[YOLOv7/YOLOv5系列算法改进NO.17]CNN+Transformer |
您所在的位置:网站首页 › yolo算法和cnn算法 › [YOLOv7/YOLOv5系列算法改进NO.17]CNN+Transformer |
[YOLOv7/YOLOv5系列算法改进NO.17]CNN+Transformer
|
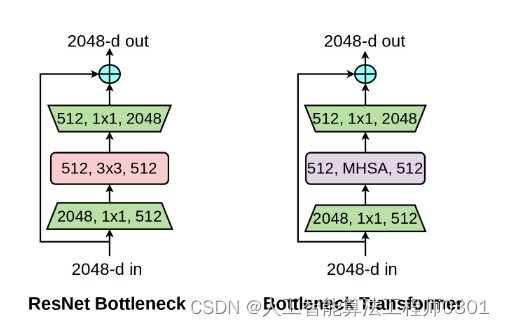
前 言:作为当前先进的深度学习目标检测算法YOLOv5,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv5的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。 解决问题:YOLOv5主干特征提取网络为CNN网络,CNN具有平移不变性和局部性,缺乏全局建模长距离建模的能力,引入自然语言处理领域的框架Transformer来形成CNN+Transformer架构,充分两者的优点,提高目标检测效果,本人经过实验,对小目标以及密集预测任务会有一定的提升效果。 原理: 作者单位:UC Berkeley, 谷歌 论文:https://arxiv.org/abs/2101.1160 GitHub:https://github.com/leaderj1001/BottleneckTransformers BoTNet是一种简单却功能强大的backbone,该架构将自注意力纳入了多种计算机视觉任务,包括图像分类,目标检测和实例分割。通过仅在ResNet的最后三个bottleneck blocks中用全局自注意力替换空间卷积,并且不进行其他任何更改,在目标检测方面显著改善了基线,同时还减少了参数,从而使延迟最小化。
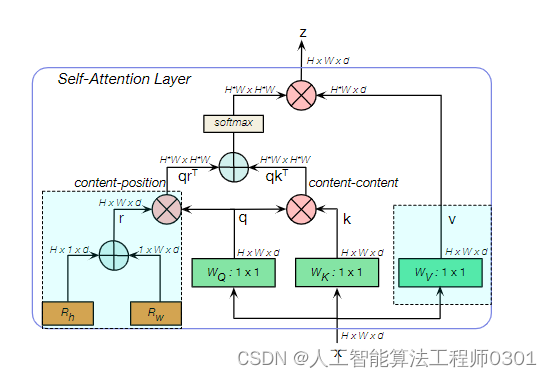
Transformer中的MHSA和BoTNet中的MHSA的区别: 归一化,Transformer使用 Layer Normalization,而BoTNet使用 Batch Normalization。 非线性激活,Transformer仅仅使用一个非线性激活在FPN block模块中,BoTNet使用了3个非线性激活。 输出投影,Transformer中的MHSA包含一个输出投影,BoTNet则没有。 优化器,Transformer使用Adam优化器训练,BoTNet使用sgd+ momentum
方 法: 第一步修改common.py,增加CTR3模块。 class MHSA(nn.Module): def __init__(self, n_dims, width=14, height=14, heads=4,pos_emb=False): super(MHSA, self).__init__() self.heads = heads self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1) self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1) self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1) self.pos=pos_emb if self.pos : self.rel_h = nn.Parameter(torch.randn([1, heads, (n_dims ) // heads, 1, int(height)]), requires_grad=True) self.rel_w = nn.Parameter(torch.randn([1, heads, (n_dims )// heads, int(width), 1]), requires_grad=True) self.softmax = nn.Softmax(dim=-1) def forward(self, x): n_batch, C, width, height = x.size() q = self.query(x).view(n_batch, self.heads, C // self.heads, -1) k = self.key(x).view(n_batch, self.heads, C // self.heads, -1) v = self.value(x).view(n_batch, self.heads, C // self.heads, -1) #print('q shape:{},k shape:{},v shape:{}'.format(q.shape,k.shape,v.shape)) #1,4,64,256 content_content = torch.matmul(q.permute(0,1,3,2), k) #1,C,h*w,h*w # print("qkT=",content_content.shape) c1,c2,c3,c4=content_content.size() if self.pos: # print("old content_content shape",content_content.shape) #1,4,256,256 content_position = (self.rel_h + self.rel_w).view(1, self.heads, C // self.heads, -1).permute(0,1,3,2) #1,4,1024,64 content_position = torch.matmul(content_position, q)# ([1, 4, 1024, 256]) content_position=content_position if(content_content.shape==content_position.shape)else content_position[:,: , :c3,] assert(content_content.shape==content_position.shape) #print('new pos222-> shape:',content_position.shape) # print('new content222-> shape:',content_content.shape) energy = content_content + content_position else: energy=content_content attention = self.softmax(energy) out = torch.matmul(v, attention.permute(0,1,3,2)) #1,4,256,64 out = out.view(n_batch, C, width, height) return out class BottleneckTransformer(nn.Module): # Transformer bottleneck #expansion = 1 def __init__(self, c1, c2, stride=1, heads=4, mhsa=True, resolution=None,expansion=1): super(BottleneckTransformer, self).