Java操作XML文件及转义字符 |
您所在的位置:网站首页 › 一般转义字符怎么写的 › Java操作XML文件及转义字符 |
Java操作XML文件及转义字符
|
XML转义字符:
eg: 实体必须以符号"&"开头,以符号";"结尾。
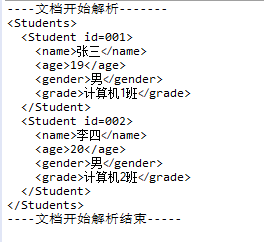
提示:Hutool参考文档 XML工具-XmlUtil 在日常编码中,我们接触最多的除了JSON外,就是XML格式了,一般而言,我们首先想到的是引入Dom4j包,却不知JDK已经封装有XML解析和构建工具:w3c dom。但是由于这个API操作比较繁琐,因此Hutool中提供了XmlUtil简化XML的创建、读和写的过程。 转载1:目录 一、使用DOM4j进行XML的DOM解析 1.1、使用DOM4j查询XML文档 1.2、使用DOM4j修改XML文档 1.3、使用xPath技术 二、使用SAX方式解析XML文档 2.1、使用SAX解析方式查询XML文档 2.2、对比DOM解析和SAX解析 Java中有两种解析XML文件的方式:DOM解析和SAX解析。 一、使用DOM4j进行XML的DOM解析DOM解析是一次性将整个XML文档加载进内存,在内存中构建Document的对象树,通过Document对象,得到树上的节点对象,通过节点对象访问(操作)到XML文档的内容。 通常使用Dom4j工具进行XML的DOM解析,首先要到Dom4j的官网dom4j下载包并加载到IDE开发工具中(例如eclipse)。 1.1、使用DOM4j查询XML文档XML文档在DOM解析中可以被映射为多种节点,其中比较重要和常见的是元素节点(Element)、属性节点(Attribute)和文本节点(Text)。 查询节点主要可以使用以下方法: Document new SAXReader().read(File file) —— 读取XML文档 Element Document.getRootElement() —— 获取XML文档的根元素节点Iterator Element.nodeIterator() —— 获取当前元素节点下的所有子节点Iterator Element.elementIterator(元素名) —— 指定名称的所有子元素节点Iterator Element.attributeIterator() —— 获取所有子属性节点List Element.elements() —— 获取所有子元素节点List Element.attributes() —— 获取所有子属性字节Element Element.element(元素名) —— 指定名称的第一个子元素节点Attribute Element.attribute(属性名) —— 获取指定名称的子属性节点String Element.attributeValue(属性名) —— 获取指定名称的子属性的属性值String Attribute.getName() —— 获取属性名称String Attribute.getValue() —— 获取属性值String Element.getText() —— 获取当前元素节点的子文本节点String Element.elementText(元素名) —— 获取当前元素节点的指定名称的子文本节点示例:在eclipse中读取以下students.xml文档的内容,并打印至控制台 张三 19 男 计算机1班 李四 20 男 计算机2班 package xml; import java.io.File; import java.util.List; import org.dom4j.Attribute; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; public class ReadAndPrintXML { public static void main(String[] args) throws Exception { // 创建一个XML解析器对象 SAXReader reader = new SAXReader(); // 读取XML文档,返回Document对象 Document document = reader.read(new File("E:\\xml\\students.xml")); // 获取根元素节点 Element root = document.getRootElement(); StringBuilder sb = new StringBuilder(); recursion(root, sb); System.out.println(sb.toString()); } private static void recursion(Element ele, StringBuilder sb) { sb.append(""); // 解析文本节点 sb.append(ele.getText()); // 递归解析元素节点 List elements = ele.elements(); for(Element element : elements) { recursion(element, sb); } sb.append("\n"); } } 1.2、使用DOM4j修改XML文档①写出内容到xml文档 XMLWriter writer = new XMLWriter(OutputStream out, OutputFormat format) writer.write(Document doc) 上面的OutputFormat对象可以由OutputFormat类的两个静态方法来生成: createPrettyPrint() —— 生成的OutputFormat对象,使写出的XML文档整齐排列,适合开发环境使用createCompactFormat() —— 生成的OutputFormat对象,使写出的XML文档紧凑排列,适合生产环境使用②生成文档或增加节点 Document DocumentHelper.createDocument() —— 生成一个新的XML Document对象Element