3步制作Python自动化报表的方法!助力高效处理数据! |
您所在的位置:网站首页 › xlwings与openpyxl优缺点 › 3步制作Python自动化报表的方法!助力高效处理数据! |
3步制作Python自动化报表的方法!助力高效处理数据!
|
人生苦短,我用python。 相信做过报表的都对其烦不胜烦,周报,月报,季报;一期期的报表,一次次的心酸泪,烦不胜烦。至于作者是怎么知道的,因为我也是这个苦逼报表大军的一员。 是这样的,当时参与公司的一个项目,我的任务是出报表,听到任务时,心中顿时乐开了花,呜呼,这个简单,不就是出个报表吗。So easy!可拿到历史数据做成的表格顿时就不淡定了,一共是6个excel,每个excel是4-5个sheet,每个sheet里还有一堆花花绿绿的表格需要填写,心里顿时不淡定了。完成整个任务之后,唯一感觉到的是,痛苦麻木。 之后通过网络查询资料,发现这个报表居然可以自动化。接着花了一个星期的时间将报表自动化,当最后一个表格自动化代码写完后,打开python,运行程序,不得不说,一个字爽,再也不用一点一点的往sheet里弄数据了。
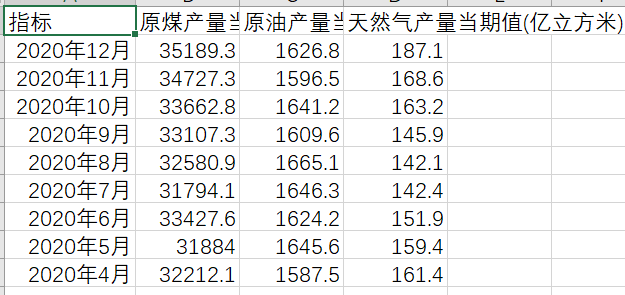
好了,接下来就为大家介绍今天的主角,xlwings。 先简单的看一下最终生成的表格效果吧。
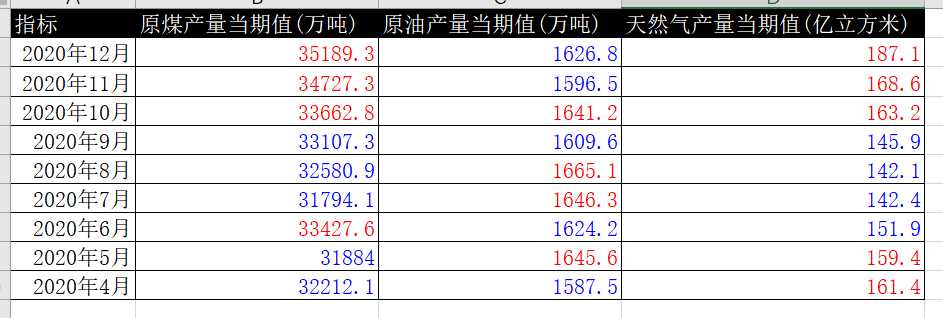
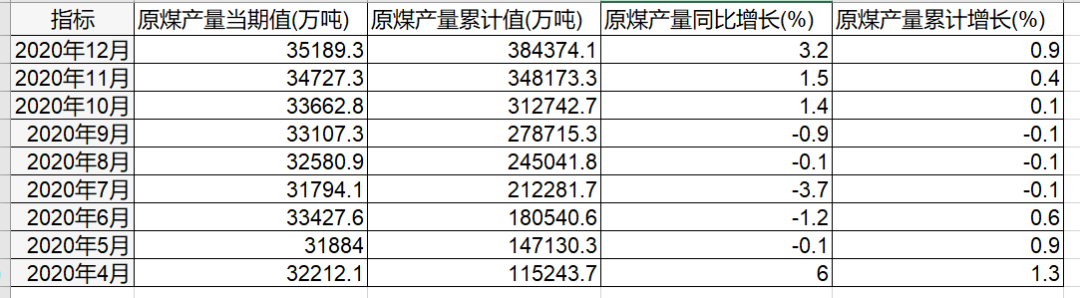
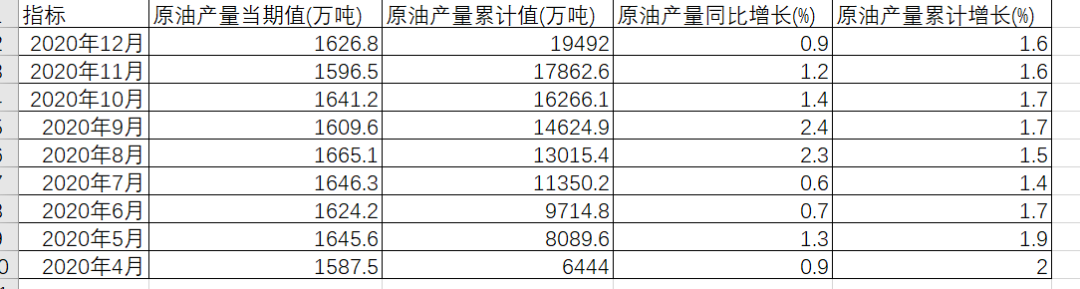
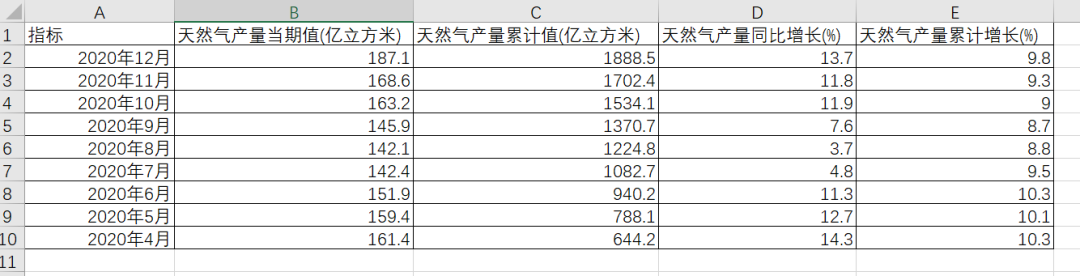
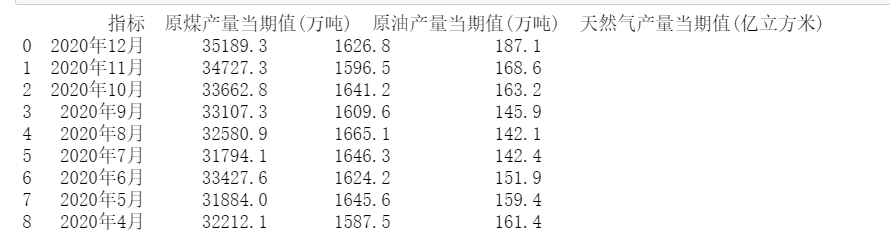
下面我们就来看看这个案例吧。 以下是我们的原始数据,一共以三个sheet,每个sheet,这三个sheet分别是原煤,原油,天然气的数据。,指标有产量当期值,产量累计值,产量同比增长,产量累计增长。 这些数据都是可以在国家统计局里下载出来的,有兴趣的小伙伴可以自行下载。这个案例是让我们将数据以上表格的形式输出,指标名称是白色,单元格是黑色,此外数据中,红色是大于平均值进行得标注,蓝色是小于平均值进行的标注,表格字体为宋体。
首先呢,先导入相关库,用python读取原始数据。 import pandas as pd import xlwings as xw raw_coal=pd.read_excel(r'统计局数据.xlsx',sheet_name='原煤') crude_oil=pd.read_excel(r'统计局数据.xlsx',sheet_name='原油') natural_gas=pd.read_excel(r'统计局数据.xlsx',sheet_name='天然气') data=pd.merge(raw_coal,crude_oil,on='指标') data=pd.merge(data,natural_gas,on='指标') finally_data=data[['指标','原煤产量当期值(万吨)','原油产量当期值(万吨)','天然气产量当期值(亿立方米)']] print(finally_data)
