Python高速下载分析巨潮资讯网年度报告PDF版(一) |
您所在的位置:网站首页 › wind如何批量下载上市公司年报 › Python高速下载分析巨潮资讯网年度报告PDF版(一) |
Python高速下载分析巨潮资讯网年度报告PDF版(一)
|
前言
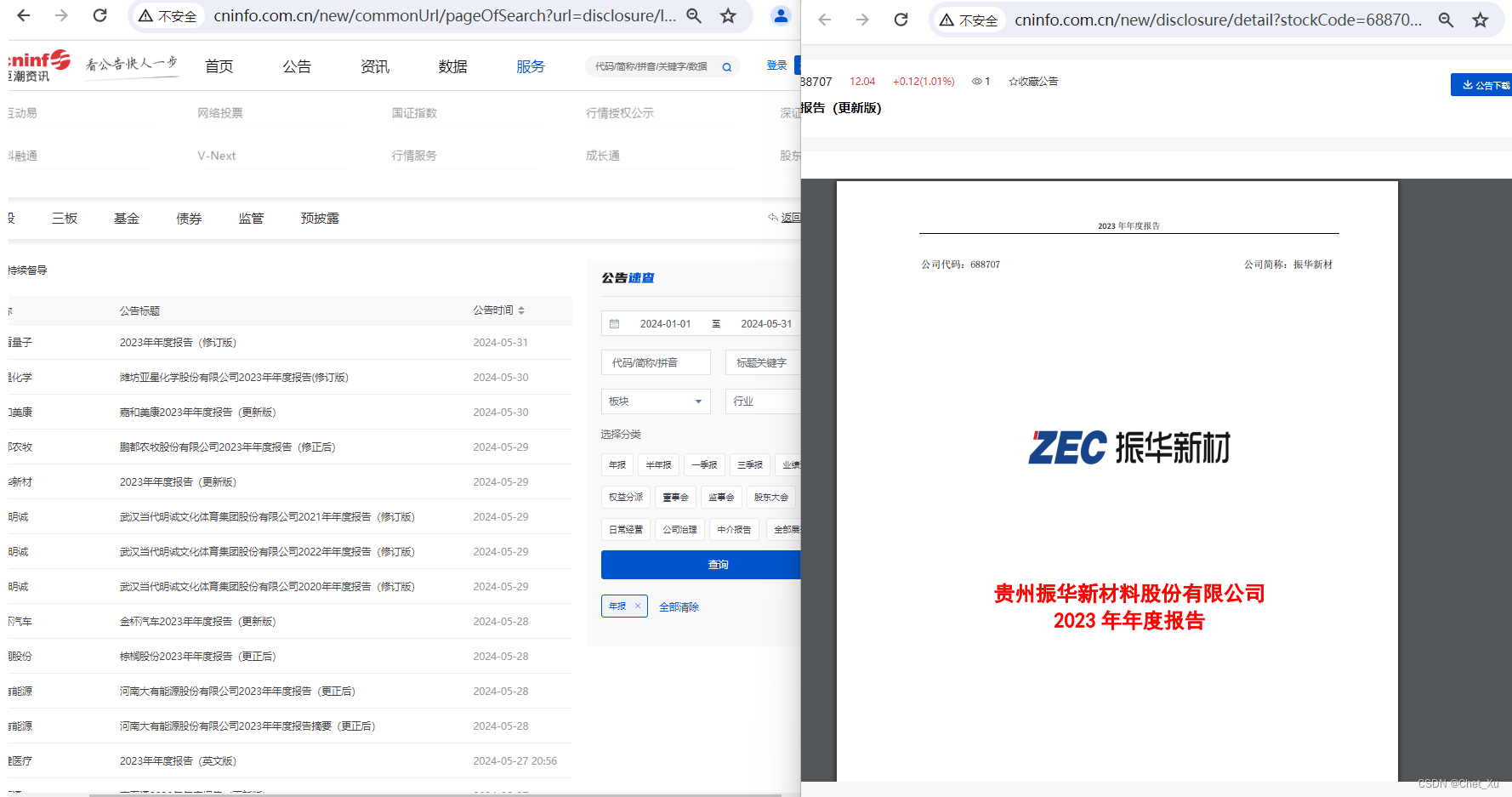
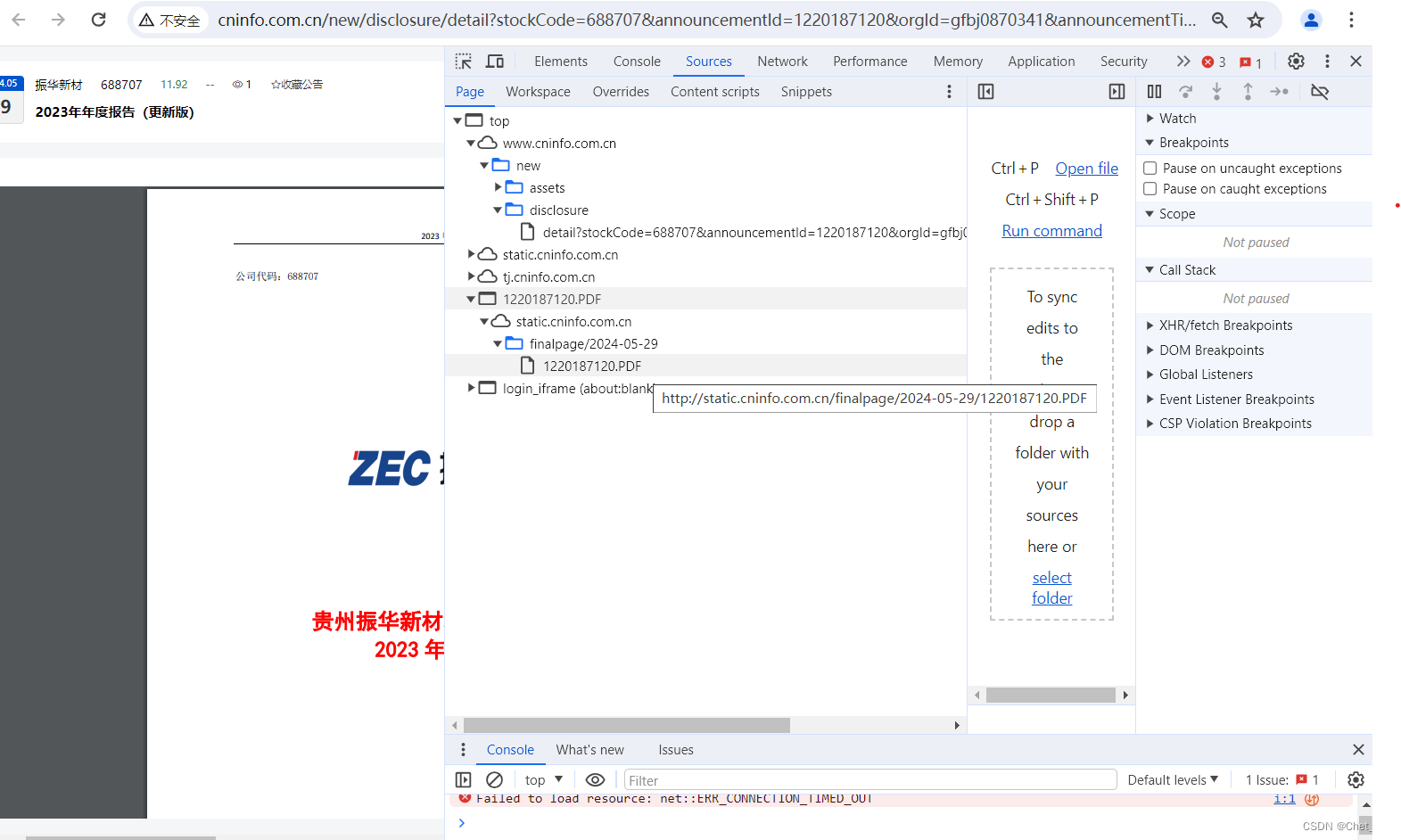
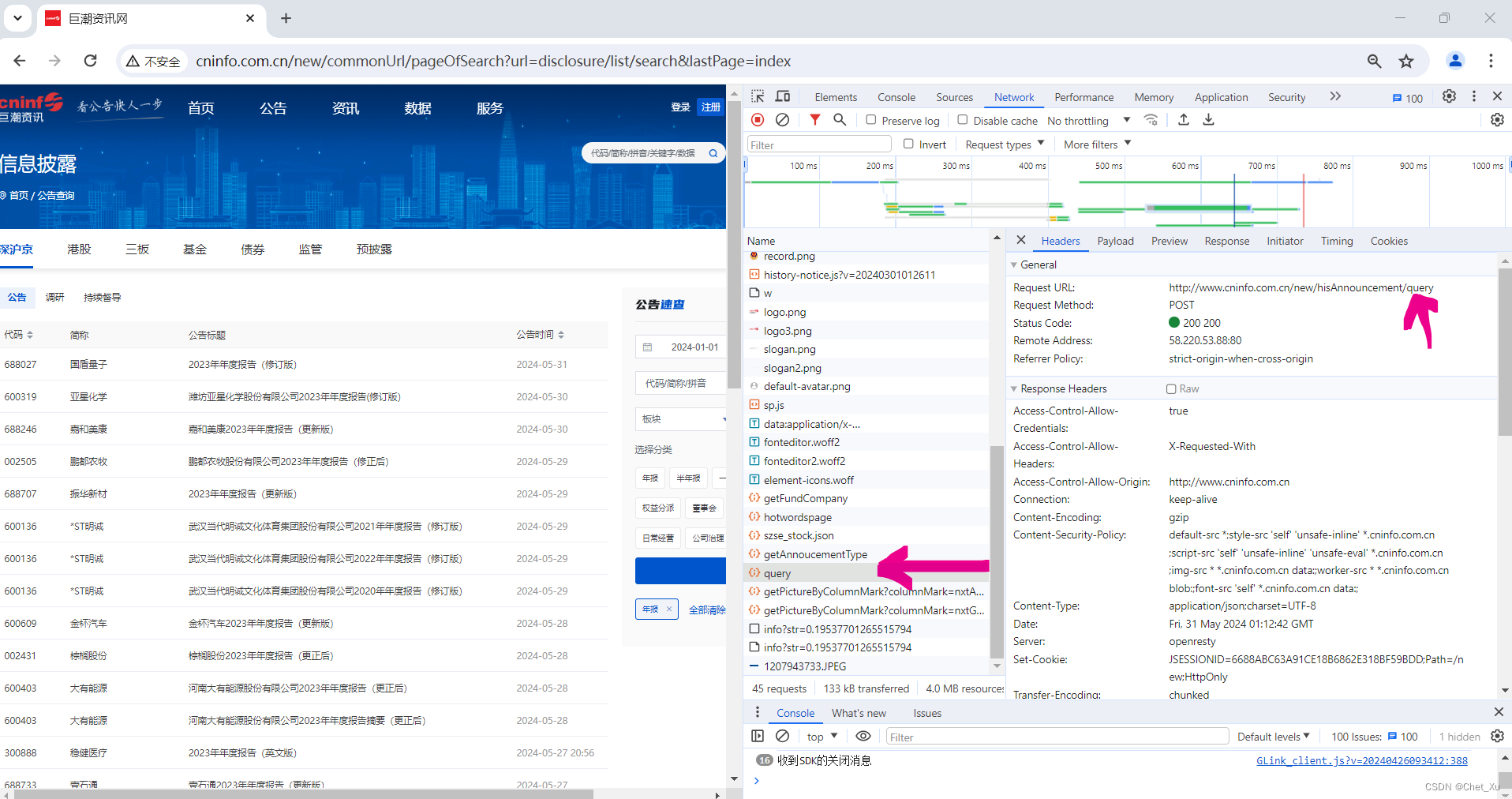
近期根据相关的要求准备对部分上市公司的年报做某方面的分析,想用Python处理一下,查了很多网站好像也没有特别好的解决方案,就准备在各位大佬的基础上自己写点代码试试,可能会分阶段分享一下,还请各位大佬拍砖,多提批评意见,多多支持……。 第一部分、Python高速下载巨潮资讯网上市公司年度报告 1、年度报告长什么样子?首先到巨潮资讯网上逛逛看各上市公司的年报在哪里,是什么样子。直接上图,看起来是一个PDF,要下载PDF,那么这个PDF的链接地址是什么呢? 进入您度报告页面,直接F12调出开发工具查看。在Source下边可以清楚的看到年度报告的连接URL。 点击查询按钮可以看到开发工具中的相关信息,主要是关注其中的query里的内容。 3.1、请求URL: url = 'http://www.cninfo.com.cn/new/hisAnnouncement/query'
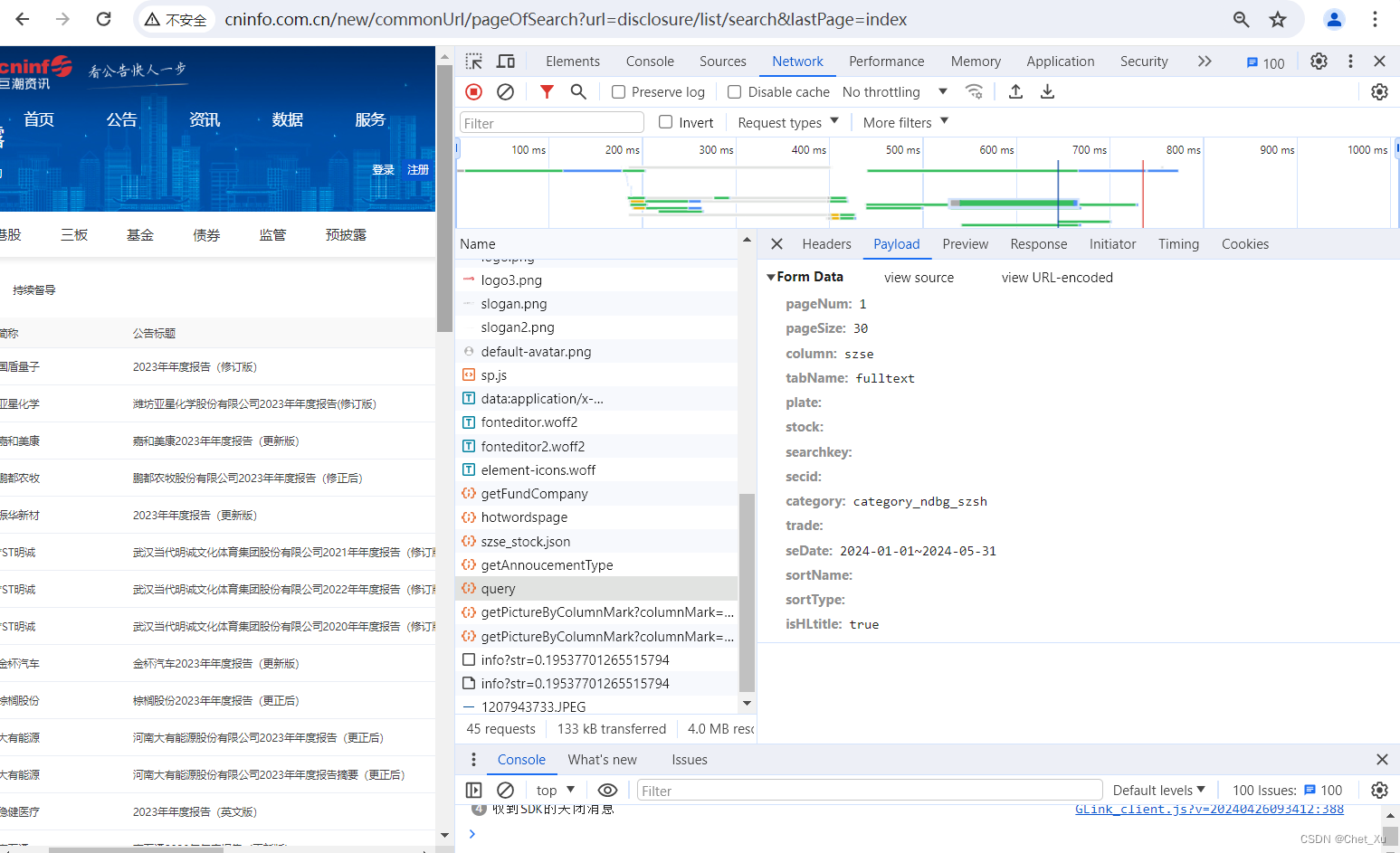
