2D人脸关键点转3D人脸关键点的映射~头部姿态笔记 |
您所在的位置:网站首页 › 三维到二维的映射 › 2D人脸关键点转3D人脸关键点的映射~头部姿态笔记 |
2D人脸关键点转3D人脸关键点的映射~头部姿态笔记
|
本文主要内容
对通过相机参数计算图像上的二维坐标到三维坐标的映射进行简单探讨。 参考资料:学习的话直接看他们的就好,我仅是拾人牙慧,拿GPT写给自己看的,图也是直接搬运的别人画的,以下链接有很完善的理论研究和代码提供。 https://medium.com/@susanne.thierfelder/head-pose-estimation-with-mediapipe-and-opencv-in-javascript-c87980df3acb 在计算机视觉中,相机矩阵(Camera Matrix)是一个重要的参数,它描述了相机的内部参数。相机矩阵通常用于将三维空间中的点投影到二维图像平面上。它定义了图像坐标系和相机坐标系之间的转换关系。 [ fx 0 cx ] [ 0 fy cy ] [ 0 0 1 ] fx 和 fy 是焦距(focal length)在图像坐标系中的缩放因子。它们表示相机在X和Y轴上的焦距,通常以像素为单位。cx 和 cy 是主点(principal point)在图像坐标系中的坐标。主点是图像平面上的光学中心,它通常是图像的中心点,也以像素为单位。相机矩阵的具体值与相机硬件相关,并且可以通过相机校准(Camera Calibration)来获得。相机校准是一个重要的过程,它通过拍摄特定的校准板图案,并结合一些几何和优化算法,来确定相机矩阵和畸变参数,从而提供准确的相机参数,以便进行准确的图像测量和姿态估计等任务。 在给定了相机矩阵后,可以使用它进行图像点到相机坐标系点的转换,或者相机坐标系点到图像点的投影。这在计算机视觉和计算机图形学中都是常见的操作。 相机矩阵与三维坐标通过使用线性代数并将该矩阵乘以物体的三维坐标,就可以在图像中找到它们的坐标。
图像来自最后一个链接:تخمین وضعیت سر با استفاده از Mediapipe - ویرگول。 三维坐标的空间变换:旋转矩阵和平移矩阵三维空间中的任何点都可以通过三分量向量移动,或者绕三个坐标轴旋转三个角度。为此,使用变换矩阵。将变换矩阵乘以点的初始坐标,即可得到变换后的坐标。
例如绕X轴平移或旋转的变换矩阵如下: 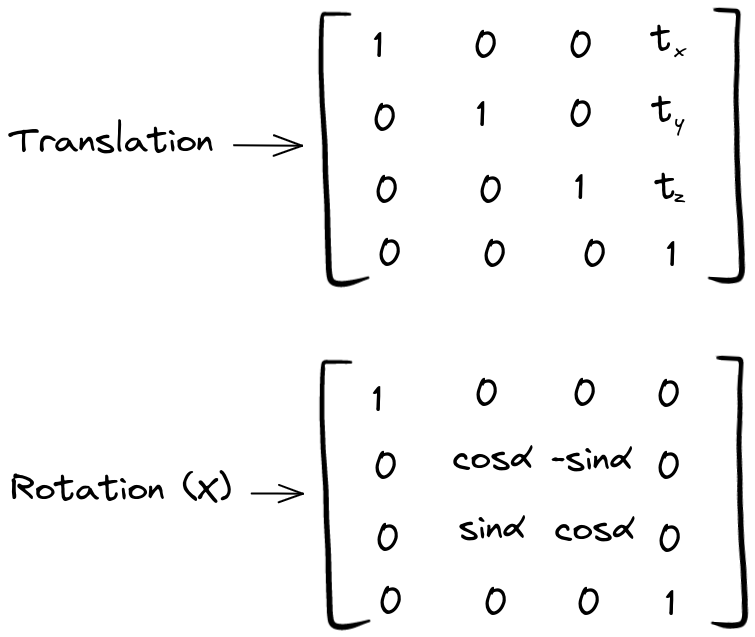
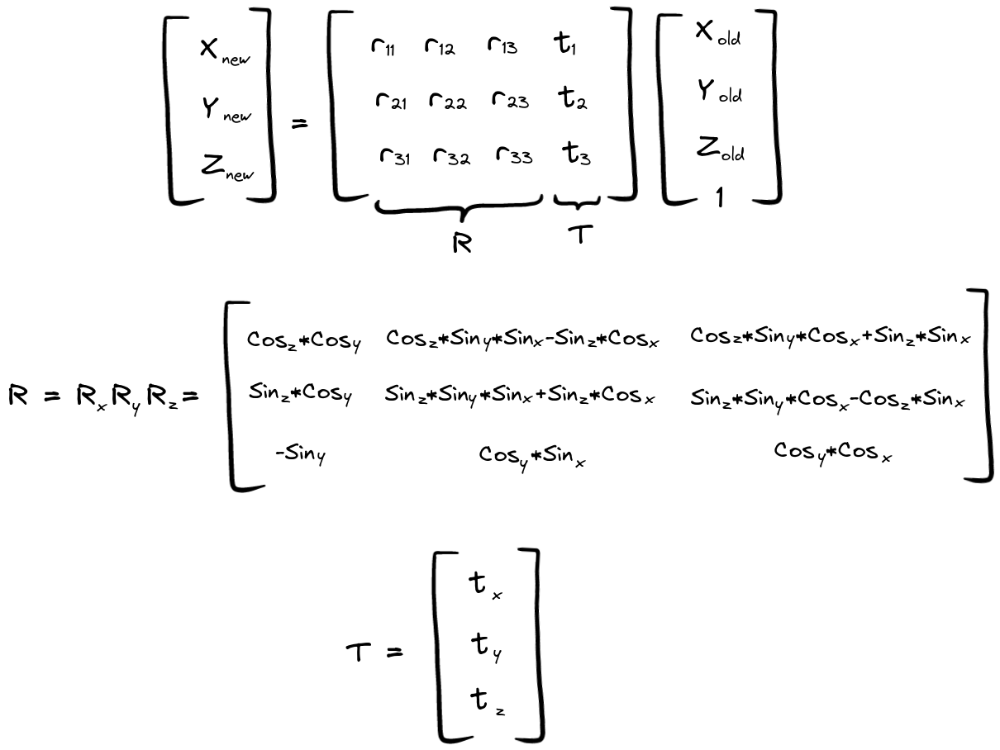
这两个矩阵分别是平移矩阵(Translation Matrix)和旋转矩阵(Rotation Matrix),它们一起描述了相机相对于某个参考坐标系的位置和方向。 平移矩阵(Translation Matrix): 平移矩阵是一个3x1的矩阵,用来描述相机坐标系的原点在参考坐标系(如现实世界坐标系)中的位置。平移矩阵通常用 t 或 T 表示,其中 t = [tx, ty, tz],表示相机坐标系原点相对于参考坐标系原点在X、Y、Z轴方向上的平移量。 旋转矩阵(Rotation Matrix): 旋转矩阵是一个3x3的正交矩阵,用来描述相机坐标系相对于参考坐标系的旋转变换。旋转矩阵通常用 R 表示,它将相机坐标系中的向量映射到参考坐标系中的向量。旋转矩阵有以下几个重要性质: 它的行和列是单位向量,表示相机坐标系的三个轴在参考坐标系中的方向。它的行和列是正交的,即彼此之间互相垂直。它的行和列的模长都为1,因为它表示了旋转变换而不改变向量的长度。可以通过矩阵乘法同时执行绕所有三个轴的平移和旋转操作,如下所示:
