涨点技巧:注意力机制 |
您所在的位置:网站首页 › yolo算法中文名 › 涨点技巧:注意力机制 |
涨点技巧:注意力机制
|
1.计算机视觉中的注意力机制
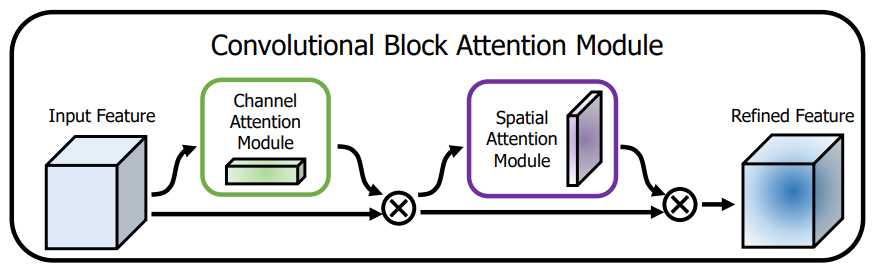
一般来说,注意力机制通常被分为以下基本四大类: 通道注意力 Channel Attention 空间注意力机制 Spatial Attention 时间注意力机制 Temporal Attention 分支注意力机制 Branch Attention 1.1.CBAM:通道注意力和空间注意力的集成者轻量级的卷积注意力模块,它结合了通道和空间的注意力机制模块 论文题目:《CBAM: Convolutional Block Attention Module》 论文地址: https://arxiv.org/pdf/1807.06521.pdf
上图可以看到,CBAM包含CAM(Channel Attention Module)和SAM(Spartial Attention Module)两个子模块,分别进行通道和空间上的Attention。这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。 1.2 GAM:Global Attention Mechanism超越CBAM,全新注意力GAM:不计成本提高精度! 论文题目:Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions 论文地址:https://paperswithcode.com/paper/global-attention-mechanism-retain-information 从整体上可以看出,GAM和CBAM注意力机制还是比较相似的,同样是使用了通道注意力机制和空间注意力机制。但是不同的是对通道注意力和空间注意力的处理。 CBAM结构其实就是将通道注意力信息核空间注意力信息在一个block结构中进行运用。
在resnet中实现cbam:即在原始block和残差结构连接前,依次通过channel attention和spatial attention即可。 1.4性能评价
2.4 GAM加入common.py中加入common.py中 class ResBlock_CBAM(nn.Module): def __init__(self, in_places, places, stride=1, downsampling=False, expansion=4): super(ResBlock_CBAM, self).__init__() self.expansion = expansion self.downsampling = downsampling self.bottleneck = nn.Sequential( nn.Conv2d(in_channels=in_places, out_channels=places, kernel_size=1, stride=1, bias=False), nn.BatchNorm2d(places), nn.LeakyReLU(0.1, inplace=True), nn.Conv2d(in_channels=places, out_channels=places, kernel_size=3, stride=stride, padding=1, bias=False), nn.BatchNorm2d(places), nn.LeakyReLU(0.1, inplace=True), nn.Conv2d(in_channels=places, out_channels=places * self.expansion, kernel_size=1, stride=1, bias=False), nn.BatchNorm2d(places * self.expansion), ) self.cbam = CBAM(c1=places * self.expansion, c2=places * self.expansion, ) if self.downsampling: self.downsample = nn.Sequential( nn.Conv2d(in_channels=in_places, out_channels=places * self.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(places * self.expansion) ) self.relu = nn.ReLU(inplace=True) def forward(self, x): residual = x out = self.bottleneck(x) out = self.cbam(out) if self.downsampling: residual = self.downsample(x) out += residual out = self.relu(out) return out 2.3 CBAM、GAM加入yolo.py中 if m in { Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, C2f,CBAM,ResBlock_CBAM,GAM_Attention}: 2.4 CBAM、GAM修改对应yaml 2.4.1 修改 yolov5s_cbam.yaml # parameters nc: 10 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple # anchors anchors: #- [5,6, 7,9, 12,10] # P2/4 - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 backbone backbone: # [from, number, module, args] # [c=channels,module,kernlsize,strides] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [c=3,64*0.5=32,3] [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, CBAM, [1024,7]], #9 [-1, 1, SPPF, [1024,5]], #10 ] # YOLOv5 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 14 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 18 (P3/8-small) [-1, 1, CBAM, [256,7]], #19 [-1, 1, Conv, [256, 3, 2]], [[-1, 15], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 22 (P4/16-medium) [256, 256, 1, False] [-1, 1, CBAM, [512,7]], [-1, 1, Conv, [512, 3, 2]], #[256, 256, 3, 2] [[-1, 11], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 25 (P5/32-large) [512, 512, 1, False] [-1, 1, CBAM, [1024,7]], [[19, 23, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ] 2.4.2 修改 yolov5s_gam.yaml # parameters nc: 1 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple # anchors anchors: #- [5,6, 7,9, 12,10] # P2/4 - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 backbone backbone: # [from, number, module, args] # [c=channels,module,kernlsize,strides] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [c=3,64*0.5=32,3] [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, GAM_Attention, [1024,1024]], #9 [-1, 1, SPPF, [1024,5]], #10 ] # YOLOv5 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 14 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 18 (P3/8-small) [-1, 1, GAM_Attention, [256,256]], #19 [-1, 1, Conv, [256, 3, 2]], [[-1, 15], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 22 (P4/16-medium) [256, 256, 1, False] [-1, 1, GAM_Attention, [512,512]], [-1, 1, Conv, [512, 3, 2]], #[256, 256, 3, 2] [[-1, 11], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 25 (P5/32-large) [512, 512, 1, False] [-1, 1, GAM_Attention, [1024,1024]], # [[19, 23, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ] |



【本文地址】