Element.addElement(元素节点名) —— 增加一个子元素节点Attribute Element.addAttribute(属性名,属性值) —— 增加一个子属性节点③修改节点 Attribute.setValue(属性值) —— 修改属性节点值Attribute Element.addAttribute(同名属性名,属性值) —— 修改同名的属性节点值Element.setText(内容) —— 修改文本节点内容④删除节点 Element.detach() —— 删除元素节点Attribute.detach() —— 删除属性节点示例:生成一个和前面的students.xml一样的XML文档,并写入到磁盘 import java.io.FileOutputStream; import java.io.UnsupportedEncodingException; import org.dom4j.Document; import org.dom4j.DocumentHelper; import org.dom4j.Element; import org.dom4j.io.OutputFormat; import org.dom4j.io.XMLWriter; public class WriteXML { public static void main(String[] args) throws Exception { // 创建一个XMLWriter对象 OutputFormat format = OutputFormat.createPrettyPrint(); XMLWriter writer = new XMLWriter(new FileOutputStream("E:\\xml\\students2.xml"), format); // 生成一个新的Document对象 Document doc = DocumentHelper.createDocument(); // 增加Students元素节点 Element students = doc.addElement("Students"); // 增加两个Student元素节点 Element student1 = students.addElement("student"); Element student2 = students.addElement("student"); // 为两个Student元素节点分别增加id属性节点 student1.addAttribute("id", "001"); student2.addAttribute("id", "002"); // 分别增加name, age, gender, grade元素子节点 student1.addElement("name").setText("张三"); student1.addElement("age").setText("19"); student1.addElement("gender").setText("男"); student1.addElement("grade").setText("计算机1班"); student2.addElement("name").setText("李四"); student2.addElement("age").setText("20"); student2.addElement("gender").setText("男"); student2.addElement("grade").setText("计算机2班"); // 将Document对象写入磁盘 writer.write(doc); writer.close(); } } 1.3、使用xPath技术使用dom4j查询比较深的层次结构的节点时,比较麻烦,因此可以使用xPath技术快速获取所需的节点对象。 首先也需要在eclipse中导入xPath的jar包,我这里使用的是jaxen-1.1-beta-6.jar ①使用xPath的方法 List Document.selectNodes(xpath表达式) —— 查询多个节点对象Node Document.selectSingleNode(xpath表达式) —— 查询一个节点对象②xPath表达式语法 / —— 绝对路径,表示从xml文档的根位置开始// —— 相对路径,表示不分任何层次结构的选择元素* —— 表示匹配所有元素[] —— 条件,表示选择符合条件的元素@ —— 属性,表示选择属性节点and —— 关系,表示条件的与关系text() —— 文本,表示选择文本内容示例: import java.io.File; import java.util.List; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.Node; import org.dom4j.io.SAXReader; public class XPathTest { public static void main(String[] args) throws Exception { SAXReader reader = new SAXReader(); Document doc = reader.read(new File("E:\\xml\\students.xml")); // 选择所有的student元素 List list = doc.selectNodes("//Student"); // 选择文本内容是"张三"的name元素 Element name = (Element) doc.selectSingleNode("//name[text()='张三']"); // 选择所有id属性节点 List list2 = doc.selectNodes("//@id"); // 选择id属性为002的student元素 Element student = (Element) doc.selectSingleNode("//Student[@id='002']"); // 选择根元素节点的所有子节点 Element root = doc.getRootElement(); List list3 = doc.selectNodes("/Students/*"); } } 二、使用SAX方式解析XML文档SAX方式解析的原理是:在内存中加载一点,读取一点,处理一点。