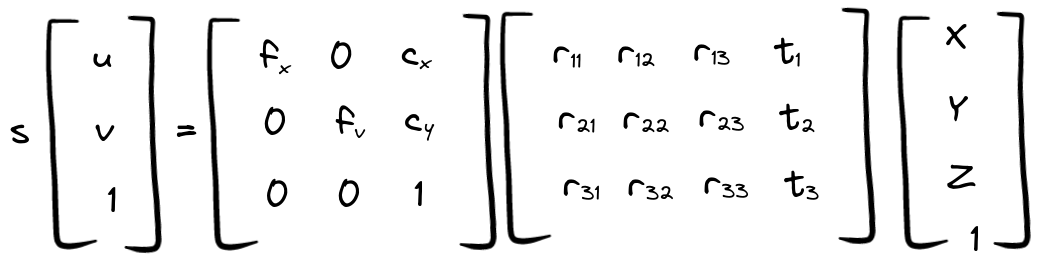
头部姿态问题涉及的是对多个坐标系之间映射的处理问题,这些坐标系分别是: 现实世界坐标系:由 U、V 和 W 轴构成,代表现实世界中的物体坐标。这是物体在现实世界的真实坐标,可以是任意单位,例如米(m)。 相机坐标系:由 X、Y 和 Z 轴构成,代表相机的坐标系。相机坐标系是相对于相机本身的坐标系,其中 X 轴指向右侧,Y 轴指向下方,Z 轴指向相机的观察方向。这个坐标系通常用于描述相机内部的几何属性,如焦距、畸变等。点 P 在相机坐标系中的坐标可以用来描述物体相对于相机的位置。 二维图像坐标系:由 x 轴和 y 轴构成,代表相机拍摄到的二维图像坐标。二维图像坐标是将三维空间中的点投影到相机成像平面上得到的,通常以像素为单位。
将图像中的 3D 坐标转换为 2D 坐标的公式:
我们的目标是找到现实世界中头部的角度或方向。我们知道,当我们将头转向两侧时,实际上相机处于固定位置和方向,头部会改变位置;但我们可以假设头部是固定的,变化的是相机相对于头部的位置和方向。在这种情况下,我们的目标变为寻找旋转矩阵 R。 参数获取如果我们想要估计现实世界中头部的位置,可以使用一个假设的人脸模型,并将一些关键点的坐标作为现实世界中的参考点。这些关键点的坐标需要在所有三个坐标轴上都有变化,以确保估计的准确性。 实现方法所需要使用的点以及他们分别对应的mediapipe mesh坐标,这也是2D世界坐标。 鼻尖右眼外角左眼外角眉间右唇角左唇角 head = [landmark[1], landmark[9], landmark[57], landmark[130], landmark[287], landmark[359]] 相机参数矩阵和失真系数 相机参数矩阵与焦距相机参数通常是与相机类型和相机规格相关的,并且可以通过相机校准来获得。但是,如果没有提供准确的相机参数,我们可以利用图像的长度和宽度作为焦距值,并将图像中心的坐标作为光学焦点的值,来进行一个简单的估计,当然,这是不够严谨的,仅仅是为了表达思想。 # Approximate focal length as half of the image width or height focal_length = (w + h) / 2 # Approximate optical center as the center of the image optical_center = (w / 2, h / 2) # Construct an approximate camera matrix cam_matrix = np.array([[focal_length, 0, optical_center[0]], [0, focal_length, optical_center[1]], [0, 0, 1]]) focal_length = 1 * w cam_matrix = np.array([[focal_length, 0, w / 2], [0, focal_length, h / 2], [0, 0, 1]])以上提供了两种估计方法,在第一种估计中,假设相机的焦距在水平和垂直方向上相等,可以使用图像的宽度(w)和高度(h)的一半来估计焦距(focal_length)。