__init__() c_=int(c2*expansion) self.cv1 = Conv(c1, c_, 1,1) #self.bn1 = nn.BatchNorm2d(c2) if not mhsa: self.cv2 = Conv(c_,c2, 3, 1) else: self.cv2 = nn.ModuleList() self.cv2.append(MHSA(c2, width=int(resolution[0]), height=int(resolution[1]), heads=heads)) if stride == 2: self.cv2.append(nn.AvgPool2d(2, 2)) self.cv2 = nn.Sequential(*self.cv2) #self.bn2 = nn.BatchNorm2d(planes) #self.cv3 = nn.Conv2d(planes, expansion * planes, kernel_size=1, bias=False) #self.bn3 = nn.BatchNorm2d(expansion * planes) #self.shortcut = nn.Sequential() self.shortcut = c1==c2 if stride != 1 or c1 != expansion*c2: self.shortcut = nn.Sequential( nn.Conv2d(c1, expansion*c2, kernel_size=1, stride=stride), nn.BatchNorm2d(expansion*c2) ) self.fc1 = nn.Linear(c2, c2) def forward(self, x): #print("transforme input bottleck shape:",x.shape) # out = F.relu(self.bn1(self.conv1(x))) # out = F.relu(self.bn2(self.conv2(out))) # out = self.bn3(self.conv3(out)) # out += self.shortcut(x) # out = F.relu(out) out=x + self.cv2(self.cv1(x)) if self.shortcut else self.cv2(self.cv1(x)) return out class CTR3(nn.Module): # CSP Bottleneck with 3 convolutions def __init__(self, c1, c2, n=1,e=0.5,e2=1,w=20,h=20): # ch_in, ch_out, number, , expansion,w,h super(CTR3, self).__init__() c_ = int(c2*e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c1, c_, 1, 1) self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2) self.m = nn.Sequential(*[BottleneckTransformer(c_ ,c_, stride=1, heads=4,mhsa=True,resolution=(w,h),expansion=e2) for _ in range(n)]) # self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)]) def forward(self, x): #print("CTR3-INPUT:",x.shape) # return self.cv3 return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))第二步:将yolo.py中注册CTR3模块。 if m in [Conv,MobileNetV3_InvertedResidual,ShuffleNetV2_InvertedResidual,ghostc3,DepthSepConv,CTR3 ]:第三步:进行修改yaml文件 # YOLOv5 🚀 by Ultralytics, GPL-3.0 license # Parameters nc: 80 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple anchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 v6.0 backbone backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, CTR3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ] # YOLOv5 v6.0 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]结 果:本人在多个数据集上做了大量实验,针对不同的数据集效果不同,以及不同位置添加,都会有一定的差异。 预告一下:下一篇内容将继续分享其他Transformer模块的融合。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦 PS:Transformer不仅仅是适用改进YOLOv5,也可以改进其他的YOLO网络以及目标检测网络,比如YOLOv3、v4、v6、v7等。 |
【本文地址】
今日新闻 |
推荐新闻 |