|
本文是视频Python数据分析三剑客 数学建模基础 numpy、pandas、matplotlib的学习笔记。 ————————————————————————————————————————————————————
目录
数据重塑和轴向旋转层次化索引Series的层次化索引:内层选取
通过unstack方法将series变成DataFrame通过stack方法复原
DataFrame的层次化索引设置行列索引选取列交换内外层索引
尝试将电影数据处理成多层索引结构把产地和年代同时设为索引,产地为外层索引,年代为内层索引每个索引都是一个元组取消层次化索引
数据旋转dataframe可以使用stack和unstack,转化为层次化索引的series
数据分组,分组运算按照电影的产地进行分组先定义一个分组变量group可以计算分组后的各个统计量计算平均值求和
计算每年的平均评分传入多个分组变量获得每个地区,每一年的评分的均值
series通过unstack方法转化为DataFrame,没有数据会产生缺失值
离散化处理pd.cut()函数用评分等级将数据分组根据投票人数来刻画电影热门
离散化数据的应用:找出大烂片!找出高分冷门电影!
数据保存
合并数据集1. append()方法2. merge()方法3. concat()方法
第五次课作业(1)读取数据。读取之前作业保存的“酒店数据1.xlsx”(2)将“类型”和“名字”设置为层次化索引,并交换索引的位置。然后将层次化索引取消。(3)将数据集转置,获取转制后的index和columns。(4)用Groupby方法来计算每个地区的评分人数的总和以及均值。(5)用Grouby方法计算每个类型的平均价格,最高价和最低价。(6)数据离散化,按照价格将酒店分为3个等级,0-500为C,500-1000为B,大于1000为A,列名设置为“价格等级”。(7)获取评分均值最高和最低的地区的数据,分别使用append和concat方法将获取的两个数据集合并。(8)数据离散化,按照评分人数将酒店平均分为3个等级,三个等级的酒店数量尽量保持一致。评分人数最多的为A,最少的为C。列名设置为“热门等级”。(9)选出评分人数为A,价格也为A的酒店数据,计算其平均评分。(10)取价格最高的5个酒店的数据,使用stack和unstack方法实现dataframe和Series之间的转换。(11)纵向拆分数据集,分为df1和df2,df1包含名字,类型,城市,地区,df2包含名字,地点,评分,评分人数,价格,价格等级,热门等级。(12)将df2按照价格进行排序,重新设置df2的索引。索引值等于价格排名。(13)使用merge方法将df1和df2合并。(14)将合并后的数据集保存数据到“酒店数据2.xlsx”。
数据重塑和轴向旋转
层次化索引
层次化索引可以使我们在一个轴上拥有多个索引
Series的层次化索引:
s=pd.Series(np.arange(1,10),index=[['a','a','a','b','b','c','c','d','d'],[1,2,3,1,2,3,1,2,3]])
s
a 1 1
2 2
3 3
b 1 4
2 5
c 3 6
1 7
d 2 8
3 9
dtype: int32
s.index
MultiIndex([('a', 1),
('a', 2),
('a', 3),
('b', 1),
('b', 2),
('c', 3),
('c', 1),
('d', 2),
('d', 3)],
)
s['a']
1 1
2 2
3 3
dtype: int32
切片操作:
s['a':'c']
a 1 1
2 2
3 3
b 1 4
2 5
c 3 6
1 7
dtype: int32
内层选取
s[:,1]#内层选取
a 1
b 4
c 7
dtype: int32
s['c',1]
7
通过unstack方法将series变成DataFrame
s.unstack()
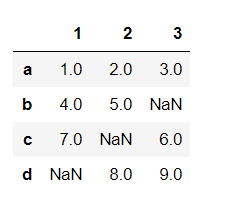
通过stack方法复原
s.unstack().stack()

DataFrame的层次化索引
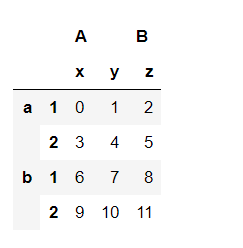
设置行列索引
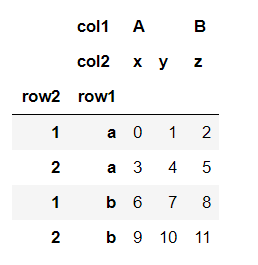
data=pd.DataFrame(np.arange(12).reshape(4,3),index=[['a','a','b','b'],[1,2,1,2]],columns=[['A','A','B'],['x','y','z']])
data
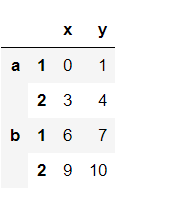
选取列
data['A']
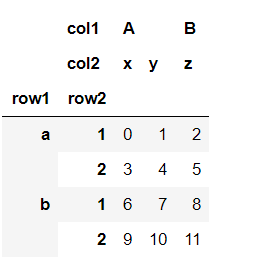
data.columns.names=['col1','col2']#设置列索引名称
data.index.names=['row1','row2']#设置行索引名称
data
交换内外层索引
data.swaplevel('row1','row2')
尝试将电影数据处理成多层索引结构
df.index
Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8,
9,
...
38152, 38153, 38154, 38155, 38156, 38157, 38158, 38159, 38160,
38161],
dtype='int64', length=38162)
把产地和年代同时设为索引,产地为外层索引,年代为内层索引
set_index可以把列变为索引
df=df.set_index(['产地','年代'])
df