对于header基本不需要处理,因为Python 的requests已经包含的相关的处理。 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36", # 其他必要的headers... } 3.3、请求Data:先看一下图示内容:
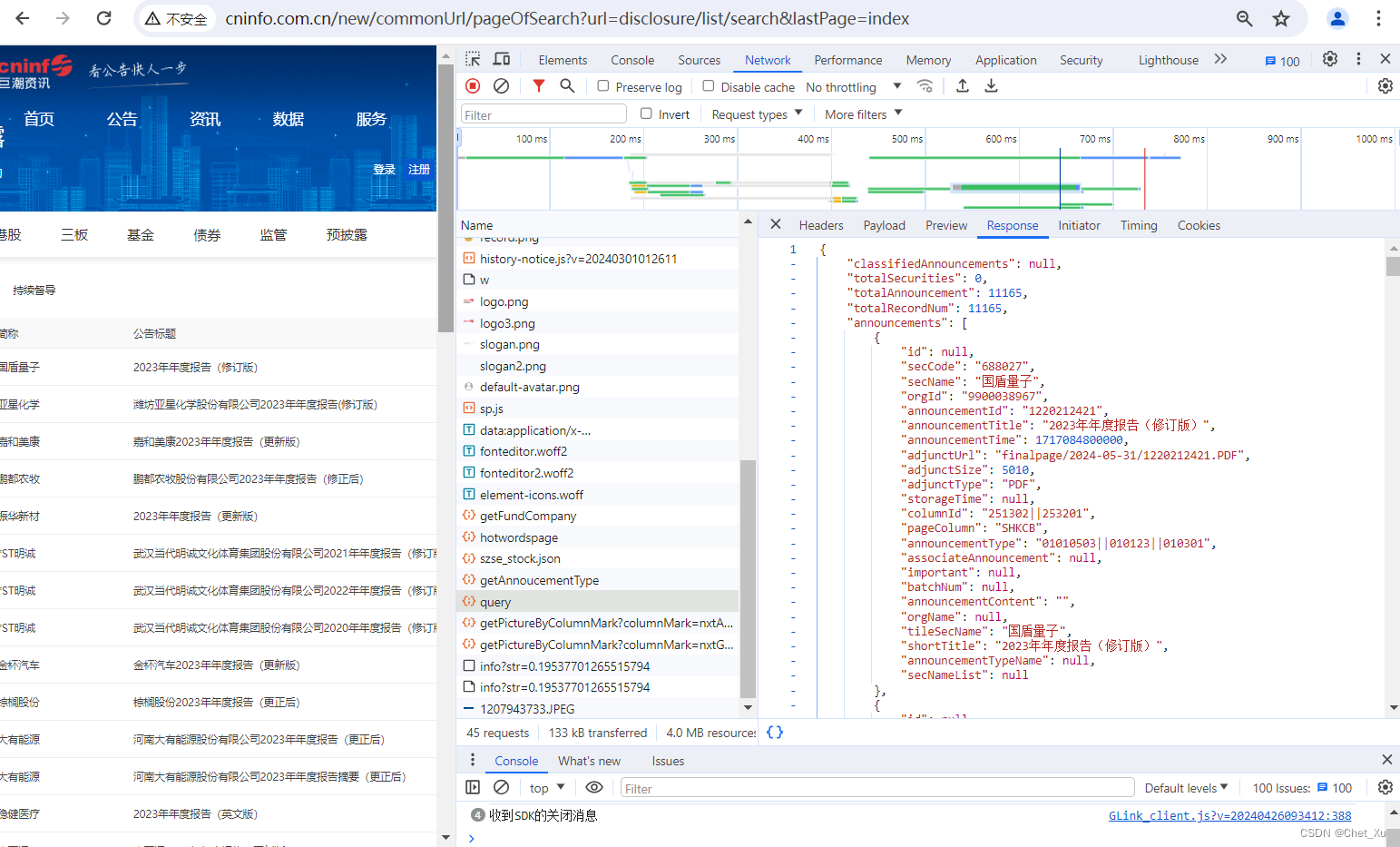
据此创建请求数据,仅获取年度报告,发布日期从去年22月30日至2024年5月30的,相关的内容可以根据自己的需要进行改变,也可以爬取其他类型的报告。 def generate_request_data(page_num): return { "pageNum": str(page_num), "pageSize": "30", "column": "szse", "tabName": "fulltext", "plate": "", "stock": "", "searchkey": "", "secid": "", "category": "category_ndbg_szsh", "trade": "", "seDate": "2023-11-30~2024-05-30", "sortName": "", "sortType": "", "isHLtitle": "true" } 3.4、响应数据:获取总共有多少页的年度报告。如下图中的ToTalpages total_pages = response.json()['totalpages'] + 1
每一个报告的信息,这里最关注的adjunctUrl、tileSecName、shortTitle。
