【NeRF】AIGC高阶魔法 |
您所在的位置:网站首页 › 三维重建程序 › 【NeRF】AIGC高阶魔法 |
【NeRF】AIGC高阶魔法
|
还在沉迷用Stable Diffusion创作二次元老婆吗?想不想用AIGC更高阶的魔法创作3D老婆?本文带你来了解一下AIGC在3D场景重建渲染领域的工作! 一、新视角合成3D场景重建与渲染是传统计算机视觉领域的一大研究方向,涉及到多个学科专业知识。本文仅对其中新视角合成技术路线与AIGC领域相结合的工作作以简要介绍。 1.1 新视角合成技术介绍新视角合成(Novel View Synthesis)指给定某3D物体的一组2D图像及拍摄视角,求渲染生成未知视角下该物体的2D图像。例如,给定一些红色架子鼓的不同拍摄视角下的照片,我们希望获得未知视角下该红色架子鼓的图像,如下图所示: 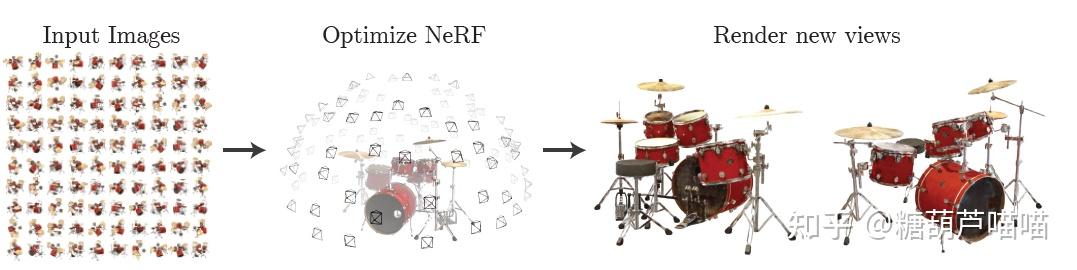 新视角合成(NeRF方法) 新视角合成(NeRF方法)新视角合成在3D重建渲染、VR、AR等领域都有着广泛的应用前景。而发表于2020的论文[2003.08934] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (arxiv.org)无疑是新视角合成领域里程碑式的成果。基于NeRF的新视角合成是一种隐式3D重建技术,它并不要求对3D对象进行实际建模,而是通过学习到的模型来进一步渲染目标姿态下的二维图像(模型学习到的是3D对象的隐式表达)。下面我们先介绍一些NeRF的背景知识: 1.2 如何从2D图像中重建3D空间?首先,我们要解决的是如何处理输入的一组数据:(2D图像,拍摄视角)。我们先考虑这样一个问题:2D图像上的点 (u,v) 在3D场景中如何表达呢? 为了解决这个问题,我们先引入相机坐标系(camera coordinate): 相机坐标系是以相机的光心为原点建立的三维直角坐标系。x轴和y轴与成像平面的x',y'轴平行,z轴为相机光轴,它与成像平面垂直。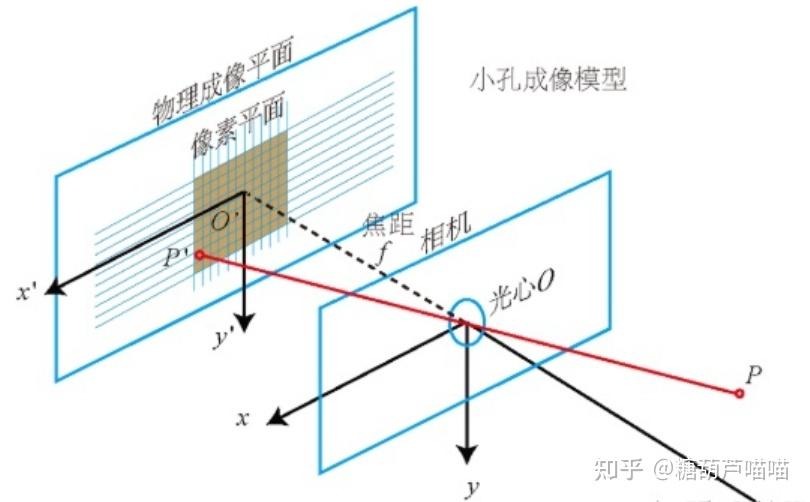 小孔成像原理 小孔成像原理2D图像是以成像平面左上角为原点的图像坐标系(pixel coordinate),它要先转换成以光心在成像平面投影点 (u_0,v_0) 为原点的坐标 (x,y) : u-u_0 = \frac{x}{dx} ,v-v_0 = \frac{y}{dy} , dx,dy 代表每个像素上的实际长度(毫米),为相机固有参数。 根据成像原理,3D物体点 P 通过光心在成像平面上形成像点 P'(x,y),进一步我们可以通过相似三角形原理计算点 P在相机坐标系中的坐标 (X_c,Y_c,Z_c) 。以 X_c 为例,计算如下: \frac{X_c}{Z_c} = \frac{x}{f},\frac{Y_c}{Z_c} = \frac{y}{f} , f 为焦距。进一步转写为矩阵形式: Z_c* \begin{bmatrix} x \\y \\ 1 \end{bmatrix} = \begin{bmatrix} f & 0&0\\0 & f&0 \\ 0 & 0&1\end{bmatrix} \begin{bmatrix} X_c \\Y_c \\ Z_c \end{bmatrix} 两个公式合并得: Z_c* \begin{bmatrix} u \\v \\ 1 \end{bmatrix} = \begin{bmatrix} \frac{f}{dx} & 0&u_0\\0 & \frac{f}{dy}&v_0 \\ 0 & 0&1\end{bmatrix} \begin{bmatrix} X_c \\Y_c \\ Z_c \end{bmatrix} 现在我们得到了将图像坐标系中点 (u,v)转换为相机坐标系中点(X_c,Y_c,Z_c)的方法。