Kmeans |
您所在的位置:网站首页 › wine数据集聚类结果分析 › Kmeans |
Kmeans
|
参考:https://blog.csdn.net/weixin_41666747/article/details/103359961 案例说明:数据集包括20个样本数据,5个数据特征(品牌,热量,含钠量,酒精量,成本),在聚类时只使用后4个数值特征。 数据(beer_data.txt): name calories sodium alcohol cost Budweiser 144 15 4.7 0.43 Schlitz 151 19 4.9 0.43 Lowenbrau 157 15 0.9 0.48 Kronenbourg 170 7 5.2 0.73 Heineken 152 11 5.0 0.77 Old_Milwaukee 145 23 4.6 0.28 Augsberger 175 24 5.5 0.40 Srohs_Bohemian_Style 149 27 4.7 0.42 Miller_Lite 99 10 4.3 0.43 Budweiser_Light 113 8 3.7 0.40 Coors 140 18 4.6 0.44 Coors_Light 102 15 4.1 0.46 Michelob_Light 135 11 4.2 0.50 Becks 150 19 4.7 0.76 Kirin 149 6 5.0 0.79 Pabst_Extra_Light 68 15 2.3 0.38 Hamms 139 19 4.4 0.43 Heilemans_Old_Style 144 24 4.9 0.43 Olympia_Goled_Light 72 6 2.9 0.46 Schlitz_Light 97 7 4.2 0.47导入包和数据 import matplotlib.pyplot as plt from sklearn.cluster import KMeans import pandas as pd beer = pd.read_csv("./beer_data.txt", sep=" ") beer.head()
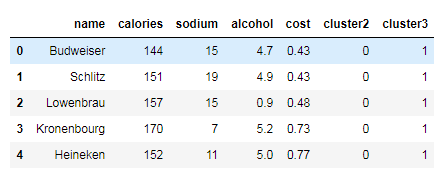
选取特征训练: X = beer.iloc[:,1:] # ["calories","sodium","alcohol","cost"] # K-Means聚类 km2 = KMeans(n_clusters=2).fit(X) # 取值k=2 km3 = KMeans(n_clusters=3).fit(X) # 取值k=3 print("当k=2时聚类结果:", km2.labels_) print("当k=3时聚类结果:", km3.labels_) #当k=2时聚类结果: [0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 1 0 0 1 1] #当k=3时聚类结果: [0 0 0 0 0 0 0 0 2 2 0 2 0 0 0 1 0 0 1 2] beer["cluster2"] = km2.labels_ beer["cluster3"] = km3.labels_ beer.sort_values("cluster3") #按某一列排序,默认升序 axis =0
结果分析: 结果展示 centers = beer.groupby("cluster3").mean().reset_index() print(centers)
|





【本文地址】