YOLOV4模型结构及算法解析笔记 |
您所在的位置:网站首页 › yolov4算法原理介绍 › YOLOV4模型结构及算法解析笔记 |
YOLOV4模型结构及算法解析笔记
|
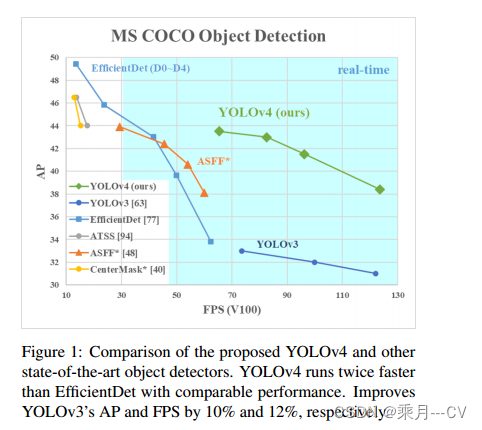
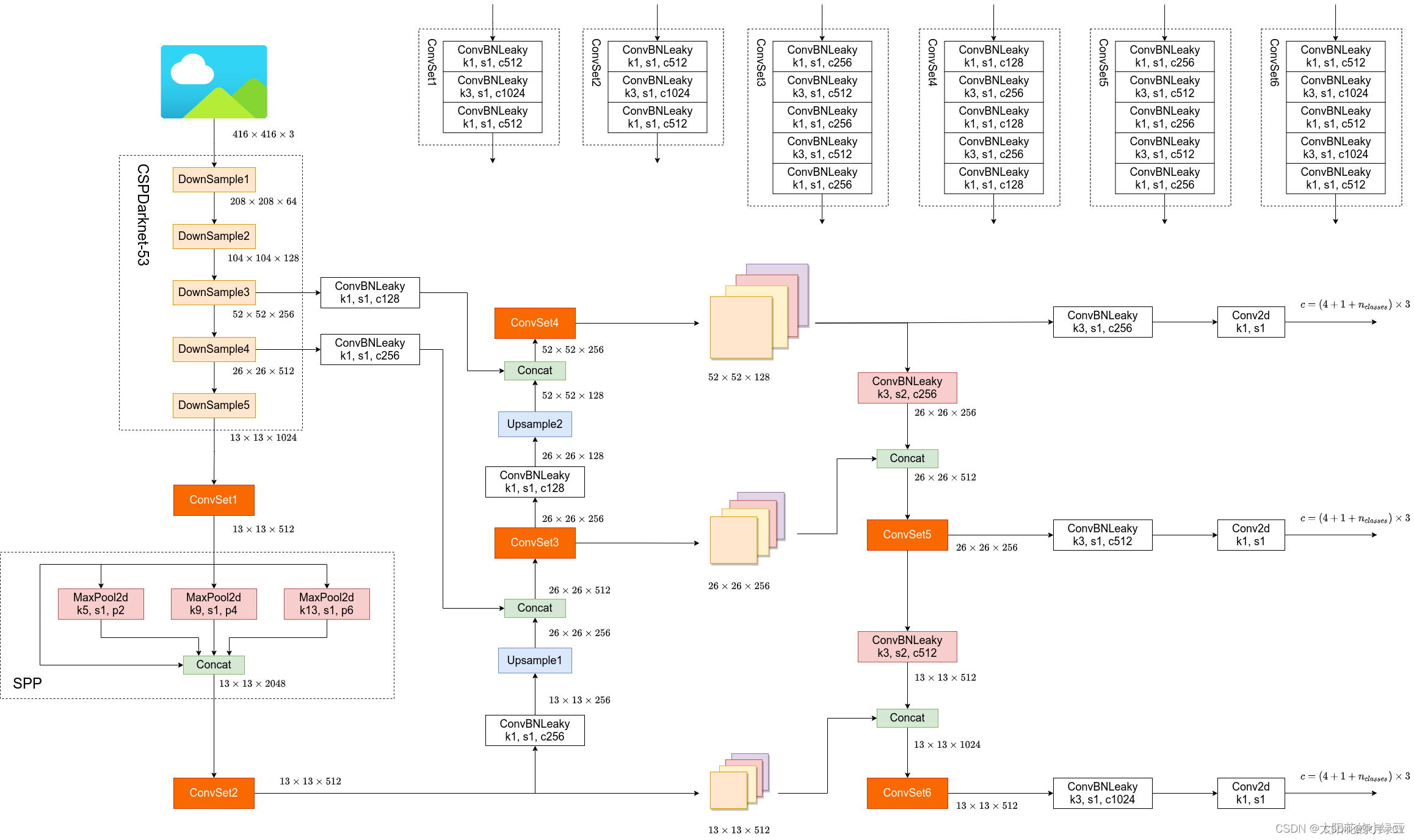
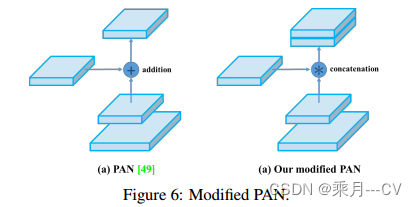
由论文中所给图可知。YOLOV4相比于YOLOV3在速度和精度上均有很大的提升。 首先介绍YOLOV4的整体框架,它的各个部分是: Backbone: CSPDarknet53 Neck: SPP , PAN Head: YOLOv3 网络结构图参考:YOLOv4网络详解_yolov4网络结构图-CSDN博客 如图: 其中YOLOV4中的PAN结构与原始的PAN相比而不同之处在于,YOLOv4中是通过在通道方向Concat拼接的方式进行融合的。如图,两个128通道的特征图经过concat拼接变成256通道的特征图。
下图是PAN的结构图,其中PAN是FPN多加了一个自底向上的concat得到的。