中间的矩阵 M_{int} 我们称为相机内参: 相机内参是相机自身特性相关的固有参数,比如相机的焦距、像素大小等结论1:通过相机内参,可以将相机坐标系转换为图像坐标系。现在我们有了3D物体点 P的相机坐标系坐标(X_c,Y_c,Z_c)。显然,这个坐标是与相机相关的,那么现在考虑第二个问题,如何将这个坐标转化为与相机不相关的真实3D空间坐标(即世界坐标系(world coordinate)坐标)呢?显然,三维坐标之间的转换可以通过平移旋转得到,因此我们需要寻找哪里有这个平移旋转信息。 回到我们前面提到的一组数据:(2D图像,拍摄视角),这个“拍摄视角”是什么呢? 拍摄视角:通常由相机外参提供。相机外参是相机在世界坐标系(world coordinate)中的参数,比如相机的位置、旋转方向等。相机外参一般是一个4*4的矩阵 M_{ext} ,其中包含旋转信息和平移信息(而平移信息实际上就是相机光心坐标)。因此,我们可以通过下式计算: \begin{bmatrix}X_c \\Y_c \\ Z_c \\1 \end{bmatrix} = \begin{bmatrix} r_{11} & r_{12}&r_{13}& t_x \\r_{21} & r_{22}&r_{23}& t_y \\ r_{31} & r_{32}&r_{33}& t_z \\ 0 & 0&0& 1 \end{bmatrix} \begin{bmatrix} X \\Y \\ Z\\ 1 \end{bmatrix} ,中间的矩阵即相机外参M_{ext} 结论2:通过相机外参,可以将世界坐标系转换为相机坐标系。结合上面两个结论,我们现在可以利用相机内外参,实现图像坐标系到世界坐标系的转换(注意转换过程中 Z_c 被损失掉了,通俗的说就是3D到2D过程中损失了深度信息)。由于深度信息损失,我们无法获得3D物体实际的世界坐标。这时我们考虑到小孔成像中光线具有沿直线传播的特性,虽然损失了深度信息,但是我们根据求出的世界坐标和相机外参给出的光心坐标仍能计算出通过2D图像坐标的这条光线的表达!即: 给定数据(2D图像,拍摄视角(相机外参))与相机内参,可以计算通过2D图像每一个像素的光线表达。那么,现在我们通过某种方法能够根据这条光线上的信息来计算2D图像每一个像素的颜色就行了,即如何渲染。 1.3 如何对新视角下的3D空间渲染2D图像?NeRF采用体素渲染(Volume Rendering):待渲染2D图像中的每一个像素点都接收来自物体发射(反射)的一束光线,在该光线上采样多个采样点,对每一个采样点的RGB以及体素密度进行积分可得该光线最终RGB: C(r) = \int_{t_n}^{t_f}T(t)\sigma(r(t))c(r(t),d)dt 其中 r(t) 为光线的表达, t 为采样点位置, \sigma(r(t)) 为该采样点体素密度, c(r(t),d) 为该采样点RGB, d 为光线方向向量, T(t)=exp(-\int_{t_n}^{t}\sigma(r(s))ds) 为该采样点累积透光率(即透明度)。