Yolov5 seg在图像分割上的落地应用 |
您所在的位置:网站首页 › yolo图像分割原理 › Yolov5 seg在图像分割上的落地应用 |
Yolov5 seg在图像分割上的落地应用
|
yolov5一直作为目标检测的扛把子,训练快、效果好、易部署等优点让从入门小白到行业大佬都对其膜拜不已,而yolov5不仅限于目标检测,现在已经在分类、分割等其他任务上开始发力,这篇文章介绍下yolov5框架在分割任务上的应用以及相关代码的变动。 之前听说yolov5在6版本以上会添加其他的图像任务,今天打开官方github时,发现分类和分割任务已经更新到7.0版本了。今天对分割任务大概梳理一遍。 1 Yolov5-seg的变动 仔细对比yolov5的目标检测与分类的代码框架,主要的改动点在以下几个方面: 1. 训练、测试、验证等的代码入口; 2. 数据加载和预处理; 3. 网络变动; 4. loss的变动; 5. 评价指标。 01训练、测试、验证等的代码入口 yolov5分割任务的训练、测试以及预测的代码入口是在新建的文件夹下: |--segment |--train.py |--val.py |--pred.py三个入口的架构整理上与目标检测保持一致,主要变动在数据集、网络部分、loss和评价指标上。 02 数据加载和预处理 数据预加载上,首先同目标检测的数据格式相同,需要将数据集按照yolo的格式保存,文件夹下面有images和labels两个文件夹,同时在每个文件夹下,分为train/val文件夹: |--dataset_seg |--images |--train |--1.jpg |--2.jpg ....|--val |--111.jpg |--222.jpg .... |--labels |--train |--1.txt |--2.txt .... |--val |--111.txt |--222.txt .... 其中labels文件夹下每张图片对应的标签txt文件,按照每一行为一个mask的格式,通过polygon多个点组成的,按照(标签 第一个点的相对坐标 第二个点的相对坐标 ...)→ label x_point1 y_point1 x_point2 y_point2 ...的格式存储: 58 0.417781 0.771355 0.440328 0.735397 0.467375 0.658995 0.440328 0.605047 0.387719 0.524159 0.378703 0.443248这一点可以在数据加载utils/dataloaders 第1012-1016行看出:
通过create_dataloader处理数据集,并主要通过LoadImagesAndLabelsAndMasks类处理,该类继承了目标检测的LoadImagesAndLabels类,如缓存cache、mixup/moscia等增强方式同目标检测,增加的部分对分割的标签处理,如letterbox 处理后,需要对分割也做对应的平移缩放操作: segments = self.segments[index].copy() if len(segments): for i_s in range(len(segments)): # 将分割的点做相应的移动 segments[i_s] = xyn2xy( segments[i_s], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])同时将分割标签多点组成的polygons转换像素级的mask(utils/dataloaders 第156行): nl = len(labels) # number of labelsif nl: # 标签存在 labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1e-3) # 标签的 if self.overlap: """ 将分割的多个标签保存成一个mask上size(h,w),会加快训练速度。 具体操作: ①先将每行polygon转换成对应图片大小的mask,像素值为1; ②将mask面积从大到小排列,并返回对应的index; ③将面积最大的mask像素赋值为1,第二大的mask像素赋值为2,以此类推,所有mask像素叠加成一层mask;(排序我的理解是为了尽可能避免mask重叠时的溢出) ④并将像素值控制在0到n(label数量)中(防止在下采样中像素点可能会有mask的重叠)。 这样可以将所有的mask保存成一个mask,并后期通过index和masks的像素值解析对应的标签。 """ masks, sorted_idx = polygons2masks_overlap(img.shape[:2], segments, downsample_ratio=self.downsample_ratio) masks = masks[None] # (640, 640) -> (1, 640, 640) labels = labels[sorted_idx] else: """ 如需要将分割的标签保存成nl(标签数量)个mask size:(nl,h,w) """ masks = polygons2masks(img.shape[:2], segments, color=1, downsample_ratio=self.downsample_ratio) masks = (torch.from_numpy(masks) if len(masks) else torch.zeros(1 if self.overlap else nl, img.shape[0] // self.downsample_ratio, img.shape[1] // self.downsample_ratio) 03 网络变动 网络模型上,加载同目标检测网络加载,通过yaml文件对网络搭建,yaml搭建的网络除了head最后一层,前面的基本上和目标检测的网络保持一致,分割网络通过读取yaml文件搭建,SegmentationModel类继承DetectionModel,其对yaml文件的解析方式同目标检测。 