reset_index将索引变成列
每个索引都是一个元组
df.index[0]
('美国', 1994)
获取所有的美国电影,因为产地已经成为索引,用.loc方法
df.loc['美国']

df=df.swaplevel('产地','年代')
df
 获取1994年的电影 获取1994年的电影
df.loc[1994]

取消层次化索引
使用reset_index()函数
df=df.reset_index()
df[:5]

数据旋转
行列转化:以前五部电影为例
data=df[:5]
data
 用.T操作可以使数据行列转换(类似于矩阵的转置) 用.T操作可以使数据行列转换(类似于矩阵的转置)
data.T

dataframe可以使用stack和unstack,转化为层次化索引的series
data.stack()
0 年代 1994
产地 美国
名字 肖申克的救赎
投票人数 692795
类型 剧情/犯罪
上映时间 1994-09-10 00:00:00
时长 142
评分 9.6
首映地点 多伦多电影节
1 年代 1957
产地 美国
名字 控方证人
投票人数 42995
类型 剧情/悬疑/犯罪
上映时间 1957-12-17 00:00:00
时长 116
评分 9.5
首映地点 美国
2 年代 1997
产地 意大利
名字 美丽人生
投票人数 327855
类型 剧情/喜剧/爱情
上映时间 1997-12-20 00:00:00
时长 116
评分 9.5
首映地点 意大利
3 年代 1994
产地 美国
名字 阿甘正传
投票人数 580897
类型 剧情/爱情
上映时间 1994-06-23 00:00:00
时长 142
评分 9.4
首映地点 洛杉矶首映
4 年代 1993
产地 中国大陆
名字 霸王别姬
投票人数 478523
类型 剧情/爱情/同性
上映时间 1993-01-01 00:00:00
时长 171
评分 9.4
首映地点 香港
dtype: object
data.stack().unstack()

数据分组,分组运算
GroupBy技术:实现数据的分组,分组运算,作用类似于数据透视表
按照电影的产地进行分组
先定义一个分组变量group
group=df.groupby(df['产地'])
查看类型:
type(group)
pandas.core.groupby.generic.DataFrameGroupBy
可以计算分组后的各个统计量
计算平均值
group.mean()

求和
group.sum()

计算每年的平均评分
df['评分'].groupby(df['年代']).mean()
年代
1888 7.950000
1890 4.800000
1892 7.500000
1894 6.633333
1895 7.575000
...
2013 6.375974
2014 6.249384
2015 6.121925
2016 5.834524
2018 6.935687
Name: 评分, Length: 127, dtype: float64
只会对数值变量进行分组运算!!!
df['年代']=df['年代'].astype('str')
df.groupby(df['产地']).mean()
 求中值 求中值
df.groupby(df['产地']).median()

传入多个分组变量
df.groupby([df['产地'],df['年代']]).mean()

获得每个地区,每一年的评分的均值
group=df['评分'].groupby([df['产地'],df['年代']])
means=group.mean()
means

series通过unstack方法转化为DataFrame,没有数据会产生缺失值
means.unstack().T

离散化处理
在实际数据分析中,对某些数据我们往往并不关心数据的绝对取值,而只关心它所处的区间或等级。 比如可以把评分9分及以上的电影定义为A级,7—9分定义为B级等等
离散化也可以叫做分组,区间化,可以借助函数cut()实现
pd.cut()函数
pd.cut(x,bins,right=True,labels=None,retbins=False,precision=3,include_lowest=False)
参数解释:
x:需要离散化的对象,一般为数值,series,Dataframe对象 bins:分组的依据 right:左区间开闭情况 include_lowest:右区间开闭情况 labels:是否用标记替代分组取值 retbins:返回x对应的bins的列表 precision:设置精度
参考:pd.cut()参数详解
用评分等级将数据分组
labels=['E','D','C','B','A']
df['评分等级']=pd.cut(df['评分'],[0,3,5,7,9,10],labels=['E','D','C','B','A'])
df

根据投票人数来刻画电影热门
同样可以根据投票人数来刻画电影热门,投票越多的热门程度越高
bins=np.percentile(df['投票人数'],[0,20,40,60,80,100])
df['热门程度']=pd.cut(df['投票人数'],bins,labels=['E','D','C','B','A'])
df
 关于np.percentile()函数看这里 关于np.percentile()函数看这里
离散化数据的应用:
找出大烂片!
大烂片:投票人数很多,但评分很低
df[(df['热门程度']=='A')&(df['评分等级']=='E')]