就数据而言,已经离我们要的最终表格差的不远了,就差一点点细节了。 是时候上我们的主角xlwings,xlwings能够非常方便的读写excel文件中的数据,最重要的是它可以对单元的格式进行修改,可以与pandas无缝连接。 使用xlwings库创建一个excel工作簿,在工作簿中创建一个表,表的名称为finally_data。 然后将上面利用pandas整合的数据复制到finally_data表格中,当然了将数据复制到表格中,在此看来有三种方式。 第一种:将一个数据看成一个单位,一个一个写入创建的表格中,此时需要注意的是,每一个数据在excel的位置和在dataframe表格中的位置,以免出现错误。 第二种:将一行数据看成一个单位,此时需要注意的是,每行数据的第一个在excel中的位置,参考复制粘贴形式。 第三种:将一张表的数据看成一个单位,本质上与第二种没什么区别,都是切片式传入数据,但是第三种方法是一二维数组的形式写入。 wb=xw.Book() sht=wb.sheets['Sheet1'] sht.name='finally_data' columns=list(finally_data.columns)##得到列名 sht.range('A1').value = columns####在第一行复制列名 ##第一种方式,将一个数据为单位,一个个写入创建的表格中 # for row in range(2,11): # for col in range(1,5): # sht.range(row,col).value =finally_data.iloc[row-2,col-1] ##第二中方式,将一行数据为单位,一行一行的写入创建的表格中 # for i in range(0,len(finally_data)): # data_row=list(finally_data.iloc[i,:]) # row=i+2 # row_clo='A'+str(row) # sht.range(row_clo).value =data_row #第三种方式,将一张表格为单位,直接写入创建的表格中 finally_data1=finally_data.values sht.range('A2').value = finally_data1
三者均能达到我们想要结果,各有优劣,作者喜欢的是第三种。达到这一步的时候,剩下的就是对表格内单元格的格式进行修改了。 再对单元格进行修改之前,我们要先求出来原煤产量当期值,原油产量长期值,天然气产量当期值,这三列数据中大于平均值和小于平均值的数据在Dataframe的位置,同时得出该数据在excel的位置,方便在进行单元格的格式修改。 describe=finally_data.describe() avg=list(describe.loc['mean',:]) ##计算大于均值的数在excel的位置 red_原煤=list(finally_data.index[finally_data['原煤产量当期值(万吨)']>avg[0]]) red_position1=['B'+str(i+2) for i in red_原煤 ] red_原油=list(finally_data.index[finally_data['原油产量当期值(万吨)']>avg[1]]) red_position2=['C'+str(i+2) for i in red_原油 ] red_天然气=list(finally_data.index[finally_data['天然气产量当期值(亿立方米)']>avg[2]]) red_position3=['D'+str(i+2) for i in red_天然气 ] red=red_position1+red_position2+red_position3 ##计算小于均值的数在excel的位置 blue_原煤=list(finally_data.index[finally_data['原煤产量当期值(万吨)'] |


【本文地址】
今日新闻 |
推荐新闻 |