通过内外两个循环获取每页中每个公司的年度报告: for i in range(1, total_pages): data = generate_request_data(i) response = session.post(url, headers=headers, data=data) response.raise_for_status() # 确保请求成功,抛出异常。 for item in response.json()['announcements']: file_url = 'https://static.cninfo.com.cn/' + item['adjunctUrl'] shortTitle = item['shortTitle'] tileSecName = item['tileSecName'] report_name = tileSecName + ':' + shortTitle file_name = f"{report_name}.pdf" 4、性能提升 4.1 创建Session # 创建一个Session对象, 使用Session对象来保持连接,减少每次请求时建立和断开连接的开销。 session = requests.Session()4.2、使用多线程下载PDF from concurrent.futures import ThreadPoolExecutor, as_completed with ThreadPoolExecutor(max_workers=5) as executor: # 使用线程池执行多线程下载 5、可靠性 # 使用os.path.join来拼接文件路径,这样可以确保跨平台兼容性。 file_path = os.path.join(folder_path, file_name) #使用with语句确保文件正确关闭。 with open(file_path, 'wb') as file: file.write(response.content) return file_path 6、完整代码 import os import requests from concurrent.futures import ThreadPoolExecutor, as_completed # 创建一个Session对象, 使用Session对象来保持连接,减少每次请求时建立和断开连接的开销。 session = requests.Session() url = 'http://www.cninfo.com.cn/new/hisAnnouncement/query' # 自动生成的文件头信息 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36", # 其他必要的headers... } # 生成请求数据的函数 def generate_request_data(page_num): return { "pageNum": str(page_num), "pageSize": "30", "column": "szse", "tabName": "fulltext", "plate": "", "stock": "", "searchkey": "", "secid": "", "category": "category_ndbg_szsh", "trade": "", "seDate": "2023-11-30~2024-05-30", "sortName": "", "sortType": "", "isHLtitle": "true" } # 