该过程可导,因此可以顺利使用反向传播。 也就是说,只要我们能够获得光线上采样点的RGB和体素密度信息,就可以计算光线最终对应的像素点成像颜色。这就是NeRF的主要思路,如下图所示:  NeRF NeRF最后总结下整体思路: 根据相机内参计算焦距f对于每个样本,根据相机外参(目标姿态)计算每个像素点在世界坐标系中坐标,并进一步得到通过每个像素点的光线表达(H*W,5)(5维为 (x,y,z,\theta,\phi) )在每条光线上采样N个采样点(H*W,N,5)训练模型,输出每个采样点的RGB和密度值(H*W,N,4)利用体素渲染公式进行积分,得到每个像素点的RGB(H*W,3),即该样本的2D渲染图像1.4 NeRF实现细节Code【TF】:bmild/nerf: Code release for NeRF (Neural Radiance Fields) (github.com) Code【非官方Pytorch版】:yenchenlin/nerf-pytorch: A PyTorch implementation of NeRF (Neural Radiance Fields) that reproduces the results. (github.com) 训练: 训练过程就是上一节中的思路,最后对每个输出的2D图像和对应输入的图像计算RGB L2 loss即可。这里主要看两个实现细节: Positional Encoding:(sin(2^0 x),cos(2^0 x),sin(2^1 x),cos(2^1 x),…,sin(2^{L-1} x),cos(2^{L-1} x)) 使用高频函数将输入映射到高维空间再传递给网络,可以更好地拟合包含高频变化的数据。对于 x,y,z,L=10 ,对于 \theta,\phi,L=4 (其中 \theta,\phi 实际上是由原点和单位方向向量表示的,维度合计 2*3 )。因此样本点坐标编码后为 3*2*10 维,射线编码后为 2*3*4 维。 Coares-to-Fine:coares网络采用均匀采样,渲染效率低。利用coares网络输出的密度再加权采样,输入到同样结构的fine网络,两个loss相加训练。 推断: 以 \theta 为轴旋转相机,计算每个角度的相机外参输入即可生成旋转视角的视频。 1.5 Instant NGPPaper:[2201.05989] Instant Neural Graphics Primitives with a Multiresolution Hash Encoding (arxiv.org) Code:NVlabs/instant-ngp: Instant neural graphics primitives: lightning fast NeRF and more (github.com) 主要是对NeRF Positional Encoding部分的改变: 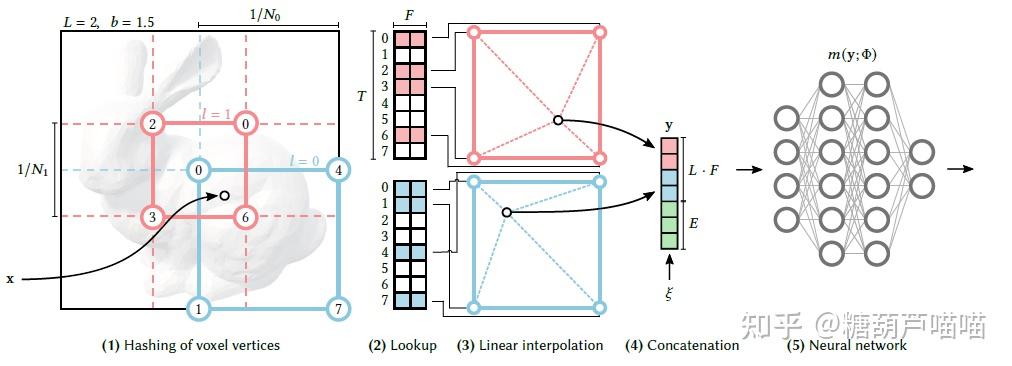 Instant NGP采样点计算不同分辨率下对应分辨框的顶点(2D下是分辨框4顶点,3D下是分辨立方体8顶点) 每个分辨率下都有t个(固定数目)顶点特征(F)顶点特征表,构成,所以精细分辨率下t小于实际顶点数目,因此需要Hash映射至顶点特征表 