对内存要求比较低。 JDK内置了SAX解析工具,存放在org.xml.sax包中。 2.1、使用SAX解析方式查询XML文档核心的API类: 1、SAXParser.parse(File f, DefaultHandler dh)方法:解析XML文件 参数一File:表示读取的XMl文件 参数二DefaultHandler:SAX事件处理程序,包含SAX解析的主要逻辑。开发人员需要写一个DefaultHandler的子类,然后将其对象作为参数传入parse()方法。 2、 SAXParserFactory类,用于创建SAXParser对象,创建方式如下: SAXParser parse = SAXParserFactory.newInstance().newSAXParser(); 3、DefaultHandler类的主要方法: void startDocument() —— 在读到文档开始时调用 void endDocument() —— 在读到文档结束时调用 void startElement(String uri, String localName, String qName, Attributes attributes) —— 读到开始标签时调用 void endElement(String uri, String localName, String qName) —— 读到结束标签时调用 characters(char[] ch, int start int length) —— 读到文本内容时调用示例:使用SAX解析方式读取上面students.xml的内容,并打印至控制台。 import java.io.File; import javax.xml.parsers.ParserConfigurationException; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; public class SAXTest { public static void main(String[] args) throws Exception { SAXParser parser = SAXParserFactory.newInstance().newSAXParser(); parser.parse(new File("E:\\xml\\students.xml"), new MyDefaultHandler()); } } class MyDefaultHandler extends DefaultHandler{ @Override public void startDocument() throws SAXException { System.out.println("----文档开始解析-------"); } @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { System.out.print(""); } @Override public void characters(char[] ch, int start, int length) throws SAXException { System.out.print(new String(ch, start, length)); } @Override public void endElement(String uri, String localName, String qName) throws SAXException { System.out.print(""); } @Override public void endDocument() throws SAXException { System.out.println("\n----文档开始解析结束-----"); } }
转载自:JAVA对XML文件的读写(有具体的代码和解析 - 杨洛平 - 博客园 XML 指可扩展标记语言(EXtensible Markup Language),是独立于软件和硬件的信息传输工具,应用于 web 开发的许多方面,常用于简化数据的存储和共享。 xml指令 处理指令,简称PI (processing instruction)。处理指令用来指挥解析引擎如何解析XML文档内容。 以下为例: 在XML中,所有的处理指令都以结束。 2 3 4 张三 5 6 男 7 5000 8 9 10 XML解析方式 SAX解析方式SAX(simple API for XML)是一种XML解析的替代方法。相比于DOM,SAX是一种速度更快,更有效的方法。它逐行扫描文档,一边扫描一边解析。而且相比于DOM,SAX可以在解析文档的任意时刻停止解析。 其优缺点分别为:优点: 解析可以立即开始,速度快,没有内存压力缺点: 不能对节点做修改 DOM解析方式DOM:(Document Object Model, 即文档对象模型) 是 W3C 组织推荐的处理 XML 的一种方式。DOM解析器在解析XML文档时,会把文档中 的所有元素,按照其出现的层次关系,解析成一个个Node对象(节点)。其优缺点分别为:优点:把xml文件在内存中构造树形结构,可以遍历和修改节点缺点: 如果文件比较大,内存有压力,解析的时间会比较长 SAXReader读取XML文档使用SAXReader需要导入dom4j-full.jar包。其是DOM4J的一个核心API,用于读取XML文档。 DOM4J是一个Java的XML API,类似于JDOM,用来读写XML文件的。DOM4J是一个非常非常优秀的Java XML API,具有性能优异、功能强 大和极端易用使用的特点,同时它也是一个开放源代码的软件。 