【python量化】搭建一个CNN |
您所在的位置:网站首页 › wynn股票价格 › 【python量化】搭建一个CNN |
【python量化】搭建一个CNN
|
写在前面 下面的这篇文章主要教大家如何搭建一个基于CNN-LSTM的股票预测模型,并将其用于股票价格预测当中。原代码在文末进行获取。 1 CNN-LSTM模型 这篇文章将带大家通过Tensorflow框架搭建一个基于CNN-LSTM的简单股票价格预测模型,这个模型首先是将一个窗口的股票数据转换为一个2D的图像数据,然后通过CNN进行特征提取。具体地,定义一段股票序列为:
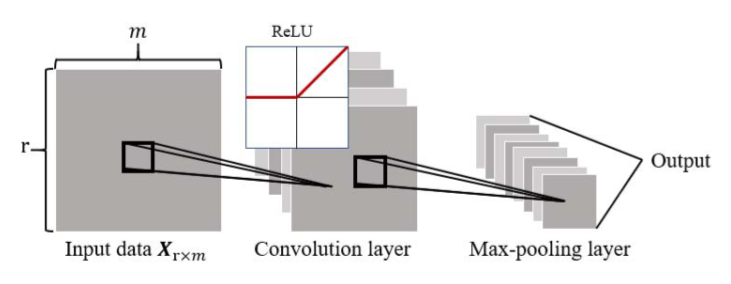
其中,每个x是一个m维的向量,这样得到的就是一个r乘m的矩阵形式,因此对于这个矩阵可以通过CNN进行特征提取。文中,通过64个filter来进行特征提取,之后通过Relu函数进行激活,接着通过max-pooling进行池化处理,最后加入了概率为0.3的dropout来防止过拟合。最后输出一段序列作为后面LSTM的输入。然后通过LSTM对得到的feature map进行时序建模。如下图所示:
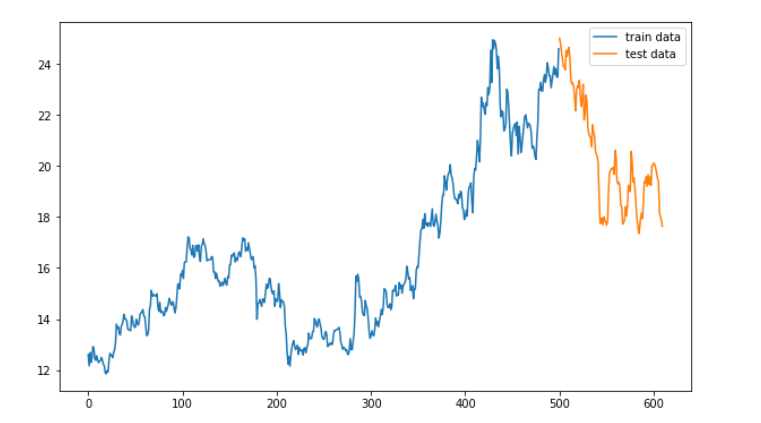
本文只是通过这样一个简单的基本模型,带大家梳理一下数据预处理,模型构建以及模型评估的流程。模型还有很多可以改进的地方,例如特征提取部分选择更有意义的特征等。 2 环境准备 本地环境: Python 3.7 IDE:Jupyter库版本: numpy 1.18.1 pandas 1.0.3 sklearn 0.22.2 matplotlib 3.2.1 tensorflow 2.3.1 tushare 1.2.7然后,导入需要用到的所有库: import tushare as ts import numpy as np import pandas as pd import matplotlib.pyplot as plt import tensorflow as tf from tensorflow import keras from sklearn.preprocessing import MinMaxScaler3 代码实现 1. 数据获取 我们首先通过tushare获取股票数据,这里以中国平安的日线数据为例。用到的数据包括开高低收以及交易量,最后将数据保存至本地。数据获取代码如下: # 获取中国平安三年内K线数据 data = ts.get_hist_data('000001') data.index = pd.to_datetime(data.index) data = data[['open', 'high', 'close', 'low', 'volume']] data = data[::-1].reindex() data.to_csv('./data.csv')得到的数据形式如下: open high close low volume 0 12.72 12.91 12.60 12.50 975450.81 1 12.52 12.58 12.16 12.05 1557151.62 2 12.34 12.75 12.68 12.10 1192399.00 3 12.33 12.54 12.30 12.23 741917.75 4 12.20 12.75 12.49 12.16 1182598.12 .. ... ... ... ... ... 605 19.33 19.73 19.39 19.01 841490.25 606 19.37 19.49 18.18 17.99 1997690.50 607 18.10 18.24 18.03 17.85 1114972.00 608 18.08 18.10 17.87 17.80 983410.94 609 17.85 18.00 17.64 17.57 1096039.88 [610 rows x 5 columns]2.数据预处理 接下来需要对数据进行预处理,包括窗口化以及训练集和测试集的划分等。首先定义一个窗口划分的函数: # 窗口划分 def split_windows(data, size): X = [] Y = [] for i in range(len(data) - size): X.append(data[i:i+size, :]) Y.append(data[i+size, 2]) return np.array(X), np.array(Y)之后划分训练集和测试集,其中前500条数据用于模型训练,后面的数据用于模型测试。具体地,我们用到了开高低收以及交易量数据来预测下一时刻的收盘价数据集。 df = pd.read_csv('./data.csv', usecols=['open', 'high', 'close', 'low', 'volume']) all_data = df.values train_len = 500 train_data = all_data[:train_len, :] test_data = all_data[train_len:, :] plt.figure(figsize=(12, 8)) plt.plot(np.arange(train_data.shape[0]), train_data[:, 2], label='train data') plt.plot(np.arange(train_data.shape[0], train_data.shape[0] + test_data.shape[0]), test_data[:, 2], label='test data') plt.legend()训练数据和测试数据如下图所示:
