的结果,代码分别如下
再次通过正则表达式,将这些被故意打乱的数据进行清洗,得到我们想要的结果,代码分别如下
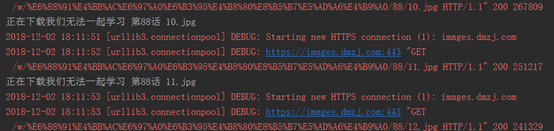 之后便开始下载了,这里要说一点,因为scrapy框架采用了多线程下载,所以下载顺序是乱的,有可能先下第一话,也有可能先下最后一话,不过影响不大,而且多线程的效率是很高的,而且下载速度最好也稍微慢一点,毕竟我们是来学习的,不是来搞垮人家服务器的。 这里下载一部分,我就停止程序了,给大家看看结果,接下来就开始愉快地看漫画吧!
之后便开始下载了,这里要说一点,因为scrapy框架采用了多线程下载,所以下载顺序是乱的,有可能先下第一话,也有可能先下最后一话,不过影响不大,而且多线程的效率是很高的,而且下载速度最好也稍微慢一点,毕竟我们是来学习的,不是来搞垮人家服务器的。 这里下载一部分,我就停止程序了,给大家看看结果,接下来就开始愉快地看漫画吧! 
 我的分享就到这里了,要是大家能从里面收获到一点点,那对我来说便是极好了,我会把代码发到GitHub上,有兴趣的同学可以下载来研究一下!谢谢大家! GitHub地址:https://github.com/weakmaple/dmzj_scrapy
我的分享就到这里了,要是大家能从里面收获到一点点,那对我来说便是极好了,我会把代码发到GitHub上,有兴趣的同学可以下载来研究一下!谢谢大家! GitHub地址:https://github.com/weakmaple/dmzj_scrapy【本文地址】
今日新闻 |
推荐新闻 |