对每个分辨率下顶点特征(8,F)进行线性插值合并为(F) 拼接不同分辨率特征以及其他特征(L*F+E) 输入MLP二、基于图像渲染的少视角合成 Instant NGP采样点计算不同分辨率下对应分辨框的顶点(2D下是分辨框4顶点,3D下是分辨立方体8顶点) 每个分辨率下都有t个(固定数目)顶点特征(F)顶点特征表,构成,所以精细分辨率下t小于实际顶点数目,因此需要Hash映射至顶点特征表 对每个分辨率下顶点特征(8,F)进行线性插值合并为(F) 拼接不同分辨率特征以及其他特征(L*F+E) 输入MLP二、基于图像渲染的少视角合成上述NeRF系列模型需要多个视角来进行单3D场景的训练,图像信息没有作为输入参与训练。我们是否可以利用图像信息来减少多视角需求,或者说进行通用3D场景训练呢?来看下面几个工作: 2.1 IBRNetPaper:[2102.13090] IBRNet: Learning Multi-View Image-Based Rendering (arxiv.org) Code:googleinterns/IBRNet (github.com) 训练输入相关视角的图像特征,因此可以根据少量相关视角图片训练通用3D场景表达。其主要思路如下图所示:  IBRNet随机选K张相关视角图片 利用Unet计算每个相关角图像特征(K,H,W,32)(文中64维输出一半被用作coares网络训练一半被用作fine网络训练) 图像特征和RGB特征拼接,N个光线采样点利用其在相关视角的投影点坐标进行插值获得相应特征(K,H,W,N,32+3)计算目标渲染视角和相关视角方向向量的差\Delta d作为视角特征(K,3)3和4输入网络,输出采样点RGB(H,W,N,3)和体素密度特征(H,W,N,16)同一光线的采样点体素密度特征(N,16)输入Transformer,输出每个采样点体素密度(N,1)体素渲染成像 IBRNet随机选K张相关视角图片 利用Unet计算每个相关角图像特征(K,H,W,32)(文中64维输出一半被用作coares网络训练一半被用作fine网络训练) 图像特征和RGB特征拼接,N个光线采样点利用其在相关视角的投影点坐标进行插值获得相应特征(K,H,W,N,32+3)计算目标渲染视角和相关视角方向向量的差\Delta d作为视角特征(K,3)3和4输入网络,输出采样点RGB(H,W,N,3)和体素密度特征(H,W,N,16)同一光线的采样点体素密度特征(N,16)输入Transformer,输出每个采样点体素密度(N,1)体素渲染成像文中另一贡献是使用了Transformer,作者认为少量相关视角图像由于特征较少无法准确预测新视角的体素密度,因此采取同一光线采样点输入Transformer,以采样点之间的相关性增强预测能力。 2.2 LFNRPaper:[2112.09687] Light Field Neural Rendering (arxiv.org) Code【jax/flax】:google-research/light_field_neural_rendering at master · google-research/google-research · GitHub 在1.3节中我们介绍了体素渲染是可导的,因此能顺利使用NN。那么,显然,我们也可以用NN来替换这一渲染过程。