利用 Python 实现txt文本复杂数据处理与导出 Excel 文件 |
您所在的位置:网站首页 › word中可作为文本转换成表格的分隔符 › 利用 Python 实现txt文本复杂数据处理与导出 Excel 文件 |
利用 Python 实现txt文本复杂数据处理与导出 Excel 文件
|
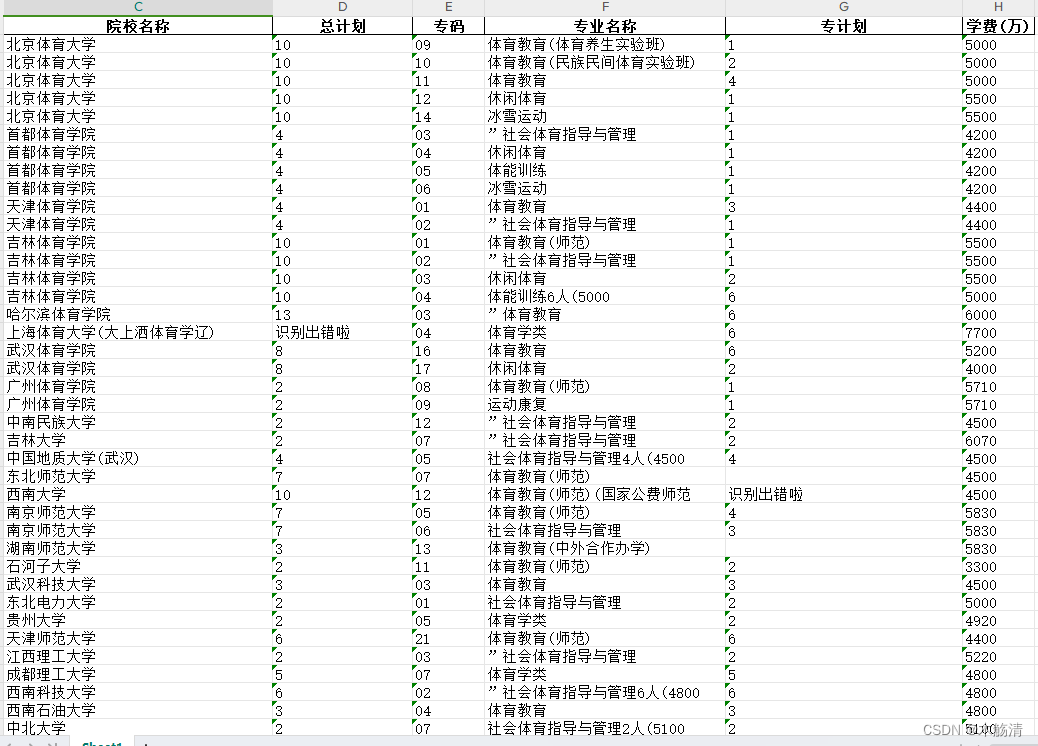
简介: 在实际工作中,我们经常需要处理从各种来源获取的文本数据,并将其转换为结构化数据以便进一步分析和使用。本文将介绍如何使用 Python 对文本数据进行处理,并将处理结果保存到 Excel 文件中。 1. 问题背景: 在数据处理的实践中,从原始文本数据中提取关键信息并将其转换为结构化数据是一个常见的任务。例如,在教育行业,我们可能需要处理包含院校、专业和招生计划等信息的文本数据,以便进行统计分析或制作报表。 2. 代码解析: 我们提供了一个示例代码,其中包含了一个名为 process() 的函数。该函数接受多个列表作为参数,循环遍历这些列表并将数据转换为字典格式,最终使用 Pandas 库将字典转换为 DataFrame。然后,将 DataFrame 中的数据写入到 Excel 文件中。 3. 函数介绍: process() 函数接受多个参数,包括学校编码列表、院校名称列表、总计划列表、专业编码列表、专业名称列表、专业计划列表和学费列表。该函数将这些数据组合成字典,并转换为 DataFrame 格式。 4. 数据处理过程: 在示例代码中,我们使用了一个循环来遍历各个列表,并将对应位置的数据组合成字典。这样可以保证每个学校或专业的数据都被正确地提取和处理。最终,我们将这些字典组成的列表转换为 DataFrame,并将其写入到 Excel 文件中。 5. 实例演示: import re import pandas as pd # 打开文件 with open('./txt/combined.txt', 'r', encoding='utf-8') as file: # 逐行读取文件内容 lines = file.readlines() # 初始化一个空列表,用于存储满足条件的行 selected_lines = [] sch_bsnall = [] sch_nameall = [] sch_numbers = [] sch_bsn = '' sch_name = '' sch_num = '' zy_bsn = [] zy_name = [] zy_num = [] fee_numbers = [] fee_num = '' index_list = [] ind = 1 temp = 0 # 遍历每一行 for line in lines: parts = line.split() # 检查行是否以两个数字开头 if parts[0].isdigit() and len(parts[0]) == 2: # 如果是,则将该行添加到列表中 selected_lines.append(line.strip()) # 使用正则表达式模式匹配类似 "5000 元" 格式的数据 # pattern = r'\b\d+\s*元\b' pattern = r'\d\d\d\d+' # 使用 re.findall() 函数提取匹配到的数据 matches = re.findall(pattern, line.strip()) if len(sch_bsnall) - 1 >= 0: if sch_bsnall[len(sch_bsnall) - 1] == sch_bsn: index_list.append(ind) else: ind = ind + 1 index_list.append(ind) else: index_list.append(ind) if len(matches) >= 1: temp = 1 matchnum1 = matches[0].split() fee_num = matchnum1[0] fee_numbers.append(fee_num) sch_bsnall.append(sch_bsn) sch_nameall.append(sch_name) sch_numbers.append(sch_num) print(len(parts)) zy_bsn.append(parts[0]) if len(parts) >= 3: if parts[2].isdigit(): zy_num.append(parts[2]) zy_name.append(parts[1]) else: # 获取列表中的第二个字符 second_char = parts[1] # 初始化一个空字符串,用于存储提取出的数字 extracted_digits = '' # 遍历第二个字符的每个字符 for char in second_char: # 判断字符是否为数字 if char.isdigit(): # 如果是数字,将其添加到提取的数字字符串中 extracted_digits += char zy_name.append(parts[1].replace(extracted_digits, "")) # 获取列表中的第三个字符 three_char = parts[2] # 遍历第三个字符的每个字符 for char in three_char: # 判断字符是否为数字 if char.isdigit(): # 如果是数字,将其添加到提取的数字字符串中 extracted_digits += char zy_num.append(extracted_digits) else: # 获取列表中的第二个字符 second_char = parts[1] # 初始化一个空字符串,用于存储提取出的数字 extracted_digits = '' # 遍历第二个字符的每个字符 for char in second_char: # 判断字符是否为数字 if char.isdigit(): # 如果是数字,将其添加到提取的数字字符串中 extracted_digits += char if extracted_digits: parts1 = parts[1].split(extracted_digits) zy_name.append(parts1[0]) zy_num.append(extracted_digits) else: zy_name.append(parts[1]) zy_num.append('识别出错啦') elif parts[0].isdigit() and len(parts[0]) >= 4: sch_bsn = parts[0] if len(parts) >= 3: if parts[2].isdigit(): sch_num = parts[2] sch_name = parts[1] else: # 获取列表中的第二个字符 second_char = parts[1] # 初始化一个空字符串,用于存储提取出的数字 extracted_digits = '' # 遍历第二个字符的每个字符 for char in second_char: # 判断字符是否为数字 if char.isdigit(): # 如果是数字,将其添加到提取的数字字符串中 extracted_digits += char sch_name = parts[1].replace(extracted_digits, "") # 获取列表中的第三个字符 three_char = parts[2] # 遍历第三个字符的每个字符 for char in three_char: # 判断字符是否为数字 if char.isdigit(): # 如果是数字,将其添加到提取的数字字符串中 extracted_digits += char sch_num = extracted_digits else: # 获取列表中的第二个字符 second_char = parts[1] # 初始化一个空字符串,用于存储提取出的数字 extracted_digits = '' # 遍历第二个字符的每个字符 for char in second_char: # 判断字符是否为数字 if char.isdigit(): # 如果是数字,将其添加到提取的数字字符串中 extracted_digits += char if extracted_digits: parts1 = parts[1].split(extracted_digits) sch_name = parts1[0] sch_num = extracted_digits else: sch_name = parts[1] sch_num = '识别出错啦' else: # 使用正则表达式模式匹配类似 "5000 元" 格式的数据 pattern = r'\b\d+\s*元\b' # 使用 re.findall() 函数提取匹配到的数据 matches = re.findall(pattern, line.strip()) if len(matches) >= 1: matchnum1 = matches[0].split() fee_num = matchnum1[0] temp = 0 newzy_num = [] for i in range(0, len(zy_num)): parts = zy_num[i].split(fee_numbers[i]) newzy_num.append(parts[0]) def process(sch_bsnall,sch_nameall,sch_numbers,zy_bsn,zy_name,newzy_num,fee_numbers): lis = [] for s in range(0, len(sch_bsnall)): dic = {} dic['校码'] = sch_bsnall[s] dic['院校名称'] = sch_nameall[s] dic['总计划'] = sch_numbers[s] dic['专码'] = zy_bsn[s] dic['专业名称'] = zy_name[s] dic['专计划'] = newzy_num[s] dic['学费(万)'] = fee_numbers[s] lis.append(dic) df = pd.DataFrame(lis) return df # 写入到excel文件 res = process(sch_bsnall,sch_nameall,sch_numbers,zy_bsn,zy_name,newzy_num,fee_numbers) res.index = index_list res.to_excel(r'C:\Users\Administrator\Desktop\1\image\2.xlsx', index=True)6. 实现效果: 生成的excel文件
7. 总结: 本文介绍了利用 Python 对文本数据进行处理,并将处理结果保存到 Excel 文件的方法。通过示例代码和详细解释,读者可以了解到如何使用 Python 和 Pandas 库来处理和导出数据,从而更加高效地应对实际工作中的数据处理需求。 |
【本文地址】
今日新闻 |
推荐新闻 |