1 package day12; 2 3 import java.io.File; 4 import java.util.ArrayList; 5 import java.util.List; 6 7 import org.dom4j.Attribute; 8 import org.dom4j.Document; 9 import org.dom4j.Element; 10 import org.dom4j.io.SAXReader; 11 12 /** 13 * 使用DOM解析xml文档 14 * @author ylg 15 * 16 */ 17 public class ParseXmlDemo { 18 public static void main(String[] args) { 19 try { 20 /* 21 * 解析XML大致流程 22 * 1:创建SAXReader 23 * 2:使用SAXReader读取数据源(xml文档信息) 24 * 并生成一个Document对象,该对象即表示 25 * xml文档内容。DOM耗时耗内存资源也是在 26 * 这一步体现的。因为会对整个XML文档进行 27 * 读取并载入内存。 28 * 3:通过Document对象获取根元素 29 * 4:根据XML文档结构从根元素开始逐层获取 30 * 子元素最终以达到遍历XML文档内容的目的 31 * 32 */ 33 //1 34 SAXReader reader = new SAXReader(); 35 36 //2 37 Document doc 38 = reader.read(new File("emplist.xml")); 39 40 /* 41 * 3 42 * Document提供了方法: 43 * Element getRootElement() 44 * 该方法是用来获取XML文档中的根元素, 45 * 对于emplist.xml文档而言,根元素就是 46 * 标签。 47 * 48 * Element类 49 * 每一个Element实例都可以表示XML文档中的 50 * 一个元素,即:一对标签。 51 */ 52 Element root = doc.getRootElement(); 53 /* 54 * Element提供了方法: 55 * String getName() 56 * 该方法可以获取当前元素的名字(标签名) 57 */ 58 System.out.println( 59 "获取了根元素:"+root.getName() 60 ); 61 //4 62 /* 63 * 获取一个元素中的子元素 64 * Element提供了相关方法: 65 * 66 * 1 67 * Element element(String name) 68 * 获取当前元素下指定名字的子元素。 69 * 70 * 2: 71 * List elements() 72 * 获取当前元素下所有子元素 73 * 74 * 3: 75 * List elements(String name) 76 * 获取当前元素下所有同名子元素 77 * 78 * 2,3返回的集合中的每一个元素都是Element 79 * 的实例,每个实例表示其中的一个子元素。 80 * 81 */ 82 //获取所有emp标签 83 List list = root.elements(); 84 85 //用于保存所有员工信息的List集合 86 List empList = new ArrayList(); 87 88 for(Element empEle : list){ 89 // System.out.println(empEle.getName()); 90 //获取员工名字 91 Element nameEle = empEle.element("name"); 92 /* 93 * Element还提供了获取当前元素中文本的方法: 94 * String getText(),String getTextTrim() 95 */ 96 String name = nameEle.getText(); 97 System.out.println("name:"+name); 98 99 //获取员工年龄 100 int age = Integer.parseInt( 101 empEle.elementText("age") 102 ); 103 104 //获取性别 105 String gender = empEle.elementText("gender"); 106 107 //获取工资 108 int salary = Integer.parseInt( 109 empEle.elementText("salary") 110 ); 111 /* 112 * Attribute attribute(String name) 113 * 获取当前元素(标签)中指定名字的属性 114 * 115 * Attribute的每一个实例用于表示一个 116 * 属性。其中常用方法: 117 * String getName():获取属性名 118 * String getValue():获取属性值 119 */ 120 Attribute attr 121 = empEle.attribute("id"); 122 int id = Integer.parseInt( 123 attr.getValue() 124 ); 125 126 Emp emp = new Emp(id,name,age,gender,salary); 127 empList.add(emp); 128 } 129 System.out.println("解析完毕!"); 130 for(Emp emp : empList){ 131 System.out.println(emp); 132 } 133 134 135 } catch (Exception e) { 136 e.printStackTrace(); 137 } 138 } 139 } 写XML构建Document对象 使用DOM4J我们还可以通过自行构建Document对象,并组建树状结构来描述一个XML文档,并使用DOM4J将其写入一个文件。 