至于用什么结构,那么Attention is all you need!LFNR采用了两个Transformer结构,其主要贡献: 用Transformer替换了复杂的体素渲染过程。引入极线几何:目标光线在待渲染面上投影是一个点,而目标光线上的采样点在相关视角成像平面中的投影在一条线上,这条线即为极线。如下图所示,目标光线 OX 上采样点 X_1,X_2,... 在相关视角中的投影 X'_1,X'_2,...,它们分别经过相关视角光心 O' 形成的光线 O'X’_1,O'X'_2,... ,其中投影 X'_1,X'_2,... 所在直线为极线。引入光场:空间中光线集合的完备表示。在自由空间中,由于沿光线的辐射保持不变,光线可以由4D向量参数化表达。LFNR采用光板和双球模型对光线进行4D参数化表达。与之前的方法计算采样点编码不同,LFNR计算光线OX以及O'X’_1,O'X'_2,... 的4D参数化编码输入模型。 极线几何 极线几何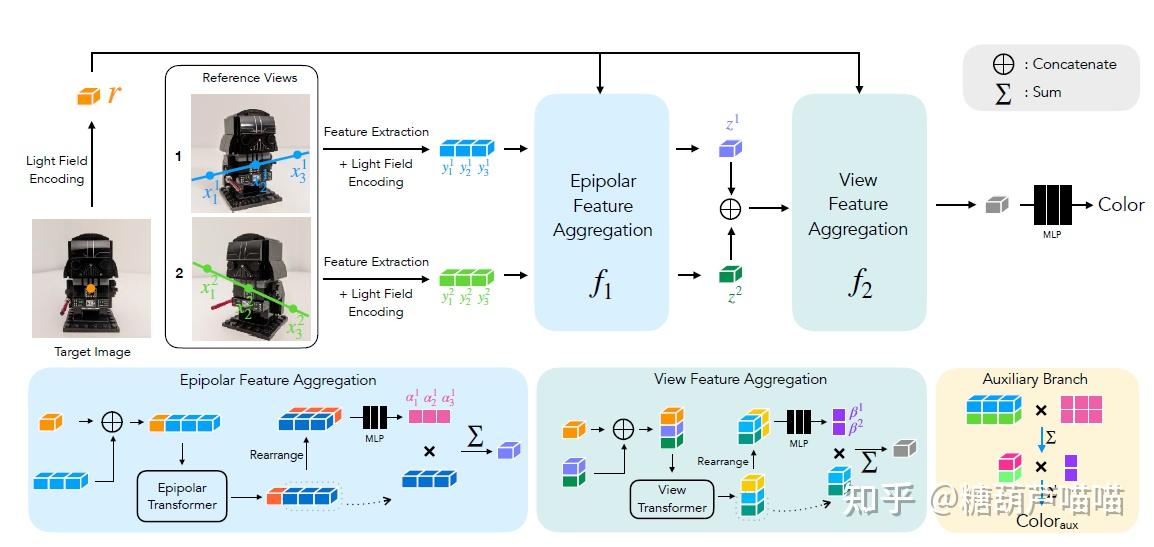 LFNR LFNRLFNR主要过程: 给定目标光线 OX ,计算采样点在相关视角中的光线 O'X_1,O'X_2,... 分别对目标光线(q)和相关视角中的采样点光线(k)计算4D参数化光场向量编码和其他特征(采样点投影图像特征由CNN后插值得到)q与k拼接(K,N+1,dim),输入极线Transformer并取输出的k部分(K,N,dim),进一步计算得到极线聚合特征(N,dim) 极线聚合特征与q拼接 (N+1,dim),输入视角Transformer并取输出的k部分(N,dim),进一步计算相关视角聚合特征(dim),从而预测RGB。2.3 GPNRPaper:[2207.10662] Generalizable Patch-Based Neural Rendering (arxiv.org) Code【jax/flax】:google-research/gen_patch_neural_rendering at master · google-research/google-research · GitHub LFNR的升级版,还是同一批作者,最大的改动就是在极线聚合Transformer前又加了层视觉特征Transformer,至于文中所提在采样点投影附近切片patch,只是将CNN的kernel size变得更大了(LFNR是3,GPNR是11)。整体思路和LFNR一致。 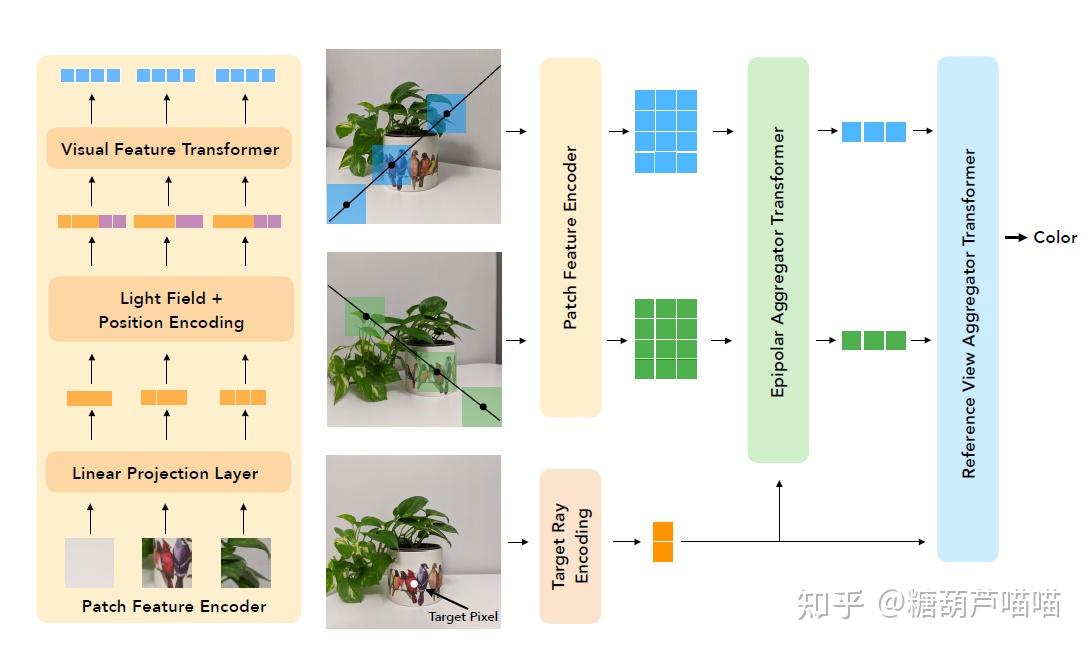 GPNR三、NeRF与Stable Diffusion结合 GPNR三、NeRF与Stable Diffusion结合关于Stable Diffusion的原理请看上一篇文章: Stable Diffusion模型在prompt cond和img cond条件下能够生成高质量的2D图片。能否用SD模型来驱动NeRF训练以帮助我们更好地完成3D渲染工作呢?请看下面两个工作: 3.1 DreamFusionPaper:[2209.14988] DreamFusion: Text-to-3D using 2D Diffusion (arxiv.org) Code【非官方Pytorch版】:ashawkey/stable-dreamfusion: A pytorch implementation of text-to-3D dreamfusion, powered by stable diffusion. (github.com) 第二节中的方法都使用了少量相关视角图像信息作为训练输入(少视角合成),DreamFusion更大胆的使用prompt cond的SD模型驱动NeRF训练进行零视角合成,即只使用prompt来进行3D模型渲染。 