找出高分冷门电影!
df[(df['热门程度']=='E')&(df['评分等级']=='A')]

数据保存
df.to_excel('movie_data3.xlsx')
合并数据集
1. append()方法
先把数据集拆分为多个,再进行合并
df_usa=df[df.产地=='美国']
df_china=df[df.产地=='中国大陆']
df_china.append(df_usa)

2. merge()方法
选6部热门电影
df1=df.loc[:5]
df1

df2=df.loc[:5][['名字','产地']]
df2['票房']=[123456,123545,486213,45684,1213546,15484]
df2

df2=df2.sample(frac=1)
df2

df2.index=range(len(df2))
df2

将df1和df2合并
pd.merge(df1,df2,on='名字')
 因为两个集都存在产地,故合并后有两个产地信息 因为两个集都存在产地,故合并后有两个产地信息
3. concat()方法
可将多个数据集进行批量合并
df1=df[:10]
df2=df[100:110]
df3=df[200:210]
dff=pd.concat([df1,df2,df3])#axis默认为0,在行上进行修改,为1,在列上进行修改
dff
 
第五次课作业
(1)读取数据。读取之前作业保存的“酒店数据1.xlsx”
df=pd.read_excel("酒店数据1.xlsx",index_col=0)
df

(2)将“类型”和“名字”设置为层次化索引,并交换索引的位置。然后将层次化索引取消。
df=df.set_index(['类型','名字'])

df.swaplevel('类型','名字')

df=df.reset_index()
df

(3)将数据集转置,获取转制后的index和columns。
df.T

df.T.index
df.T.columns

(4)用Groupby方法来计算每个地区的评分人数的总和以及均值。
df['评分人数'].groupby(df['地区']).mean()

df['评分人数'].groupby(df['地区']).sum()

(5)用Grouby方法计算每个类型的平均价格,最高价和最低价。
df['价格'].groupby(df['类型']).mean()

df['价格'].groupby(df['类型']).min()

df['价格'].groupby(df['类型']).max()

(6)数据离散化,按照价格将酒店分为3个等级,0-500为C,500-1000为B,大于1000为A,列名设置为“价格等级”。
df['价格等级']=pd.cut(df['价格'],[0,500,1000,df['价格'].max()],labels=['C','B','A'])
df

(7)获取评分均值最高和最低的地区的数据,分别使用append和concat方法将获取的两个数据集合并。
df['评分'].groupby(df['地区']).mean()

df_tm=df[df['地区']=='屯门']
df_kq=df[df['地区']=='葵青']
df_tm.append(df_kq)

df_tm=df[df['地区']=='屯门']
df_kq=df[df['地区']=='葵青']
dff=pd.concat([df_tm,df_kq])
dff
(8)数据离散化,按照评分人数将酒店平均分为3个等级,三个等级的酒店数量尽量保持一致。评分人数最多的为A,最少的为C。列名设置为“热门等级”。
df['热门等级']=pd.cut(df['评分人数'],np.percentile(df['评分人数'],[0,33,66,100]),labels=['C','B','A'])
df

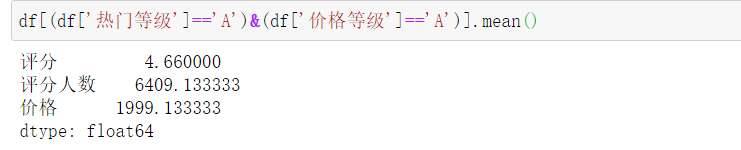
(9)选出评分人数为A,价格也为A的酒店数据,计算其平均评分。
df[(df['热门等级']=='A')&(df['价格等级']=='A')]

df[(df['热门等级']=='A')&(df['价格等级']=='A')].mean()
(10)取价格最高的5个酒店的数据,使用stack和unstack方法实现dataframe和Series之间的转换。
df1=df.sort_values('价格',ascending=False)[:5]
df1.stack()

df1.stack().unstack()

(11)纵向拆分数据集,分为df1和df2,df1包含名字,类型,城市,地区,df2包含名字,地点,评分,评分人数,价格,价格等级,热门等级。
df1=df.loc[:][['名字','类型','城市','地区']]
df1

df2=df.loc[:][['名字','地点','评分','评分人数','价格','价格等级','热门等级']]
df2

(12)将df2按照价格进行排序,重新设置df2的索引。索引值等于价格排名。
df2.sort_values('价格',ascending=False)
df2.index=range(len(df2))
df2

(13)使用merge方法将df1和df2合并。
pd.merge(df1,df2,on='名字')

(14)将合并后的数据集保存数据到“酒店数据2.xlsx”。
df.to_excel('酒店数据22.xlsx')
|