线性模型之二:线性回归模型性能的评估(残差图、MSE与R2) |
您所在的位置:网站首页 › 一元线性回归模型的三种回归方法 › 线性模型之二:线性回归模型性能的评估(残差图、MSE与R2) |
线性模型之二:线性回归模型性能的评估(残差图、MSE与R2)
|
为了获得对模型性能的无偏估计,在训练过程中使用未知数据对测试进行评估是至关重要的。所以,需要将数据集划分为训练数据集和测试数据集,前者用于模型的训练,后者用户模型在未知数据上泛化性能的评估。 对于线性模型
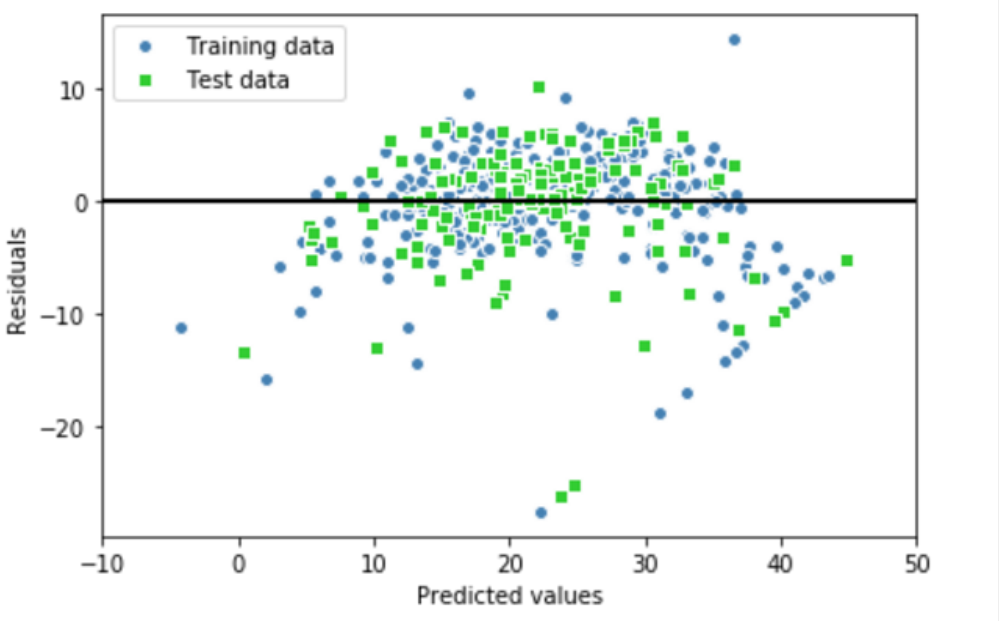
一、残差图 当m>1时,模型使用了多个解释变量,无法在二维坐标上绘制线性回归曲线。那么如何对回归模型的性能有一个直观的评估呢?可以通过绘制预测值的残差图,即真实值和预测值之间的差异或者垂直距离。 残差图作为常用的图形分析方法,可对回归模型进行评估,获取模型的异常值,同时还可以检查模型是否是线性的,以及误差是否随机分布。 通过将预测结果减去对应的目标变量的真实值,便可获得残差值。如下残差图像,其中X轴表示预测结果,Y轴表示残差。其中一条直线 Y=0,表示残差为0的位置。
如果拟合结果准确,残差应该为0。但实际应用中,这种情况通常是不会发生的。但是,对于一个好的回归模型,期望误差是随机分布的,同时残差也随机分布于中心线附近。 如果我们从残差图中找出规律,就意味着模型遗漏了某些能够影响残差的解释信息,就如同看到的残差图那样,其中有这些许规律。此外,还可以通过残差图来发现异常值,这些异常值看上去距离中心线有较大的偏差。 二、均方误差(Mean Squared Error, MSE) 另外一种对模型性能进行定量估计的方法称为均方误差(Mean Squared Error, MSE), 它是线性回归模型拟合过程中,最小化误差平方和(SSE)代价函数的平均值。
三、决定系数(R2) 但是MSE不甚全面,某些情况下决定系数(coefficient of determination)(R2)显得尤为有用,它可以看作是MSE的标准化版本,用于更好地解释模型的性能。R2值的定义如下: 其中,SSE为误差平方和,而 SST反映了真实的y的方差。决定系数R2反映了y的波动有多少百分比能被X的波动所描述,R2的取值范围0~1。然后使用MSE定义R2,
在y变化越剧烈(Var(y)很大)的时候(即大方差)情况下,预测的也很好(MSE会小)的话,则说明模型越好!说明模型对多样性数据的拟合能力比较强! 从另一个角度思考,y的方差越小,说明很相似很集中,当然就更容易拟合 四、综合评估 在度量一个回归模型的好坏时,会同时采用残差图、均方误差MSE和决定系数R2。 1)残差图可以更直观地掌握每个样本的误差分布。 2)MSE的值越小越好,但是不考虑样本本身的分布。 3)R2综合考虑了测试样本本身波动的分布性。 房价数据的附件: boston_house.csv代码实现如下: # In[1] # 从csv载入房价数据 import pandas as pd df = pd.read_csv('boston_house.csv') df.columns = ['row', 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV'] df.drop("row", axis=1, inplace=True) #删除第一列的行号 df.head() # In[2] from sklearn.model_selection import train_test_split X = df.iloc[:, :-1].values y = df['MEDV'].values X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0, test_size=0.3) # In[4] # 开始训练 from sklearn.linear_model import LinearRegression import numpy as np import pandas as pd import matplotlib.pyplot as plt lr = LinearRegression() lr.fit(X_train, y_train) y_train_pred = lr.predict(X_train) #训练数据的预测值 y_test_pred = lr.predict(X_test) #测试数据的预测值 y_train_pred.shape, y_test_pred.shape # In[5] # 绘制散点图 plt.scatter(y_train_pred, y_train_pred - y_train, c='steelblue', marker='o', edgecolor='white', label='Training_data') plt.scatter(y_test_pred, y_test_pred-y_test, c='limegreen', marker='s', edgecolor='white', label='Test_data') plt.xlabel('Predicted values') plt.ylabel('Residuals') plt.legend(loc='upper left') plt.hlines(y=0, xmin=-10, xmax=50, color='black', lw=2) plt.xlim([-10, 50]) # 设置坐标轴的取值范围 plt.tight_layout() plt.show() # In[6] # 计算均方误差MSE、决定系数R2 from sklearn.metrics import r2_score from sklearn.metrics import mean_squared_error print("MSE of train: %.2f, test, %.2f" % ( mean_squared_error(y_train, y_train_pred), mean_squared_error(y_test, y_test_pred))) print("R^2 of train: %.2f, test, %.2f" % ( r2_score(y_train, y_train_pred), r2_score(y_test, y_test_pred))) |
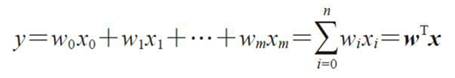
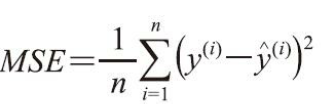
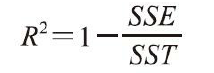
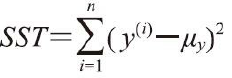
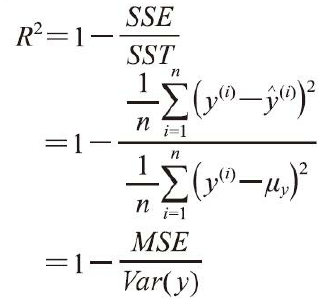
【本文地址】
今日新闻 |
推荐新闻 |