DreamFusion中的冻结参数的SD模型只用了prompt cond,主要思路是用随机角度下NeRF渲染新视角图像加随机噪声和Prompt作为SD模型输入,SD模型输出预测噪声计算噪声的损失并反向传播训练NeRF,如下图所示:  DreamFusion DreamFusionDreamFusion主要过程: 【采样】随机产生目标姿态(原点+方向向量)并对光线采样,得到采样点(B,H,W,N,3) 【NeRF】NeRF模型预测采样点RGB和体素密度,并渲染成像(B,H,W,3)【VAE】成像图输入可训练的VAE压缩至潜空间 【Text Encoder】Prompt经过冻结参数的Prompt Eocoder得到Embedding【Unet】压缩后的图像加随机噪声和Prompt Embedding输入Unet,输出预测噪声【Loss】计算噪声的损失函数并反向传播给NeRF3.2 SparseFusionPaper:[2212.00792] SparseFusion: Distilling View-conditioned Diffusion for 3D Reconstruction (arxiv.org) Code:zhizdev/sparsefusion: Official PyTorch implementation of SparseFusion: Distilling View-conditioned Diffusion for 3D Reconstruction (github.com) SparseFusion依然利用相关视角图像做少视角合成,它更像是上述所有工作的集大成者: 使用LFNR/GPNR中的极线聚合Transformer使用DreamFusion中的SD模型驱动NeRF训练使用Instant NGP模型由于不使用prompt cond,SparseFusion中的SD模型去掉了text encoder和unet中的cross attention。与DreamFusion的最大区别在于,SparseFusion将相关视角特征通过如LFNR/GPNR中极线聚合Transformer(EFT)后和随机姿态下Instant NGP渲染的图像在潜空间中拼接作为unet的输入。  SparseFusion SparseFusionSparseFusion主要过程: 【NeRF】对相关视角图像对应姿态经过EFT,输出RGB(B,H,W,3)以及特征图(B,H,W,256)【SD】随机目标姿态输入NeRF渲染图像,VAE压缩潜空间,加随机噪后和1中输出的特征图拼接,输入Unet,输出预测噪声【Loss】计算1中输出的RGB Loss和2中输出的预测噪声Loss,反传NeRF训练AIGC领域在Stable Diffusion及其组件的加持下已经广泛运用在2D图像(视频)生成工作中了。随着NeRF和Stable Diffusion工作的深入结合,更高质量的可控3D场景生成渲染技术也许并不遥远。我们期待着AIGC在3D领域应用中产生更大的技术突破! |
【本文地址】