这个假设的焦距值可以用于构造一个近似的相机矩阵(Camera Matrix),第二种则使用图像宽度的一倍作为焦距。 焦距估计的方法评价:使用图像宽度的一倍作为焦距(focal_length = 1 * w): 优点:这种方法简单快速,不需要额外的相机校准步骤,适用于快速原型或简单的应用场景。缺点:这种方法忽略了相机的真实参数和畸变,是一个近似值,可能导致估计的精度较低,尤其在复杂场景中。使用相机校准得到的准确焦距值: 优点:通过相机校准可以得到相机的准确内部参数和外部参数,提供了更精确的相机矩阵,估计结果更可靠和精确。缺点:相机校准过程可能相对复杂,需要拍摄特定的校准板图案,对于某些应用可能增加了额外的工作和成本。如果需要高精度的位姿估计,尤其在复杂场景或精密测量中,建议使用第二种方法,即使用相机校准得到的准确焦距值和相机参数。相机校准可以提供更准确的相机内部参数和外部参数,对于头部姿态估计等任务会有更可靠的结果。 但如果只是进行简单的头部姿态估计、目标跟踪等应用,并且对于精度要求不是非常高,第一种方法即使用图像宽度的一倍作为焦距值可能足够满足需求,而且更加简便快捷。 失真系数(畸变系数)矩阵的估计 dist_matrix = np.zeros((4, 1), dtype=np.float64)畸变系数矩阵是一个4x1的矩阵,它包含相机的径向和切向畸变系数。在这里,畸变系数矩阵被初始化为零,表示没有考虑畸变。如果相机存在畸变,可以通过相机校准等方法来估计得到畸变系数。 这里矩阵的规格是根据之前的计算公式来确立的,也是追求了理想情况做了简化。 图像中的二维坐标矩阵为了给这个矩阵赋值,需要找到图像中的坐标,比如现实世界中的指定点。为此,我们可以使用mediapipe进行实现。 通过指定上述所有矩阵的值,可以使用Lunberg-Marquardt优化找到R和t的最佳值。 真实世界坐标的设置 face_coordination_in_real_world = np.array([ [285, 528, 200], [285, 371, 152], [197, 574, 128], [173, 425, 108], [360, 574, 128], [391, 425, 108] ], dtype=np.float64)在 Mediapipe 库中,它返回的关键点坐标是相对于图像尺寸的归一化坐标(介于 0 和 1 之间),为了将这些归一化坐标转换为像素坐标,需要将它们乘以图像的长度和宽度。 def detect_face_landmarks(image): fps_time = time.time() results = face_mesh.process(image) now = time.time() process_time = (now - fps_time) print('mesh_time:', process_time) face_landmarks = [] if results.multi_face_landmarks: for face in results.multi_face_landmarks: landmarks = [] for landmark in face.landmark: x = int(landmark.x * image.shape[1]) y = int(landmark.y * image.shape[0]) landmarks.append((x, y)) face_landmarks.append(landmarks) return face_landmarks而我们只做头部姿态则只需要这些点:这些也是面部图像中所需点的二维坐标。 