class SegmentationModel(DetectionModel): # YOLOv5 segmentation model def __init__(self, cfg='yolov5s-seg.yaml', ch=3, nc=None, anchors=None): super().__init__(cfg, ch, nc, anchors)网络中的Segment分割模块也继承自目标检测中Detect模块,分割模块的head由检测+分割两部分组成: class Segment(Detect): # YOLOv5 Segment head for segmentation models def __init__(self, nc=80, anchors=(), nm=32, npr=256, ch=(), inplace=True): super().__init__(nc, anchors, ch, inplace) self.nm = nm # number of masks self.npr = npr # number of protos self.no = 5 + nc + self.nm # number of outputs per anchor self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv self.proto = Proto(ch[0], self.npr, self.nm) #上采样的protos self.detect = Detect.forward def forward(self, x): p = self.proto(x[0]) # 分割模块 x = self.detect(self, x) #检测模块 return (x, p) if self.training else (x[0], p) if self.export else (x[0], p, x[1])04 loss loss上在分类和检测同目标检测,同时添加了对分割的损失,在分割上的build_target部分,相比于检测考虑anchor正样本划分,分割属于像素级的分类,读取对应目标的index即可。 # Mask regressionif tuple(masks.shape[-2:]) != (mask_h, mask_w): # downsample masks = F.interpolate(masks[None], (mask_h, mask_w), mode="nearest")[0] marea = xywhn[i][:, 2:].prod(1) # mask width, height normalized mxyxy = xywh2xyxy(xywhn[i] * torch.tensor([mask_w, mask_h, mask_w, mask_h], device=self.device)) #mask的长宽与处理的标注保持一致 for bi in b.unique(): j = b == bi # 匹配索引 if self.overlap: mask_gti = torch.where(masks[bi][None] == tidxs[i][j].view(-1, 1, 1), 1.0, 0.0) else: mask_gti = masks[tidxs[i]][j] lseg += self.single_mask_loss(mask_gti, pmask[j], proto[bi], mxyxy[j], marea[j]) 同时采用BCEloss,而图像分割因为属于像素级的分类,如focalloss等,同时图像分割特有的loss如Dice loss等这些还未添加。 def single_mask_loss(self, gt_mask, pred, proto, xyxy, area): # Mask loss for one image pred_mask = (pred @ proto.view(self.nm, -1)).view(-1, *proto.shape[1:]) # (n,32) @ (32,80,80) -> (n,80,80) loss = F.binary_cross_entropy_with_logits(pred_mask, gt_mask, reduction="none")# BCE loss return (crop_mask(loss, xyxy).mean(dim=(1, 2)) / area).mean() # 通过判断mask是否位于预测框内对loss约束 05 评价指标 检测部分同目标检测采用的是ap,而分割部分同样也采用了ap的方式。 stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy if len(stats) and stats[0].any(): results = ap_per_class_box_and_mask(*stats, plot=plots, save_dir=save_dir, names=names) #计算ap metrics.update(results) #更新 nt = np.bincount(stats[4].astype(int), minlength=nc) # number of targets per class 与deteciton稍不同的是,分割预测与实际的IOU的计算方式不同,通过IOU来判断该mask属于TP还是FP,详见val的91-111行。 def process_batch(detections, labels, iouv, pred_masks=None, gt_masks=None, overlap=False, masks=False): """ Return correct prediction matrix Arguments: detections (array[N, 6]), x1, y1, x2, y2, conf, class labels (array[M, 5]), class, x1, y1, x2, y2 Returns: correct (array[N, 10]), for 10 IoU levels """ if masks: if overlap: nl = len(labels) index = torch.arange(nl, device=gt_masks.device).view(nl, 1, 1) + 1 gt_masks = gt_masks.repeat(nl, 1, 1) # shape(1,640,640) -> (n,640,640) gt_masks = torch.where(gt_masks == index, 1.0, 0.0) if gt_masks.shape[1:] != pred_masks.shape[1:]: gt_masks = F.interpolate(gt_masks[None], pred_masks.shape[1:], mode="bilinear", align_corners=False)[0] gt_masks = gt_masks.gt_(0.5) iou = mask_iou(gt_masks.view(gt_masks.shape[0], -1), pred_masks.view(pred_masks.shape[0], -1)) else: # boxes iou = box_iou(labels[:, 1:], detections[:, :4] 而其他的评价指标如dice系数、FWIOU等图像分割的常见指标还未添加。 Yolov5-seg训练及建议 yolov5的分割训练基本同检测任务一样,按照readme上的基本上已经能满足需求。 训练: # Single-GPU python segment/train.py --weights yolov5s-seg.pt --data coco128-seg.yaml --epochs 5 --img 640 # Multi-GPU DDP python -m torch.distributed.run --nproc_per_node 4 --master_port 1 segment/train.py --weights yolov5s-seg.pt --data coco128-seg.yaml --epochs 5 --img 640 --device 0,1,2,3训练后的数据会保存在runs/train-seg文件夹下面:
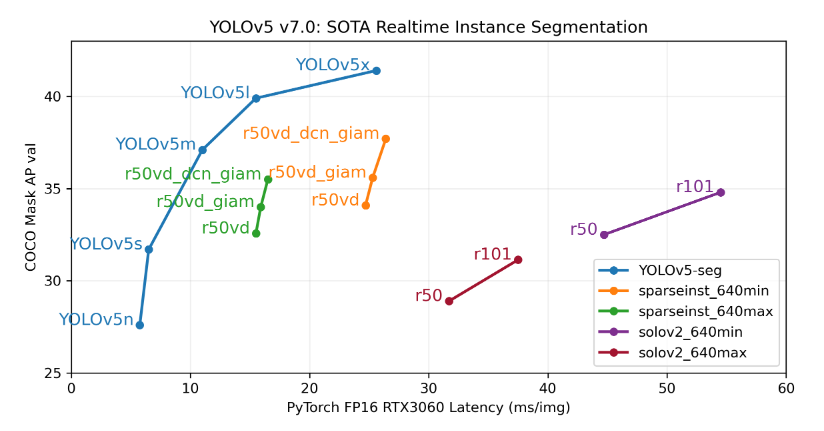
验证: bash data/scripts/get_coco.sh --val --segments # download COCO val segments split (780MB, 5000 images) python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 # validat推理: python segment/predict.py --weights yolov5m-seg.pt --data data/images/bus.jp导出onnx 和 TensorRT: python export.py --weights yolov5s-seg.pt --include onnx engine --img 640 --device 0建议 其在coco上与其他分割网络的效果如下:
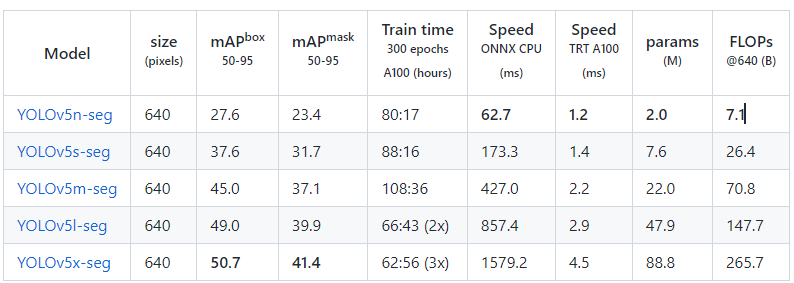
Yolov5模型相比较常见的分割模型,在RTX3060上,FP16模型在coco数据集上确实在推理速度和精度上比其他模型效果好不少,大幅超过cvpr2022dsparseinst等SOTA的效果,这里没有贴yolo与其他模型的其他指标对比,期待后面有更详细的对比,在分割任务的时候建议尝试。 而在yolov5中,几个模型的详细指标如下,由此看出,对于稍微有实时性要求的分割任务,不建议部署在cpu上;如最后的硬件要求是cpu,且算法在部署前需要快速迭代时,则在算法解决方案确定时尽量避免用图像分割。
|


【本文地址】
今日新闻 |
推荐新闻 |