POI与Spire.Doc操作Word中文本与样式替换和转HTML(Java) |
您所在的位置:网站首页 › word怎么替换段落 › POI与Spire.Doc操作Word中文本与样式替换和转HTML(Java) |
POI与Spire.Doc操作Word中文本与样式替换和转HTML(Java)
|
POI与Spire.Doc操作Word中文本与样式替换(Java)
需求说明POI操作Word更新文本与样式POI操作Word说明图POI匹配文档中特定文本问题
Spire.Doc匹配文档中特定文本问题Word转HTML文件预览Word操作POI操作Word整体代码Spire.Doc操作Word整体代码方法1:使用Pattern正则匹配方法2:使用findAllString()匹配
总结求助
需求说明
最近有个需求 ,将用户上传Word进行分析其中内容,将已匹配的字词进行高亮颜色替换和参考说明,将其分析后的文档提供预览和下载分析后文档 需求要点: 1. 上传的Word文档读取内容; 2. 分析文本中的内容,将已匹配的字词进行替换,高亮背景并提醒说明; 3. 保存分析后的文档; 4. 页面预览分析更新后文档; 5. 提供下载更新后的Word POI操作Word更新文本与样式 POI操作Word说明图在使用POI操作的时候应该会发现,它的类有很多,有时候都分不清吗,下图是为了帮助理解的一张简单的说明图 结论:POI提取会因为文本的字体,大小,样式将需要的文本截取成两个Run,导致无法精准匹配到需要的字词 文档内容: 结论:spire.doc可以精准匹配和替换需要的字词,但对需要的字词加样式时会导致无法精准,有时会加到整个段落上面 文档内容: 由结果得知,spire.doc可以匹配到需要的文本,但对齐需要的文本加样式时,会有时加到整个段落上面。 匹配代码: 此处不知道怎么预览Word,还要用组件,就偷了个懒,将Word转为HTML 读取已保存的HTML文件,获取HTML文件代码给富文本展示读取以保存的HTML文件,使用Jsoup获取需要的body内容后传给页面展示 /** * Word转HTML * * @param file * @return 结果 */ public boolean insertSenaFileContentCheck(MultipartFile file, String fileName, String suffix, HttpServletRequest request) { try { String wordPath = request.getServletContext().getRealPath("/uploads/scan_word") + File.separator + UUID.randomUUID() + fileName + suffix; // html与css文件共用uuid UUID uuid = UUID.randomUUID(); String htmlPath = request.getServletContext().getRealPath("/uploads/html_word") + File.separator + uuid + fileName + ".html"; String cssPath = request.getServletContext().getRealPath("/uploads/html_word") + File.separator + uuid + fileName + "_styles.css"; // 保存上传文件之/uploads/scan_word下 file.transferTo(new File(wordPath)); Document document = new Document(); // 加载检测word文件 document.loadFromFile(wordPath); // 保存HTML文件之服务器 document.saveToFile(htmlPath, FileFormat.Html); // 持久化数据 } catch (IOException e) { System.out.println("(异常) 文件内容 Msg: " + e.getMessage()); } return false; } POI操作Word整体代码 package com.link.util.File; import com.link.util.text.StringUtils; import org.apache.poi.xwpf.usermodel.*; import java.io.*; import java.util.*; import java.util.regex.Matcher; import java.util.regex.Pattern; /** * @Description: poi工具类 * @Author: sena104 * @create: 2023-02-23 10:36:13 * */ public class POIUtil { public static void main(String[] args) throws Exception { Map params = new HashMap(); params.put("七个有数", "七个有数(参考:七个有之)"); String pathname = "C:\\Users\\xxx\\Desktop\\test\\"; String fileName = "xxxx.docx"; String outPath = "xxxx.docx"; // 模板word文件真实路径 String scanFilePath = pathname + fileName; // 使用文档输出路径 String outFilePath = pathname + outPath; POIUtil.templateWrite(scanFilePath, outFilePath, params); } /** * 用一个docx文档作为模板,然后替换其中的内容,再写入目标文档中。 * * @throws Exception */ public static void templateWrite(String filePath, String outFilePath, Map params) throws Exception { InputStream is = new FileInputStream(filePath); XWPFDocument doc = new XWPFDocument(is); //替换段落里面的变量 replaceInPara(doc, params); //替换表格里面的变量 replaceInTable(doc, params); OutputStream os = new FileOutputStream(outFilePath); doc.write(os); close(os); close(is); } /** * 替换段落里面的变量 * * @param doc 要替换的文档 * @param params 参数 */ private static void replaceInPara(XWPFDocument doc, Map params) { Iterator iterator = doc.getParagraphsIterator(); XWPFParagraph para; while (iterator.hasNext()) { para = iterator.next(); replaceInPara(para, params); } } /** * 替换段落里面的变量 * * @param para 要替换的段落 * @param params 参数 */ private static void replaceInPara(XWPFParagraph para, Map params) { List runs; Matcher matcher; String runText = ""; int fontSize = 0; UnderlinePatterns underlinePatterns = null; if (StringUtils.isNotEmpty(para.getText())) { runs = para.getRuns(); if (runs.size() > 0) { for (XWPFRun run : runs) { System.out.println("run = " + run.text()); } } } } // private static void replaceInPara(XWPFParagraph para, Map params) { // List runs; // Matcher matcher; // String runText = ""; // int fontSize = 0; // UnderlinePatterns underlinePatterns = null; // if (matcher(para.getParagraphText()).find()) { // runs = para.getRuns(); // if (runs.size() > 0) { // int j = runs.size(); // for (int i = 0; i < j; i++) { // XWPFRun run = runs.get(0); // if (fontSize == 0) { // fontSize = run.getFontSize(); // } // if(underlinePatterns==null){ // underlinePatterns=run.getUnderline(); // } // String i1 = run.toString(); // runText += i1; // para.removeRun(0); // } // } // matcher = matcher(runText); // if (matcher.find()) { // while ((matcher = matcher(runText)).find()) { // runText = matcher.replaceFirst(String.valueOf(params.get(matcher.group(1)))); // } // //直接调用XWPFRun的setText()方法设置文本时,在底层会重新创建一个XWPFRun,把文本附加在当前文本后面, // //所以我们不能直接设值,需要先删除当前run,然后再自己手动插入一个新的run。 // //para.insertNewRun(0).setText(runText);//新增的没有样式 // XWPFRun run = para.createRun(); // run.setText(runText,0); // run.setFontSize(fontSize); // run.setUnderline(underlinePatterns); // run.setFontFamily("仿宋");//字体 // run.setFontSize(16);//字体大小 // //run.setBold(true); //加粗 // //run.setColor("FF0000"); // //默认:宋体(wps)/等线(office2016) 5号 两端对齐 单倍间距 // //run.setBold(false);//加粗 // //run.setCapitalized(false);//我也不知道这个属性做啥的 // //run.setCharacterSpacing(5);//这个属性报错 // //run.setColor("BED4F1");//设置颜色--十六进制 // //run.setDoubleStrikethrough(false);//双删除线 // //run.setEmbossed(false);//浮雕字体----效果和印记(悬浮阴影)类似 // //run.setFontFamily("宋体");//字体 // //run.setFontFamily("华文新魏", FontCharRange.cs);//字体,范围----效果不详 // //run.setFontSize(14);//字体大小 // //run.setImprinted(false);//印迹(悬浮阴影)---效果和浮雕类似 // //run.setItalic(false);//斜体(字体倾斜) // //run.setKerning(1);//字距调整----这个好像没有效果 // //run.setShadow(true);//阴影---稍微有点效果(阴影不明显) // //run.setSmallCaps(true);//小型股------效果不清楚 // //run.setStrike(true);//单删除线(废弃) // //run.setStrikeThrough(false);//单删除线(新的替换Strike) // //run.setSubscript(VerticalAlign.SUBSCRIPT);//下标(吧当前这个run变成下标)---枚举 // //run.setTextPosition(20);//设置两行之间的行间距 // //run.setUnderline(UnderlinePatterns.DASH_LONG);//各种类型的下划线(枚举) // //run0.addBreak();//类似换行的操作(html的 br标签) // //run0.addTab();//tab键 // //run0.addCarriageReturn();//回车键 // //注意:addTab()和addCarriageReturn() 对setText()的使用先后顺序有关:比如先执行addTab,再写Text这是对当前这个Text的Table,反之是对下一个run的Text的Tab效果 // // // } // } // // } /** * 替换表格里面的变量 * * @param doc 要替换的文档 * @param params 参数 */ private static void replaceInTable(XWPFDocument doc, Map params) { Iterator iterator = doc.getTablesIterator(); XWPFTable table; List rows; List cells; List paras; while (iterator.hasNext()) { table = iterator.next(); rows = table.getRows(); for (XWPFTableRow row : rows) { cells = row.getTableCells(); for (XWPFTableCell cell : cells) { paras = cell.getParagraphs(); for (XWPFParagraph para : paras) { replaceInPara(para, params); } } } } } /** * 正则匹配字符串 * * @param str * @return */ private static Matcher matcher(String regex, String str) { Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE); Matcher matcher = pattern.matcher(str); return matcher; } /** * 正则匹配字符串 * * @param str * @return */ private static Matcher matcher(String str) { Pattern pattern = Pattern.compile("\\$\\{(.+?)