head = [landmark[1], landmark[9], landmark[57], landmark[130], landmark[287], landmark[359]] 通过cv2计算旋转矩阵和平移矩阵通过以上数据可以计算旋转矩阵和平移矩阵。 for (landmark_x, landmark_y) in head: x, y = (x1 + landmark_x, y1 + landmark_y) face_coordination_in_image.append([x, y]) face_coordination_in_image = np.array(face_coordination_in_image, dtype=np.float64) success, rotation_vec, transition_vec = cv2.solvePnP( face_coordination_in_real_world, face_coordination_in_image, cam_matrix, dist_matrix)cv2.solvePnP 是 OpenCV 库中的一个函数,用于解决透视投影问题。该函数可以用于估计相机的旋转向量和平移向量,从而得到相机在现实世界中的位姿信息。 retval, rotation_vec, translation_vec = cv2.solvePnP(object_points, image_points, camera_matrix, dist_coeffs[, rvec[, tvec[, useExtrinsicGuess[, flags]]]]) object_points: 真实世界中待估计物体的三维坐标矩阵,是一个 Nx3 的 NumPy 数组,其中 N 是点的数量,每一行包含一个点的 X、Y、Z 坐标。image_points: 相机图像中检测到的物体特征点的二维像素坐标矩阵,是一个 Nx2 的 NumPy 数组,其中 N 是点的数量,每一行包含一个点的像素坐标 (x, y)。camera_matrix: 相机矩阵,它是一个3x3的矩阵,包含了相机的内部参数,如焦距和光学中心。dist_coeffs: 畸变系数矩阵,它是一个4x1的矩阵,包含了相机的径向和切向畸变系数。rvec: 输出的旋转向量,是一个3x1的矩阵,表示相机坐标系相对于现实世界坐标系的旋转。tvec: 输出的平移向量,是一个3x1的矩阵,表示相机坐标系原点相对于现实世界坐标系原点的平移。useExtrinsicGuess: 布尔值,表示是否使用输入的 rvec 和 tvec 作为初始估计值,默认为 False。flags: 用于指定求解 PnP 问题的标志,可以是 cv2.SOLVEPNP_ITERATIVE、cv2.SOLVEPNP_EPNP、cv2.SOLVEPNP_P3P、cv2.SOLVEPNP_DLS 或 cv2.SOLVEPNP_UPNP,具体选择哪个取决于问题的类型和需求。 |
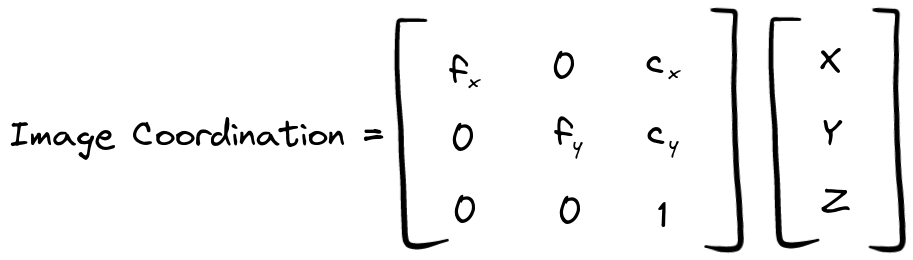

![不同的坐标设备 [1]](https://img-blog.csdnimg.cn/img_convert/a9b9e9330fc336fc2b8452bf86b70a10.jpeg)
【本文地址】