下面介绍优化策略: (1)训练Backbone时采用的优化策略: 跟据论文中4.2节可知,当采用CutMix,Mosaic,Label Smoothing,Mish时CSPDarknet-53的Top-1,Top-5精度达到最高,因此我们通过引入CutMix和Mosaic数据增强、类标签平滑和Mish激活等特征,提高了分类器的准确性。
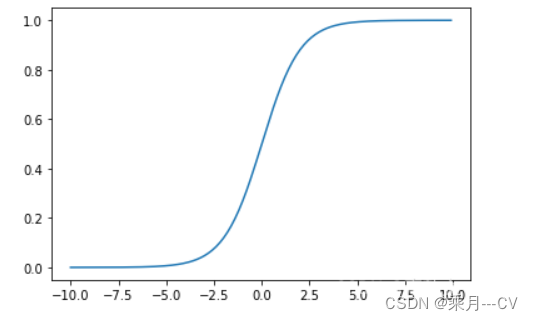
(2)训练检测器: Eliminate grid sensitivity(消除网格敏感度) 对于YOLOV3中的预测框坐标:bx=σ(tx)+cx,by=σ(ty)+cy 其中: tx是网络预测的目标中心x 坐标偏移量(相对于网格的左上角)ty是网络预测的目标中心y 坐标偏移量(相对于网格的左上角)cx是对应网格左上角的x坐标cy是对应网格左上角的y坐标σ是sigmoid激活函数,将预测的偏移量限制在0到1之间,即预测的中心点不会超出对应的Grid Cell区域YOLOV4边界框预测与YOLOV3基本不变,一些区别在于,由于sigmoid函数的特性,当真实框在网格左上角或者右下角时,tx的值需要趋近于0或者1,因此通过将sigmoid乘以超过1.0的因子来解决这个问题,从而消除了无法检测到对象的网格的影响。sigmoid函数如下图:可知网络的预测值需要负无穷或者正无穷时才能取到网格左上角或者右下角,而这种很极端的值网络一般无法达到。
