torch.distributed.init |
您所在的位置:网站首页 › world含义 › torch.distributed.init |
torch.distributed.init
|
文章目录
前言一、torch.distributed.init_process_group函数定义二、RANK、WORLD_SIZE 和 LOCAL_RANK1、RANK说明2、WORLD_SIZE说明3、LOCAL_RANK说明
三、环境变量与应用1、使用系统环境配置2、init_process_group直接配置3、多个进程应用(world_size=2)
四、模型应用
前言
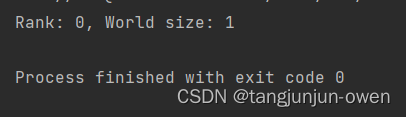
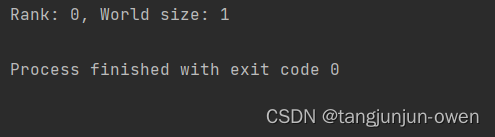
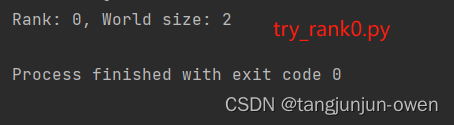
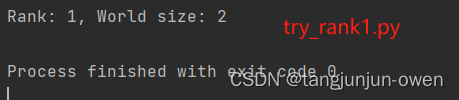
最近在研究deepspeed的方法,得知deepspeed方法也是对pytorch分布式调用的进一步封装,我将回顾以往知识(重温(已忘记了)),之前多数直接使用torch函数调用,或已不太记得之前研究过的东西了,今日特意回顾torch的init_process_group函数,但介于有rank world_size等配置,我特意写此文章详细整理该知识。 一、torch.distributed.init_process_group函数定义 torch.distributed.init_process_group( backend, init_method=None, timeout=datetime.timedelta(seconds=1800), world_size=-1, rank=-1, store=None, group_name='default', **kwargs )参数说明: backend:指定分布式后端的名称,例如 ‘nccl’、‘gloo’ 或 ‘mpi’。 init_method:初始化方法的 URL 或文件路径。默认为 None,表示使用默认的初始化方法。 timeout:初始化过程的超时时间,默认为 1800 秒。 world_size:参与分布式训练的总进程数。默认为 -1,表示从环境变量中自动获取。 rank:当前进程的排名。默认为 -1,表示从环境变量中自动获取。 store:用于存储进程组信息的存储对象。默认为 None,表示使用默认存储。 group_name:进程组的名称,默认为 ‘default’。 **kwargs:其他可选参数,根据不同的分布式后端而定。 二、RANK、WORLD_SIZE 和 LOCAL_RANK在分布式训练中,RANK、WORLD_SIZE 和 LOCAL_RANK 都是用于标识进程的环境变量,但它们的含义略有不同: 1、RANK说明RANK 表示当前进程在所有进程中的排名。例如,如果有 4 个进程,它们的 RANK 分别为 0、1、2 和 3。在分布式训练中,我们通常需要使用 RANK 来决定当前进程的角色和任务,例如是否是主进程、是否需要保存模型等。 2、WORLD_SIZE说明WORLD_SIZE 表示所有进程的总数。例如,如果有 4 个进程,它们的 WORLD_SIZE 均为 4。在分布式训练中,我们通常需要使用 WORLD_SIZE 来决定数据并行的方式和分配任务的方式等。 3、LOCAL_RANK说明LOCAL_RANK 表示当前进程在同一台计算机上的排名。例如,如果有 4 个进程,其中 2 个运行在计算机 A 上,另外 2 个运行在计算机 B 上,那么在计算机 A 上运行的两个进程的 LOCAL_RANK 分别为 0 和 1,在计算机 B 上运行的两个进程的 LOCAL_RANK 分别为 0 和 1。在分布式训练中,我们通常需要使用 LOCAL_RANK 来决定如何分配 GPU 设备和数据等。 在分布式训练中,这三个环境变量通常需要在所有进程中保持一致,并且需要在初始化分布式训练环境时设置。例如,在 PyTorch 中,可以使用 torch.distributed.init_process_group() 函数来初始化分布式训练环境,并自动设置这三个环境变量。 三、环境变量与应用我将在这里介绍只有2个进程的world_size与rank的使用方法,在启动2个进程前,我先介绍1个进程的环境配置等方法,特别是结合torch的init_process_group搭配使用方式。 但使用分布式环境前,都需要在os.environ系统环境变量声明ip与port端口,如下: # 设置主进程的 IP 地址和端口号 os.environ['MASTER_ADDR'] = '127.0.0.1' os.environ['MASTER_PORT'] = '29501'当然,你也可以执行代码借助命令给定,我这里是在py文件中直接配置。 1、使用系统环境配置直接使用os.environ系统环境变量指定rank与world_size,init_process_group能自动获取系统配置,我在这里rank=0,world_size=1分别表示进程rank0与共1个进程,如下: os.environ['RANK'] = '0' os.environ['WORLD_SIZE'] = '1' # 初始化分布式训练环境 dist.init_process_group(backend='nccl')完整的示列代码如下: import torch.distributed as dist import os # 设置主进程的 IP 地址和端口号 os.environ['MASTER_ADDR'] = '127.0.0.1' os.environ['MASTER_PORT'] = '29501' os.environ['RANK'] = '0' os.environ['WORLD_SIZE'] = '1' dist.init_process_group(backend='nccl') # 初始化分布式训练环境 # 获取当前进程的排名和总进程数 rank = dist.get_rank() world_size = dist.get_world_size() print(f"Rank: {rank}, World size: {world_size}") # 在分布式训练中使用排名和总进程数 # 执行分布式训练代码 # ... dist.destroy_process_group() # 释放资源结果如下: 你也可以不使用os.environ系统环境变量指定rank与world_size,直接使用init_process_group指定,效果和上面一致,如下: dist.init_process_group(backend='nccl',rank=0,world_size=1) # 初始化分布式训练环境完整的示列代码如下: import torch.distributed as dist import os # 设置主进程的 IP 地址和端口号 os.environ['MASTER_ADDR'] = '127.0.0.1' os.environ['MASTER_PORT'] = '29501' dist.init_process_group(backend='nccl',rank=0,world_size=1) # 初始化分布式训练环境 # 获取当前进程的排名和总进程数 rank = dist.get_rank() world_size = dist.get_world_size() print(f"Rank: {rank}, World size: {world_size}") # 在分布式训练中使用排名和总进程数 # 执行分布式训练代码 # ... dist.destroy_process_group() # 释放资源结果如下: 我们继续设置2个进程world_size=2,则使用2个rank分别运行各自子进程,每个子进程我们会有一个py文件代码,主要更改地方为rank与world_size值,其中2个py文件分别为 try_rank0.py与try_rank1.py,其代码如下: try_rank0.py: import torch.distributed as dist import os # 设置主进程的 IP 地址和端口号 os.environ['MASTER_ADDR'] = '127.0.0.1' os.environ['MASTER_PORT'] = '29501' dist.init_process_group(backend='nccl', rank=0, world_size=2) # 初始化分布式训练环境 # 获取当前进程的排名和总进程数 rank = dist.get_rank() world_size = dist.get_world_size() print(f"Rank: {rank}, World size: {world_size}") # 在分布式训练中使用排名和总进程数 # 执行分布式训练代码 # ... dist.destroy_process_group() # 释放资源try_rank1.py: import torch.distributed as dist import os # 设置主进程的 IP 地址和端口号 os.environ['MASTER_ADDR'] = '127.0.0.1' os.environ['MASTER_PORT'] = '29501' # 设置当前进程的局部排名(local_rank) os.environ['RANK'] = '1' os.environ['WORLD_SIZE'] = '2' dist.init_process_group(backend='nccl') # 初始化分布式训练环境 # 获取当前进程的排名和总进程数 rank = dist.get_rank() world_size = dist.get_world_size() # 在分布式训练中使用排名和总进程数 print(f"Rank: {rank}, World size: {world_size}") # 执行分布式训练代码 # ... dist.destroy_process_group() # 释放资源需先执行运行主节点try_rank0.py文件,在执行try_rank1.py文件,其结果分别如下:
这里,我们首先调用 dist.init_process_group() 来初始化分布式训练环境。然后定义了一个简单的线性模型,并使用随机生成的数据进行训练。最后,我们调用 dist.destroy_process_group() 来释放资源。 请注意,这只是一个简单的示例,实际使用中可能需要更复杂的模型和数据。同时,请确保在每个进程中都正确地调用了 torch.distributed.init_process_group(),并根据实际情况设置其他参数。 import torch import torch.distributed as dist import torch.nn as nn import torch.optim as optim import os # 设置环境变量 MASTER_ADDR 和 MASTER_PORT os.environ['MASTER_ADDR'] = '127.0.0.1' os.environ['MASTER_PORT'] = '29505' # 设置环境变量 RANK os.environ['RANK'] = '0' os.environ['WORLD_SIZE'] = '2' # 初始化分布式训练环境,尽管系统环境给了world_size为2,但调用给的是1,不冲突 dist.init_process_group(backend='nccl', rank=0,world_size=1) # 定义线性模型 class LinearModel(nn.Module): def __init__(self): super(LinearModel, self).__init__() self.linear = nn.Linear(1, 1) def forward(self, x): return self.linear(x) # 创建模型实例 model = LinearModel() # 定义损失函数和优化器 criterion = nn.MSELoss() optimizer = optim.SGD(model.parameters(), lr=0.01) model = model.to(torch.device('cuda')) # 生成随机数据 x = torch.randn(100, 1) y = 3 * x + 2 + torch.randn(100, 1) * 0.1 # 将数据分发到各个进程 x = x.to(torch.device('cuda')) y = y.to(torch.device('cuda')) # 在每个进程上进行训练 for epoch in range(10): optimizer.zero_grad() outputs = model(x) loss = criterion(outputs, y) loss.backward() optimizer.step() print(loss) # 释放资源 dist.destroy_process_group()运行结果如下: 可参考知识:点击这里 可参考知识:点击这里 |
【本文地址】
今日新闻 |
推荐新闻 |