随机过程复习(一)概率论基础与随机过程概述 |
您所在的位置:网站首页 › 一维随机变量的分布函数是单调不减的连续函数 › 随机过程复习(一)概率论基础与随机过程概述 |
随机过程复习(一)概率论基础与随机过程概述
|
1. 概率的公理化定义
1.1 概念
随机现象:在一定条件下,可能出现也可能不会出现的现象。随机试验:
(1)试验可在相同条件下重复进行; (2)每次试验只有一个结果出现并且结果不可预知; (3)每次试验所有可能出现的结果已知。 所有试验的可能结果组成的集合称为样本空间,记成
称定义在样本空间 称定义在样本空间 设
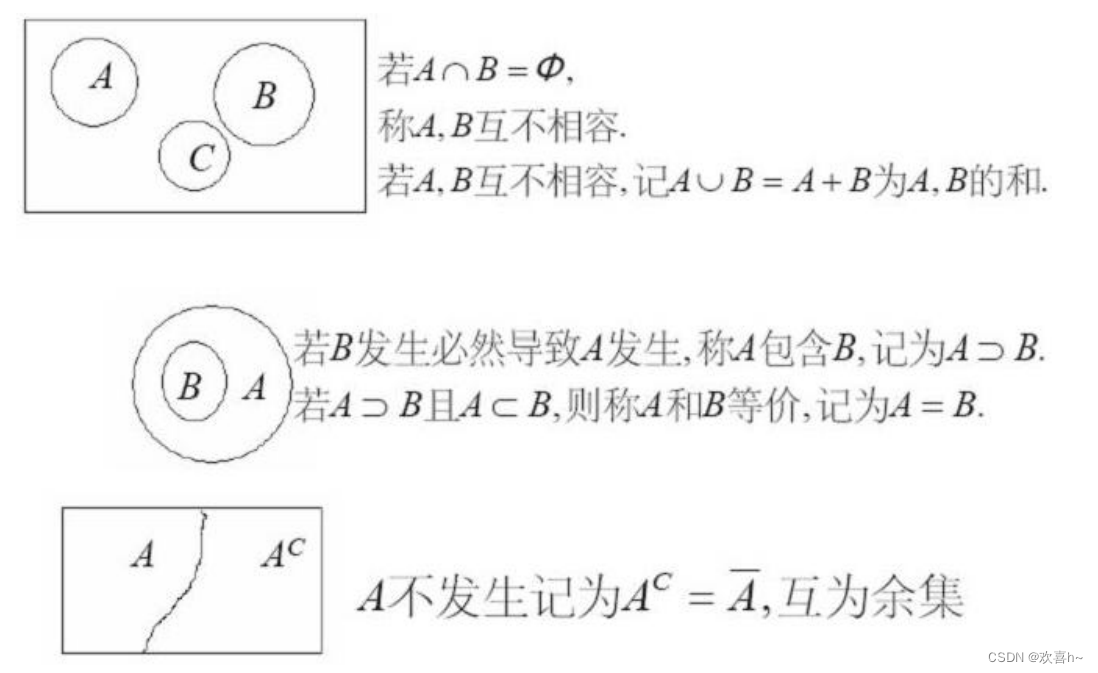
称P为可测空间 概率的性质 5.(若当(Jordan)公式),对任意 设 为在事件B发生的条件下,事件A发生的条件概率。 几个重要的公式: 乘法公式 若 若 若 设 为随机变量X的分布函数。 2.2 示性函数
离散型随机变量和连续性随机变量 若随机变量X的可能取值的全体是一有限集或可数集,则称X是离散型随机变量。 其概率分布用如下分布律描述: 其分布函数为 连续性随机变量X的概率分布常用概率密度f(x)描述,其分布函数为 显然,对连续型随机变量, (1)退化分布 若随机变量X只取常数c,即 (2)伯努利分布 在一次试验中,设事件A出现的概率为p,不出现的概率为1-p,若以X记事件A出现的次数,则X的取值仅为0,1,其对应的概率为 这个分布称为伯努利分布,又称为两点分布。 (3)二项分布 在n重伯努利试验中,设事件A在每次试验中出现的概率均为p,以X记在n次试验中事件A出现的次数,则X的可能取值为0,1,...,n,其对应的概率为 称为以n和p为参数的二项分布,简记为X~B(n,p)。 (4)泊松分布 若随机变量X可取一切非负整数值,并且 称X服从泊松分布,记为X~P( (5)几何分布 在伯努利试验序列中,设事件A在每次试验中出现的概率均为p,以X记事件A首次出现的实验次数,则X的可能取值为1,2,...,其对应的概率为 称为几何分布。 (6)帕斯卡分布 在伯努利试验序列中,设事件A在每次实验中出现的概率均为p,以X记时间A第r次出现的试验次数,则X的可能取值为r,r+1,...,其对应的概率为 称为帕斯卡分布。 (7)离散均匀分布 如果分布律为 则称为离散均匀分布。 (8)连续均匀分布 如果X的密度函数为 则称X为区间[a,b]上的均匀分布。 (9)正态分布 如果密度函数为 则称为参数为 (10)指数分布 如果密度函数为 则称为指数分布。 2.5 数字特征(1)数学期望 离散型随机变量: 连续型随机变量: 一般形式: (2)方差: (3)协方差: (4)相关系数: (5)k阶矩: (1)施瓦兹不等式:若随机变量X,Y的二阶矩存在,则 特别地,有 (2)切比雪夫不等式:对于任一随机变量X,若EX与DX均存在,则对于任意 或 (3)詹森不等式:若g(`)是R上一个凸函数,即 则 (4)马尔可夫不等式:设X是样本空间 设X,Y为两个离散型随机变量,其联合分布律为 为给定 称 为给定 显然, X关于Y的条件数学期望E(X|Y)定义为 其中 上式称为E(X|Y)的示性函数表达式。 由于随机变量E(X|Y)是随机变量Y的函数,故它的数学期望为: 设X,Y均为连续型随机变量,(X,Y)的联合概率密度函数为f(x,y),Y的概率密度函数为 条件分布函数为 条件数学期望为 EX=E{E(X|Y)}可看作数学期望形式的全概率公式。 求条件数学期望的一般步骤: 先写出固定条件(如 设对每一个参数 一般来说,对任意给定的 为随机过程的n维分布函数,简称n维分布。 设 设 为随机过程的协方差函数,记为 (1)正态过程 设 (2)维纳过程 随机过程{W(t), t≥0}为维纳过程,若它满足以下三个性质: 每一个增量W(t+s)-W(s)都为正态分布,且均值为(3)平稳过程 设 则称 若随机过程 (4)独立增量过程 设 则称 (5)计数过程 计数过程又称为点过程,设有一随机过程 (6)泊松过程 对任意t≥0,若N(t)表示时间段[0,t]内事件A发生的次数,且满足如下三个条件: N(0)=0;{N(t), t≥0}为独立增量过程;对任意的t≥0,s≥0,N(s+t)-N(s)服从参数为(7)马尔可夫过程 设 则称 (8)鞅 若对 则称 |
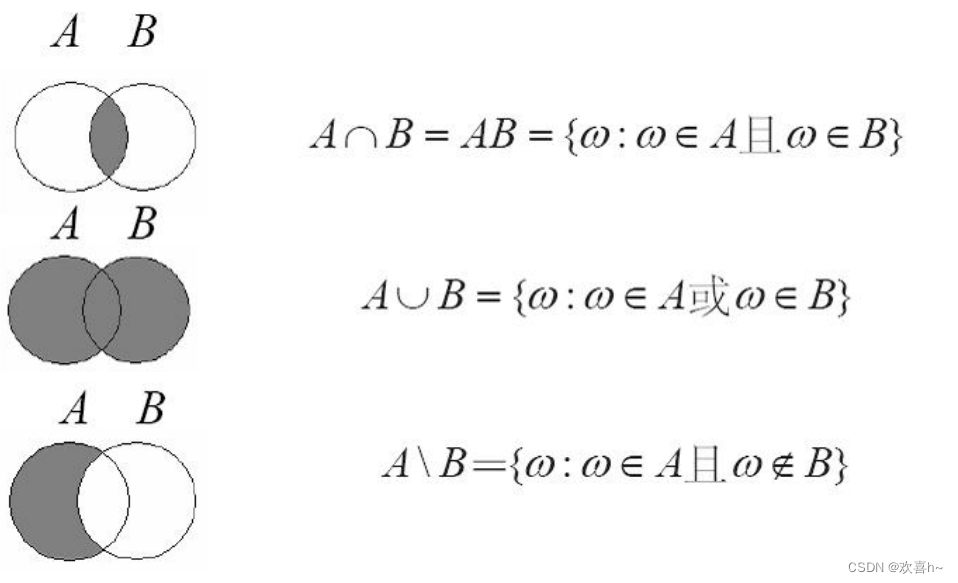



【本文地址】
今日新闻 |
推荐新闻 |