因此引入了一个大于1的缩放系数,虽然引入这个缩放系数之后,预测对象的坐标不在限制在网格内,但是可以很容易预测在网格左上角和右下角的坐标,并且引入缩放系数之后,仍能够在网格附近预测边界框。通过缩放后网络预测中心点的偏移范围已经从原来的( 0 , 1 ) 调整到了( − 0.5 , 1.5 ) 。
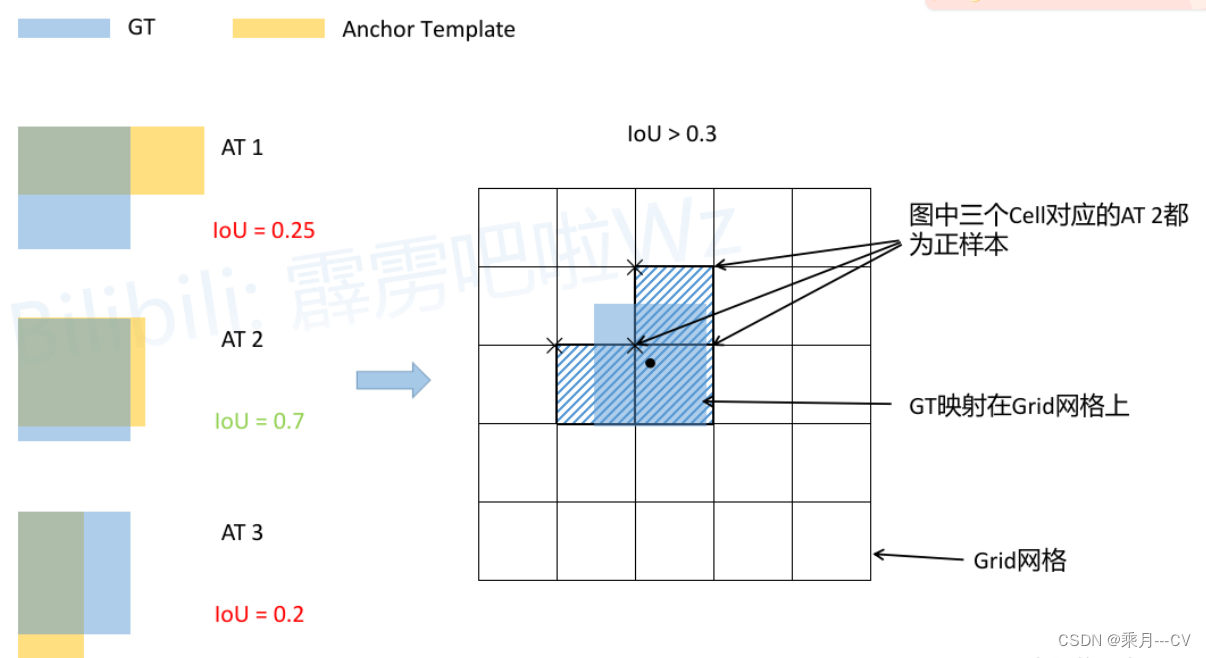
(3)正样本匹配: 这里简单叙述一下样本匹配问题,通过缩放后网络预测中心点的偏移范围已经从原来的( 0 , 1 ) 调整到了( − 0.5 , 1.5 ) ,因此预测框的范围扩大了,所以对于同一个GT Boxes可以分配给更多的Anchor(每个grid cell负责产生三个Anchor),不同的grid cell可以预测同一种类别的对象,然后通过筛选得到最优的预测框,即正样本的数量更多了。然而在训练时跟据IOU的大小筛选出IOU最大的GT作为预测框,并不断训练优化预测框大小及坐标。 |


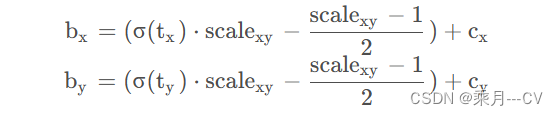
【本文地址】
今日新闻 |
推荐新闻 |