1 import java.io.FileOutputStream; 2 import java.util.ArrayList; 3 import java.util.List; 4 5 import org.dom4j.Document; 6 import org.dom4j.DocumentHelper; 7 import org.dom4j.Element; 8 import org.dom4j.io.OutputFormat; 9 import org.dom4j.io.XMLWriter; 10 11 /** 12 * 使用DOM生成XML文档 13 * @author ylg 14 * 15 */ 16 public class WriteXmlDemo { 17 public static void main(String[] args) { 18 List list = new ArrayList(); 19 list.add(new Emp(1,"张三",25,"男",5000)); 20 list.add(new Emp(2,"李四",26,"女",6000)); 21 list.add(new Emp(3,"王五",27,"男",7000)); 22 list.add(new Emp(4,"赵六",28,"女",8000)); 23 list.add(new Emp(5,"钱七",29,"男",9000)); 24 /* 25 * 使用DOM生成XML文档的大致步骤: 26 * 1:创建一个Document对象表示一个空文档 27 * 2:向Document中添加根元素 28 * 3:按照文档应有的结构从根元素开始顺序添加 29 * 子元素来形成该文档结构。 30 * 4:创建XmlWriter对象 31 * 5:将Document对象写出 32 * 若写入到文件中则形成一个xml文件 33 * 也可以写出到网络中作为传输数据使用 34 */ 35 36 //1 37 Document doc 38 = DocumentHelper.createDocument(); 39 40 /* 41 * 2 42 * Document提供了添加根元素的方法: 43 * Element addElement(String name) 44 * 向当前文档中添加指定名字的根元素,返回 45 * 的Element就表示这个根元素。 46 * 需要注意,该方法只能调用一次,因为一个 47 * 文档只能有一个根元素。 48 */ 49 Element root = doc.addElement("list"); 50 51 //3 52 for(Emp emp : list){ 53 /* 54 * Element也提供了追加子元素的方法: 55 * Element addElement(String name) 56 * 调用次数没有限制,元素可以包含若干 57 * 子元素。 58 */ 59 Element empEle = root.addElement("emp"); 60 61 //添加name信息 62 Element nameEle = empEle.addElement("name"); 63 nameEle.addText(emp.getName()); 64 65 //添加age信息 66 Element ageEle = empEle.addElement("age"); 67 ageEle.addText(emp.getAge()+""); 68 69 //添加gender信息 70 Element genderEle = empEle.addElement("gender"); 71 genderEle.addText(emp.getGender()); 72 73 //添加salary信息 74 Element salEle = empEle.addElement("salary"); 75 salEle.addText(emp.getSalary()+""); 76 77 /* 78 * 向当前元素中添加指定名字以及对应值的属性 79 */ 80 empEle.addAttribute("id", emp.getId()+""); 81 82 } 83 try{ 84 //4 85 XMLWriter writer = new XMLWriter(OutputFormat.createPrettyPrint()); 86 FileOutputStream fos 87 = new FileOutputStream("myemp.xml"); 88 writer.setOutputStream(fos); 89 90 //5 91 writer.write(doc); 92 System.out.println("写出完毕!"); 93 writer.close(); 94 }catch(Exception e){ 95 e.printStackTrace(); 96 } 97 } 98 } 注意事项:XPath 路径表达式 XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。由于我们单纯使用dom定位节点时,大部 分时间需要一层一层的处理,如果有了xPath,我们定位我们的节点将变得很轻松。他可以根据路径,属性,甚至是条件进行节点的检索。 XPath 使用路径表达式在XML 文档中进行导航 XPath 包含一个标准函数库 XPath 是 XSLT 中的主要元素 XPath 是一个 W3C 标准 路径表达式语法: 斜杠(/)作为路径内部的分割符。 同一个节点有绝对路径和相对路径两种写法: 路径(absolute path)必须用"/"起首,后面紧跟根节点,比如/step/step/...。 相对路径(relative path)则是除了绝对路径以外的其他写法,比如 step/step, 也就是不使用"/"起首。 "."表示当前节点。 ".."表示当前节点的父节点 nodename(节点名称):表示选择该节点的所有子节点 "/":表示选择根节点 "//":表示选择任意位置的某个节点 "@": 表示选择某个属性 |



【本文地址】
今日新闻 |
推荐新闻 |