问题解决:遇到tomcat的假死问题,如何排查问题 |
您所在的位置:网站首页 › windows下tomcat日志 › 问题解决:遇到tomcat的假死问题,如何排查问题 |
问题解决:遇到tomcat的假死问题,如何排查问题
|
文章目录
问题场景问题环境问题原因排查过程查看tomcat的gc情况排查内存泄露问题HashMap死锁CLOSE_WAIT过多情况
总结参考链接参考图JVM结构TCP的三次握手和四次挥手
随缘求赞
问题场景
线上,有时候会遇到一种这样的情况:tomcat没有奔溃退出,输出日志也没有异常,但是界面访问就一直卡着。假如遇到这种情况,没错,你遇到了tomcat假死问题了。那么,该怎么排查这个问题呢?这个就是本文的重点了。
tomcat假死的原因有多种,这里罗列博主遇到的几种情况: HashMap死锁内存泄露CLOSE_WAIT过多 排查过程遇到这种tomcat假死的情况,先不着急重启应用,先排查一下。
以下是博主之前操作的过程: 查看tomcat的gc情况使用以下命令拿到对应的gc情况,命令如下: jmap -heap pid >> jvm_memory.log这个命令,主要是打印堆摘要,其中包括使用的GC算法、堆配置和生成堆使用情况等。博主生成的文件当中,关于GC部分如下: using thread-local object allocation. Parallel GC with 16 thread(s) Heap Configuration: MinHeapFreeRatio = 40 MaxHeapFreeRatio = 70 MaxHeapSize = 3221225472 (3072.0MB) NewSize = 2686976 (2.5625MB) MaxNewSize = -65536 (-0.0625MB) OldSize = 5439488 (5.1875MB) NewRatio = 2 SurvivorRatio = 8 PermSize = 134217728 (128.0MB) MaxPermSize = 268435456 (256.0MB) Heap Usage: PS Young Generation Eden Space: capacity = 935133184 (891.8125MB) used = 171217136 (163.28538513183594MB) free = 763916048 (728.5271148681641MB) 18.309385115350587% used From Space: capacity = 68878336 (65.6875MB) used = 41388552 (39.47119903564453MB) free = 27489784 (26.21630096435547MB) 60.089361043797574% used To Space: capacity = 67174400 (64.0625MB) used = 0 (0.0MB) free = 67174400 (64.0625MB) 0.0% used PS Old Generation capacity = 2147483648 (2048.0MB) used = 2142115640 (2042.8806686401367MB) free = 5368008 (5.119331359863281MB) 99.75003264844418% used PS Perm Generation capacity = 161087488 (153.625MB) used = 159574696 (152.18228912353516MB) free = 1512792 (1.4427108764648438MB) 99.06088795673566% used从输出结果,我们可以看到目前是在进行GC操作。
另外,我们也可以使用命令jstat来查看,命令如下: jstat -gcutil pid 250 7说明: pid: 进程号 250:间隔时间,单位为毫秒 7: 输出次数,这里指输出7次 因为当时排查的时候,没有使用这个命令。等问题解决了,才发现有这个命令,没办法复现当时的情况。
为了给大家讲解一下,就运行此命令,展示当前应用的情况: S0S1EOPYGCYGCTFGCFGCTGCT0.000.0082.1584.9499.84503885413.400287018355.98523769.3850.000.0086.0884.9499.84503885413.400287018355.98523769.3850.000.0090.8684.9499.84503885413.400287018355.98523769.3850.000.0093.8884.9499.84503885413.400287018355.98523769.3850.000.0097.5484.9499.84503885413.400287018355.98523769.38523.600.005.9684.9499.84503895413.476287018355.98523769.46123.600.0021.1984.9499.84503895413.476287018355.98523769.461说明:下面是各个选项的含义 列说明S0Heap上的 Survivor space 0 段已使用空间的百分比S1Heap上的 Survivor space 1 段已使用空间的百分比EHeap上的 Eden space 段已使用空间的百分比OHeap上的 Old space 段已使用空间的百分比PPerm space 已使用空间的百分比YGC从程序启动到采样时发生Young GC的次数YGCTYoung GC所用的时间(单位秒)FGC从程序启动到采样时发生Full GC的次数FGCT完整的垃圾收集时间(单位秒)GCT总垃圾收集时间(单位秒) 排查内存泄露问题一般应用运行了很久,突然才出现问题,可能是有几个原因: 外部原因的变化,如远程服务异常;内部原因的变化,如升级代码存在问题等。