数据指标间相关性分析+假设检验 |
您所在的位置:网站首页 › 一个指标受多个指标影响 › 数据指标间相关性分析+假设检验 |
数据指标间相关性分析+假设检验
|
目录
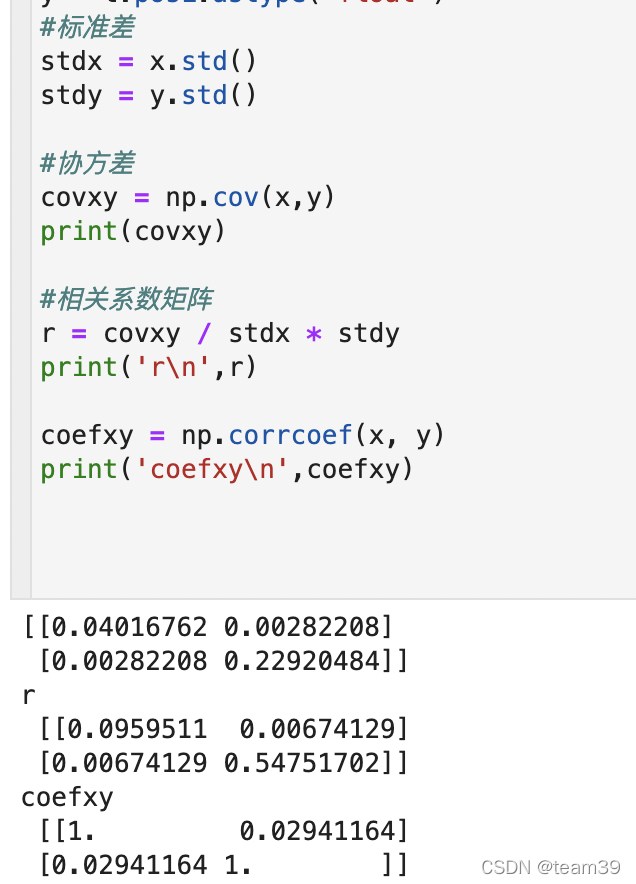
步骤一:可视化-图表展示 步骤二:相关系数计算 1、协方差及协方差矩阵 2、三个相关性系数(pearson, spearman, kendall) 3、不同类型变量适用检验方式 步骤三:假设检验 P值 卡方检验 参数检验——样本符合正态分布: ①T检验——单样本T检验、配对样本T检验、独立样本均数T检验 ②Z检验 ③方差分析ANOVA(F检验)——样本特征大于2 非参数检验 ①Mann-Whitney——U检验 ②Kruskal-Wallis——H检验 ③Wilcoxon有符号秩检验 步骤一:可视化-图表展示折线图、散点图…… 1、单个数据展示,看数据分布、异常值、缺失值…… 2、多数据展示,看数据间关系 步骤二:相关系数计算 1、协方差及协方差矩阵当两个变量变化趋势相同,协方差为正值,说明两变量正相关; 当两个变量变化趋势相反,协方差为负值,说明两变量负相关; 当两个变量相互独立,协方差为0,说明两变量不相关; 两个变量的协方差:
三个变量的协方差:
反应的都是两个变量之间变化趋势的方向以及程度。 Pearson系数(不是p值):皮尔逊相关系数,线性相关系数,协方差与标准差的比值,对数据质量要求较高: ①数据是正态分布时,因为求皮尔森相关性系数以后,通常还会用t检验之类的方法来进行皮尔森相关性系数检验,而 t检验是基于数据呈正态分布的假设的。 ②实验数据之间的差距不能太大,不能有离散点,异常值。 ③连续性变量
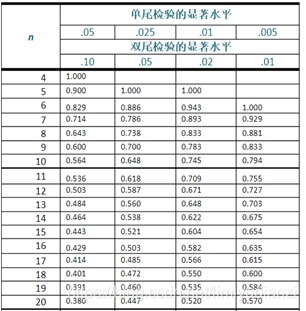
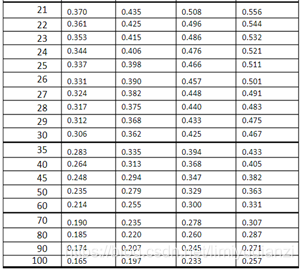
Spearman系数:斯皮尔曼相关性系数,没有很多数据条件要求,当数据不是正太分布,用这个,适用范围广,适合于定序变量或不满足正态分布假设的等间隔数据。 数学建模方法——斯皮尔曼相关系数及其显著性检验 (Spearman’s correlation coefficient for ranked data)_Liu-Kevin的博客-CSDN博客_斯皮尔曼相关性分析 当样本量小于100,相关系数大于等于表中的临界值的时候。我们认为相关系数是有相关性。 Kendall系数:肯德尔相关性系数,又称肯德尔秩相关系数,应用于 分类变量,适合于定序变量或不满足正态分布假设的等间隔数据 【统计学】区分定类、定序、定距、定比变量!!分类变量可以理解成有类别的变量,可以分为 无序的,比如性别(男、女)、血型(A、B、O、AB); 有序的,比如肥胖等级(重度肥胖,中度肥胖、轻度肥胖、不肥胖)。 通常需要求相关性系数的都是有序分类变量。 import pandas as pd draw = pd.DataFrame() print('*Pearson\n',draw.corr()) print('*Spearman\n',draw.corr('spearman')) print('*kendall',draw.corr('kendall'))r值代表相关性强度,取值范围为[-1,1],>0 ,为正相关。0.95 显著性相关>=0.8&=0.5&=0.3& |
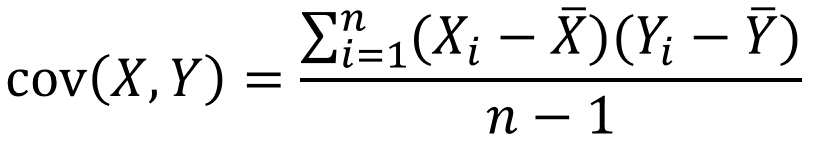
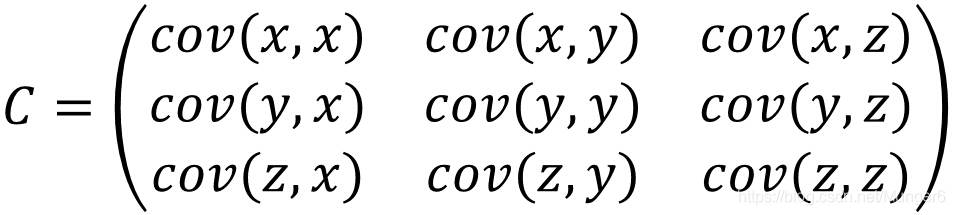

【本文地址】
今日新闻 |
推荐新闻 |