发送POST请求,获取总页数 response = session.post(url, headers=headers, data=generate_request_data(1)) response.raise_for_status() # 确保请求成功 total_pages = response.json()['totalpages'] + 1 # 定义下载文件的函数 def download_file(file_url, file_name, headers, page_num): response = session.get(file_url, headers=headers) response.raise_for_status() # 确保请求成功 folder_path = "D:\\WorkSpace\\StockAny\\2023AnnualReport" os.makedirs(folder_path, exist_ok=True) file_path = os.path.join(folder_path, file_name) # 使用os.path.join来拼接文件路径,这样可以确保跨平台兼容性。 #使用with语句确保文件正确关闭。 with open(file_path, 'wb') as file: file.write(response.content) return file_path # 外循环控制页数 with ThreadPoolExecutor(max_workers=5) as executor: # 使用线程池执行多线程下载 futures = [] for i in range(1, total_pages): data = generate_request_data(i) response = session.post(url, headers=headers, data=data) response.raise_for_status() # 确保请求成功,抛出异常。 for item in response.json()['announcements']: file_url = 'https://static.cninfo.com.cn/' + item['adjunctUrl'] shortTitle = item['shortTitle'] tileSecName = item['tileSecName'] report_name = tileSecName + ':' + shortTitle file_name = f"{report_name}.pdf" future = executor.submit(download_file, file_url, file_name, headers, i) futures.append(future) # 等待所有任务完成并打印结果 for future in as_completed(futures): try: print(future.result()) except Exception as exc: print(f"Generated an exception: {exc}") |

【本文地址】
今日新闻 |
推荐新闻 |