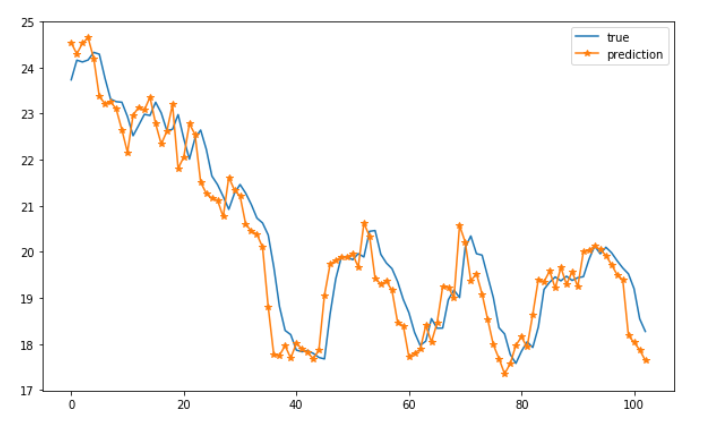
接下来对数据进行归一化处理: # normalizatioin processing scaler = MinMaxScaler() scaled_train_data = scaler.fit_transform(train_data) scaled_test_data = scaler.transform(test_data) # 训练集测试集划分 window_size = 7 train_X, train_Y = split_windows(scaled_train_data, size=window_size) test_X, test_Y = split_windows(scaled_test_data, size=window_size) print('train shape', train_X.shape, train_Y.shape) print('test shape', test_X.shape, test_Y.shape)训练集和测试集的shape如下,其中493表示训练的窗口数据个数,7表示窗口大小,5表示数据特征个数,这样每个样本数据就是一个7*5的2D图像的形式。 train shape (493, 7, 5) (493,) test shape (103, 7, 5) (103,)3.模型搭建 下面通过keras对模型进行搭建,首先是输入层和Reshape层,用于将输入数据转换为指定的输入形式,其中每个输入数据是一个7*5*1的2D图像的形式,7表示宽,5表示高,1表示通道个数。然后通过一个2D Conv层进行卷积操作,滤波器个数为64,padding设置为same用于获取相同大小的feature map,激活函数为relu。接着通过一个Maxpooling进行下采样,然后接一个Dropout用于防止过拟合。之后连接两层LSTM层,从时间步的维度进行时序建模。最后通过全连接层进行输出下一时刻的预测值。模型的loss function选择为均方误差,优化方法采用adam优化器。 window_size = 7 fea_num = 5 model = keras.models.Sequential([ keras.layers.Input((window_size, fea_num)), keras.layers.Reshape((window_size, fea_num, 1)), keras.layers.Conv2D(filters=64, kernel_size=3, strides=1, padding="same", activation="relu"), keras.layers.MaxPooling2D(pool_size=2, strides=1, padding="same"), keras.layers.Dropout(0.3), keras.layers.Reshape((window_size, -1)), keras.layers.LSTM(128, return_sequences=True), keras.layers.LSTM(64, return_sequences=False), keras.layers.Dense(32, activation="relu"), keras.layers.Dense(1) ]) model.compile(loss='mse', optimizer='adam', metrics=['mse']) model.summary()模型的基本结构以及参数个数如下所示: Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= reshape (Reshape) (None, 7, 5, 1) 0 _________________________________________________________________ conv2d (Conv2D) (None, 7, 5, 64) 640 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 7, 5, 64) 0 _________________________________________________________________ dropout (Dropout) (None, 7, 5, 64) 0 _________________________________________________________________ reshape_1 (Reshape) (None, 7, 320) 0 _________________________________________________________________ lstm (LSTM) (None, 7, 128) 229888 _________________________________________________________________ lstm_1 (LSTM) (None, 64) 49408 _________________________________________________________________ dense (Dense) (None, 32) 2080 _________________________________________________________________ dense_1 (Dense) (None, 1) 33 ================================================================= Total params: 282,049 Trainable params: 282,049 Non-trainable params: 0之后对模型进行训练,epochs设置为50。 model.fit(x=train_X, y=train_Y, epochs=50) Epoch 1/50 16/16 [==============================] - 0s 9ms/step - loss: 0.0313 - mse: 0.0313 Epoch 2/50 ... Epoch 49/50 16/16 [==============================] - 0s 8ms/step - loss: 0.0012 - mse: 0.0012 Epoch 50/50 16/16 [==============================] - 0s 8ms/step - loss: 0.0012 - mse: 0.00124.模型评估 下面对训练好的模型进行评估,首先需要对预测结果进行反归一化,然后进行可视化以及计算RMSE: prediction = model.predict(test_X) scaled_prediction = prediction * (scaler.data_max_[2] - scaler.data_min_[2]) + scaler.data_min_[2] scaled_true = test_Y * (scaler.data_max_[2] - scaler.data_min_[2]) + scaler.data_min_[2] plt.plot(range(len(scaled_prediction)), scaled_prediction, label='true') plt.plot(range(len(scaled_true)), scaled_true, label='prediction', marker='*') plt.legend() from sklearn.metrics import mean_squared_error print('RMSE', np.sqrt(mean_squared_error(scaled_prediction, scaled_true)))预测效果以及RMSE如下所示:
从实验结果中可以看出我们搭建的简单的CNN-LSTM模型可以实现不错的数据拟合效果,并实现了较低的RMSE。 4 总结 在这篇文章中,我们介绍了如何基于Tensorflow框架搭建一个基于CNN-LSTM的股票预测模型,并通过真实股票数据对模型进行了实验,可以看出CNN-LSTM模型对股价预测具有一定的效果。另外,在通过图像的视角提取股票特征的时候,图像的每行包含了时序关系,而每列则会包含一些空间关系,文中并没有对其从这两个角度进行更深入的挖掘,读者则可以从此角度进一步提升图像对股票特征的表达能力。另外, 本文仅仅只是通过价格以及交易量等基本面数据作为了数据输入,为了更好地结合市场特征,我们也可以将一些技术指标作为输入来使得模型学习更多的市场信息。 reference: Li C , Zhang X , Qaosar M , et al. Multi-factor Based Stock Price Prediction Using Hybrid Neural Networks with Attention Mechanism[C]// 2019 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congres IEEE, 2019. 完整代码请在《人工智能量化实验室》公众号后台回复“100”关键字。本文内容仅仅是技术探讨和学习,并不构成任何投资建议。 
了解更多人工智能与 量化金融知识 |

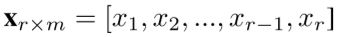

【本文地址】