一般针对内存泄露,除了开发代码的时候,就进行规范之后,等运行之后,要查看该问题,特别是线上环境的话,最好将完整的JVM堆栈信息给dump下来。这个时候可以使用以下命令: jmap -dump,format=b,file=heap-dump.bin这个命令的作用为:将hprof二进制格式的Java堆转储到filename。live子选项是可选的。如果指定,则只转储堆中的活动对象。要浏览堆转储,可以使用jhat(Java堆分析工具)读取生成的文件。
转换的文件比较大,一般有几个GB。所以要从现场环境拿下来,肯定得先进行压缩,然后再下载。这里我推荐使用JProfiler来进行JVM分析。关于JProfiler,请自行搜索使用。
使用JProfiler打开head-dump.bin文件,就可以看到一个很明显的东西,截图如下:
在上图可以知道,在Classes页面,有一个类路径下面,生成了很多对象。我们点击Biggest Objects,截图如下:
从上图可以知道,有一个对象非常大,占据了1487MB。而从第一步拿到的堆栈信息,整个堆栈最大是3072.0MB。所以,初步可以判断是因为这个东西,导致了频繁的GC,进行导致tomcat假死。
通过咨询项目运维成员,说该对象属于以前的插件-听云,属于端对端监控的插件。该插件之前要下线的,但是没有执行成功。所以该插件目前还运行着。而最近听云服务器正式下线,所以导致tomcat连接听云出现问题。暂时锁定该问题,所以先安排运维人员移除该插件,并重启tomcat。其中也遇到一个问题,并形成博客《问题解决:启动tomcat,日志输出:java.lang.ClassNotFoundException: com.tingyun.api.agent.TingYunApiImpl》,有兴趣的小伙伴可以看看。 重启之后,目前运行将近一周了,还未发现tomcat假死现象。所以,可以肯定,这个插件是造成近期应用假死的元凶。
这个原因是属于近期频繁假死的真凶,但是运维人员反映,该应用在之前是会出现这种tomcat假死的情况的。只是频率不会像现在一天两次的情况,一般是数周会发生一次。所以,还是得继续排查。
在应用运行一段时间之后,使用阿里巴巴开源的arthas来进行问题排查。这个是排查Java问题的利器。关于arthas的使用,请自行登录官网查看。
登录机器,使用arthas连接应用,查看当前的线程情况,发现有意思的一幕,截图如下:
有两个线程一直挂着,没有退出过。通过命令thread查看该线程具体情况,截图如下:
如果曾经遇到过这个问题的话,应该可以知道,这个就是所谓的HashMap死锁问题。这个需要去查看具体的代码,查看为什么会发生死锁的问题。
从这个可以得到,假如这个HashMap死锁发生的频率不高,但是随着时间的推移,这种情况不断发生,就会将全部的连接给占据了,导致了tomcat没可用连接进行响应,就会导致tomcat假死的情况发生。这个就是为什么之前应用发生死锁的频率比较低,要数周才可能会发生一次。
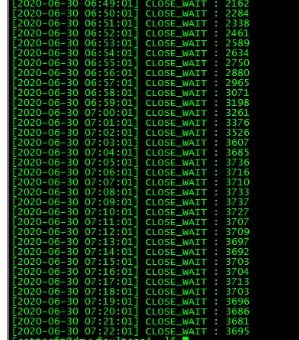
在实际场景,我们也会发现一种情况,tomcat假死的时候,使用以下命令获取TCP连接情况: netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'结果如下(命令可能和截图不同,因为这个是进行筛选并定时执行得到的):
可以看到,目前存在很多的CLOSE_WAIT。这个是因为服务端未及时释放资源。关于这个问题,除了可以修改Linux配置,我们也可以直接修改tomcat的配置文件,禁用wait,让连接在返回后立马关闭,成为一个可用连接。新增选项: 其中的keepAliveTimeout="0"是解决这个问题的关键。这个参数在其中一个应用进行试验,原本经常有CLOSE_WAIT,新增之后,基本没有,而且也没有报错。
通过实际的现场场景,展示了整个排查的过程,中间涉及jmap、jstack、jstat、arthas、jprofiler等命令及软件。熟练地使用这些命令,可以得到很多有用的信息,并加以解决。
jmap官方说明文档 jstack官方说明文档 jstat官方说明文档 arthas官方文档 参考图 JVM结构
如果我的文章对大家产生了帮忙,可以在文章底部点个赞或者收藏; 如果有好的讨论,可以留言; 如果想继续查看我以后的文章,可以点击关注 可以扫描以下二维码,关注我的公众号:枫夜之求索阁,查看我最新的分享!
|























【本文地址】
今日新闻 |
推荐新闻 |