yolov5论文 |
您所在的位置:网站首页 › yolo作者是谁 › yolov5论文 |
yolov5论文
|
导读 YOLO系列是基于深度学习的回归方法,本文详细介绍了从YOLOv1至最新YOLOv5五种方法的主要思路、改进策略以及优缺点。(深度好文,建议点赞收藏哟!) YOLO官网:https://github.com/pjreddie/darknet YOLO v.s Faster R-CNN1.统一网络:YOLO没有显示求取region proposal的过程。Faster R-CNN中尽管RPN与fast rcnn共享卷积层,但是在模型训练过程中,需要反复训练RPN网络和fast rcnn网络.相对于R-CNN系列的"看两眼"(候选框提取与分类),YOLO只需要Look Once. 2. YOLO统一为一个回归问题,而R-CNN将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题)。 YOLOv1论文下载:http://arxiv.org/abs/1506.02640 代码下载:https://github.com/pjreddie/darknet 核心思想:将整张图片作为网络的输入(类似于Faster-RCNN),直接在输出层对BBox的位置和类别进行回归。 实现方法 将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。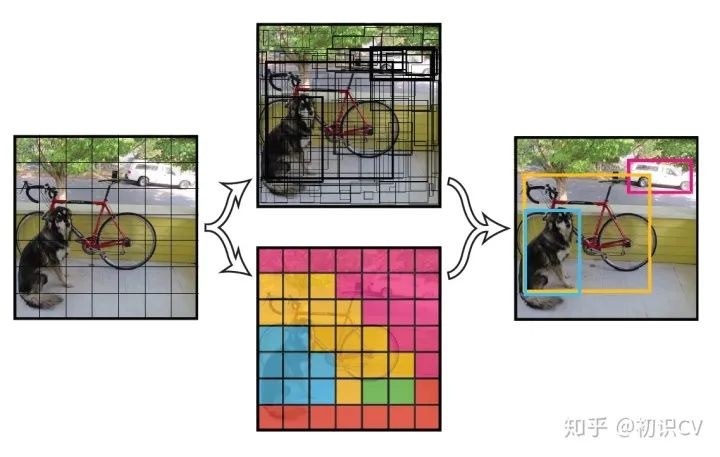 每个网络需要预测B个BBox的位置信息和confidence(置信度)信息,一个BBox对应着四个位置信息和一个confidence信息。confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息:
每个网络需要预测B个BBox的位置信息和confidence(置信度)信息,一个BBox对应着四个位置信息和一个confidence信息。confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息:
其中如果有object落在一个grid cell里,第一项取1,否则取0。第二项是预测的bounding box和实际的groundtruth之间的IoU值。 每个bounding box要预测(x, y, w, h)和confidence共5个值,每个网格还要预测一个类别信息,记为C类。则SxS个网格,每个网格要预测B个bounding box还要预测C个categories。输出就是S x S x (5*B+C)的一个tensor。(注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的。) 举例说明: 在PASCAL VOC中,图像输入为448x448,取S=7,B=2,一共有20个类别(C=20)。则输出就是7x7x30的一个tensor。整个网络结构如下图所示: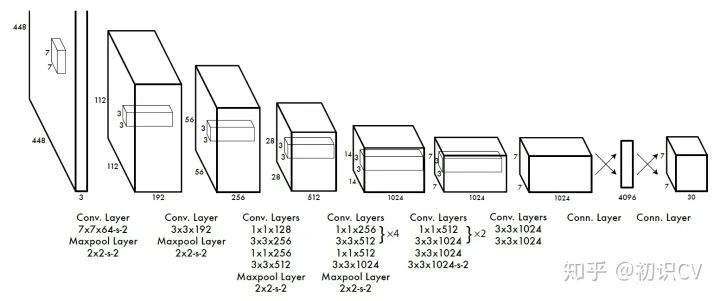 在test的时候,每个网格预测的class信息和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score:
在test的时候,每个网格预测的class信息和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score:
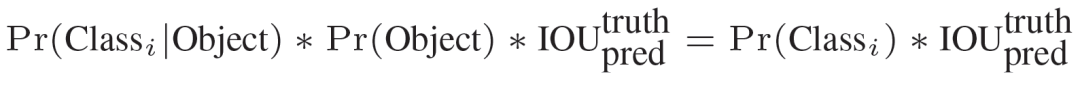
等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。 得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。简单的概括就是: (1) 给个一个输入图像,首先将图像划分成7*7的网格 (2) 对于每个网格,我们都预测2个边框(包括每个边框是目标的置信度以及每个边框区域在多个类别上的概率) (3) 根据上一步可以预测出7*7*2个目标窗口,然后根据阈值去除可能性比较低的目标窗口,最后NMS去除冗余窗口即可 损失函数在实现中,最主要的就是怎么设计损失函数,让这个三个方面得到很好的平衡。作者简单粗暴的全部采用了sum-squared error loss来做这件事。 这种做法存在以下几个问题: 第一,8维的localization error和20维的classification error同等重要显然是不合理的; 第二,如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。解决办法: 更重视8维的坐标预测,给这些损失前面赋予更大的loss weight。 对没有object的box的confidence loss,赋予小的loss weight。 有object的box的confidence loss和类别的loss的loss weight正常取1。对不同大小的box预测中,相比于大box预测偏一点,小box预测偏一点肯定更不能被忍受的。而sum-square error loss中对同样的偏移loss是一样。 为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。这个参考下面的图很容易理解,小box的横轴值较小,发生偏移时,反应到y轴上相比大box要大。(也是个近似逼近方式) 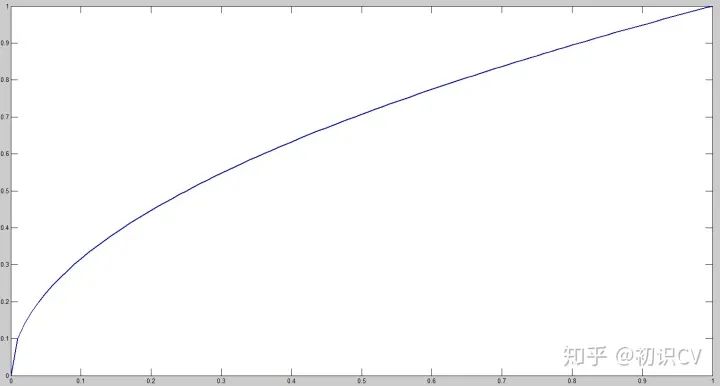
一个网格预测多个box,希望的是每个box predictor专门负责预测某个object。具体做法就是看当前预测的box与ground truth box中哪个IoU大,就负责哪个。这种做法称作box predictor的specialization。 最后整个的损失函数如下所示: 
|

【本文地址】