\\}", Pattern.CASE_INSENSITIVE); Matcher matcher = pattern.matcher(str); return matcher; } /** * 关闭输入流 * * @param is */ private static void close(InputStream is) { if (is != null) { try { is.close(); } catch (IOException e) { e.printStackTrace(); } } } /** * 关闭输出流 * * @param os */ private static void close(OutputStream os) { if (os != null) { try { os.close(); } catch (IOException e) { e.printStackTrace(); } } } } Spire.Doc操作Word整体代码 方法1:使用Pattern正则匹配 @Test public void test01() throws IOException { Map keyMap = new HashMap(); keyMap.put("七个有数", "七个有之"); String pathname = "C:\\Users\\xxx\\Desktop\\test\\"; String fileName = "xxx.docx"; String outPath = "xxx.docx"; com.spire.doc.Document document = new com.spire.doc.Document(); //加载Word示例文档 document.loadFromFile(pathname + fileName); //获取文档中的指定段落 for (Map.Entry entry : keyMap.entrySet()) { // 通过regex匹配需要的文本 Pattern pattern = Pattern.compile(entry.getKey()); // 拿到所有匹配的关键字对象数组 TextSelection[] allPattern = document.findAllPattern(pattern); if (allPattern != null && allPattern.length > 0) { Arrays.stream(allPattern).forEach(selection -> { // 打印已匹配的文本是否正确 System.out.println("selection = " + selection.getSelectedText()); // 构建替换文本对象 StringBuilder refKey = new StringBuilder(); refKey.append(entry.getKey()).append("(参考:").append(entry.getValue()).append(")"); // 替换文本 selection.getAsOneRange().setText(refKey.toString()); // 查找已替换后位置文本对象 TextSelection textSelection = selection.getAsOneRange().getOwnerParagraph().find(refKey.toString(), true, false); TextRange range = textSelection.getAsOneRange(); // 打印是否正确获取替换后文本的对象 System.out.println("range = " + range.getText()); // 对替换后文本进行背景色改变 range.getCharacterFormat().setTextBackgroundColor(Color.YELLOW); }); } } // 写出到指定目录下 document.saveToFile(pathname + outPath, FileFormat.Docx); } 方法2:使用findAllString()匹配 public void test02() throws IOException { Map keyMap = new HashMap(); keyMap.put("立党为公、至政为民", "立党为公、执政为民"); keyMap.put("七个有数", "七个有之"); String pathname = "C:\\Users\\xxx\\Desktop\\test\\"; String fileName = "xxx.docx"; String outPath = "xxx.docx"; //加载Word示例文档 com.spire.doc.Document document = new com.spire.doc.Document(); document.loadFromFile(pathname + fileName); //获取文档中的指定段落 for (Map.Entry entry : keyMap.entrySet()) { // 拿到所有匹配的关键字对象数组 TextSelection[] selectionArr = document.findAllString(entry.getKey(), false, false); if (selectionArr != null && selectionArr.length > 0) { Arrays.stream(selectionArr).forEach(selection -> { System.out.println("selection = " + selection.getSelectedText()); // 替换操作 selection.getAsOneRange().getCharacterFormat().setTextBackgroundColor(Color.YELLOW); }); } } document.saveToFile(pathname + outPath, FileFormat.Docx); // document.dispose(); }上传和下载也没什么好说的,有许多前段控件与后端工具类 这是我看到的一个下载工具类 /** * 文件下载公共方法 * @param response * @param filepath */ public static void downloadFile(HttpServletResponse response, String filepath) { // 实现文件下载 FileInputStream fis = null; BufferedInputStream bis = null; try { File file = new File(filepath); // 配置文件下载 response.setCharacterEncoding("UTF-8"); response.setContentType("application/x-excel"); // 下载文件能正常显示中文 response.setHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(file.getName(), "UTF-8")); byte[] buffer = new byte[1024]; fis = new FileInputStream(file); bis = new BufferedInputStream(fis); response.setHeader("Content-Length", fis.available() + ""); // 内容长度 OutputStream os = response.getOutputStream(); int i = bis.read(buffer); while (i != -1) { os.write(buffer, 0, i); i = bis.read(buffer); } os.close(); } catch (Exception e) { } finally { if (bis != null) { try { bis.close(); } catch (IOException e) { e.printStackTrace(); } } if (fis != null) { try { fis.close(); } catch (IOException e) { e.printStackTrace(); } } } } 总结 使用POI操作Word因为字体,大小等原因,可能导致无法匹配到需要的文本,若直接使用getText(),获取所有文本匹配,就算匹配到了,也不知道怎么去定位需要替换的位置。使用spire.doc操作Word,虽然可以精确匹配到需要的文本,也可以替换为想要的文本,但对齐背景色控制上不知道为什么会导致替换了整个段落的背景色如果是只替换文本内容,spire.doc是可以替换的,而且还比较方便,几行代码搞定。 求助文本与样式无法同时替换,现只能替换文本,背景色替换后会替换到整个段落,如上所述。 如果有更好的替换文本与背景也方法和Word预览的操作,还请@我一下。 谢谢!不足之处还请指正! 本文参考代码: 链接: https://blog.csdn.net/qmwxw/article/details/105195570 |
 这图上的简单说明了一下,在操作Word的时候需要用到的东西跟使用顺序
这图上的简单说明了一下,在操作Word的时候需要用到的东西跟使用顺序 获取Run打印数据:
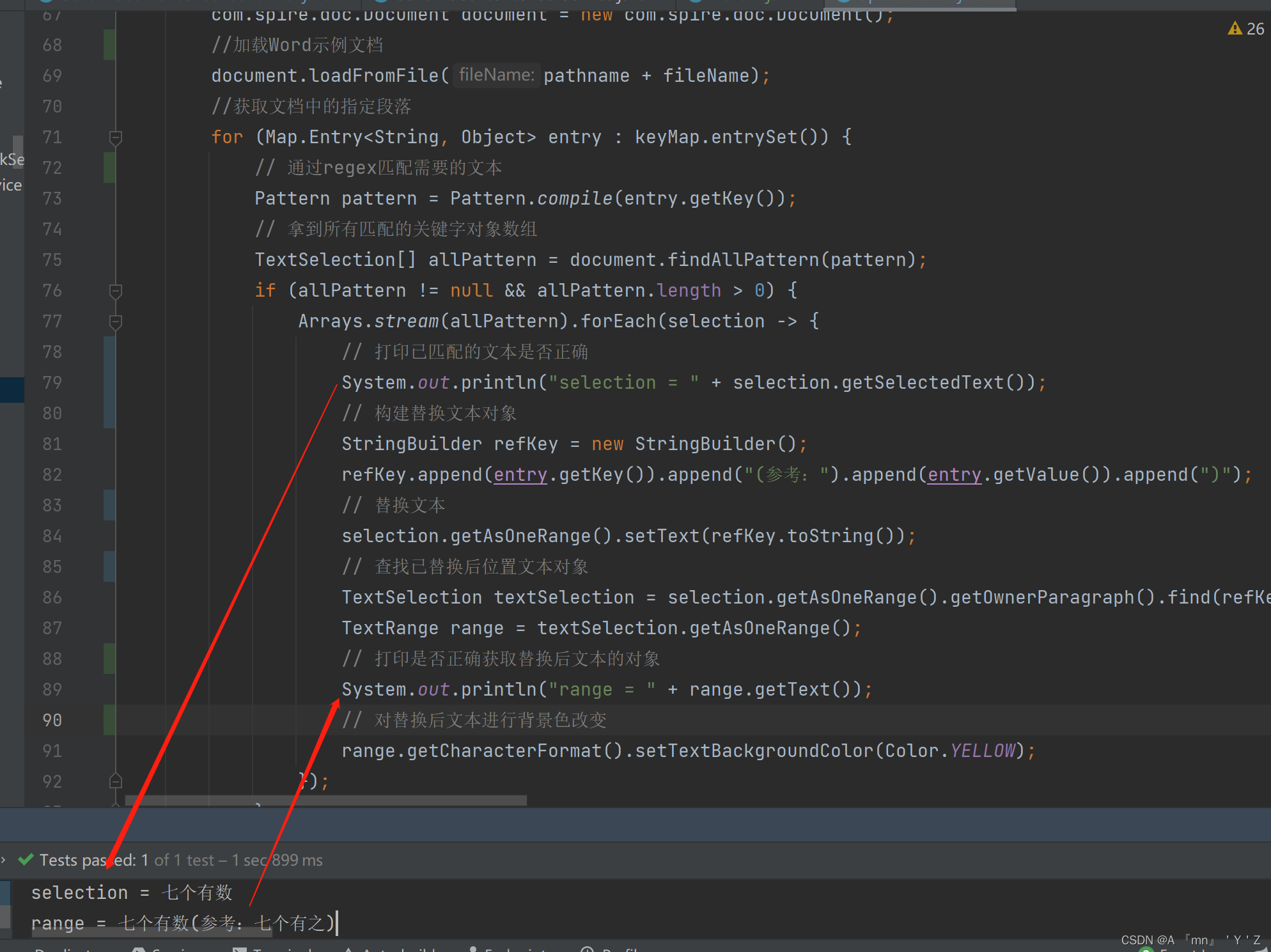
获取Run打印数据:  由上面两张图可以看出, 文档中“系统需实现WEB系统的网页总数七个有数据”这句话, 加载提取后被分割成 “系统需实现WEB系统的网页总数七个有”和“数据”两个Run,这就导致当你想要获取“七个有数据”这个词,并且替换它的样式和文本是没办法匹配的。 而直接获取全文匹配,是可以匹配到,但你没有办法去定位这个词的位置在哪里,与需求不符。 下面是代码段,先加载为document,再去获取paragraph段落,再去读取每个paragraph中的Run
由上面两张图可以看出, 文档中“系统需实现WEB系统的网页总数七个有数据”这句话, 加载提取后被分割成 “系统需实现WEB系统的网页总数七个有”和“数据”两个Run,这就导致当你想要获取“七个有数据”这个词,并且替换它的样式和文本是没办法匹配的。 而直接获取全文匹配,是可以匹配到,但你没有办法去定位这个词的位置在哪里,与需求不符。 下面是代码段,先加载为document,再去获取paragraph段落,再去读取每个paragraph中的Run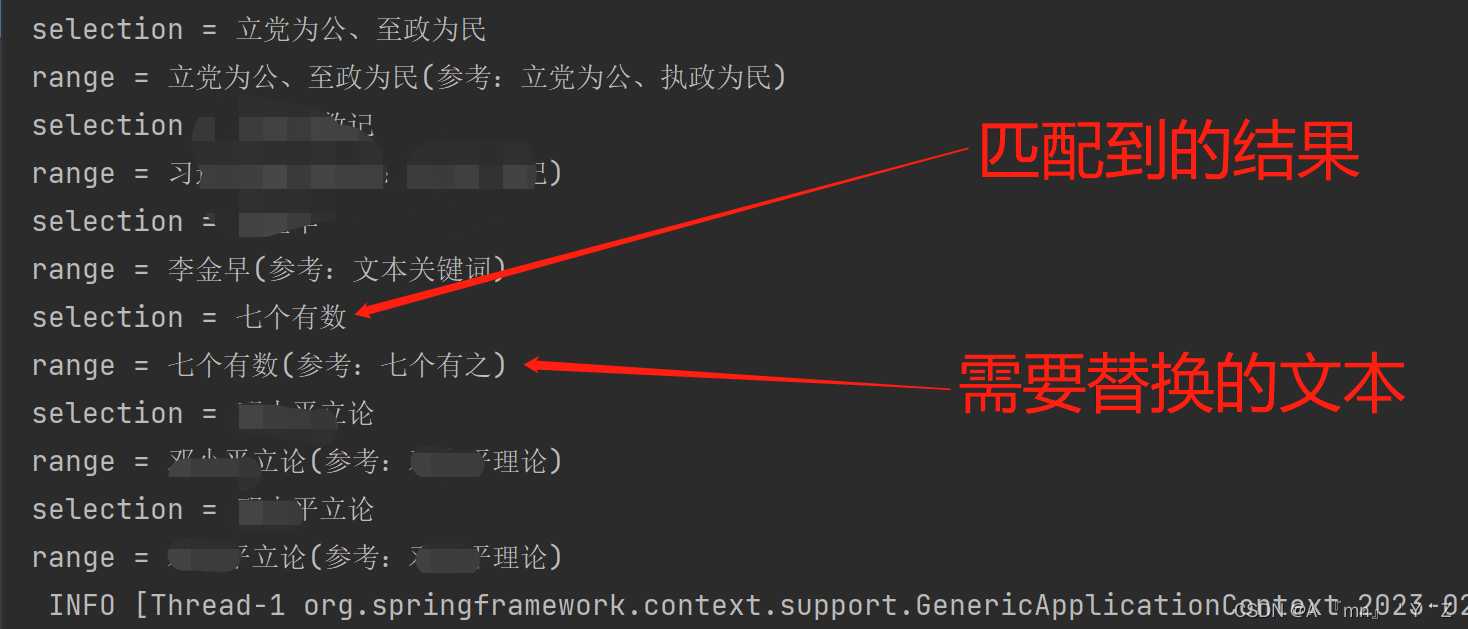 匹配和替换后Word内容:
匹配和替换后Word内容: 
【本文地址】
今日新闻 |
推荐新闻 |