CONFD: Analyzing Configuration Dependencies of File Systems for Fun and Profit(翻译) |
您所在的位置:网站首页 › win7系统怎么设置中文版本更新不了 › CONFD: Analyzing Configuration Dependencies of File Systems for Fun and Profit(翻译) |
CONFD: Analyzing Configuration Dependencies of File Systems for Fun and Profit(翻译)
|
CONFD:分析文件系统的配置依赖性以获得灵活性(fun and profit) 摘要-文件系统在现代社会中起着至关重要的作用,用于管理宝贵的数据。为满足不同的需求,它们通常支持许多配置参数。这种灵活性是以额外的复杂性为代价的,可能导致微妙的与配置相关的问题。为了解决这一挑战,我们深入研究了两个主要文件系统(即Ext4和XFS)的配置相关问题,并识别出一种称为多级配置依赖关系的普遍模式。基于这项研究,我们构建了一个可扩展的工具CONFD,用于自动提取依赖关系,并创建六个插件来解决不同的配置相关问题。我们在Ext4和XFS上的实验表明,CONFD可以以低误报率(false positive rate)提取文件系统的150多个配置依赖关系。此外,基于依赖关系的插件可以识别各种配置问题(例如,配置的处理不当,有效配置引起的回归测试失败)。 一、引言文件系统(FS),如基于Linux的操作系统(OS)上的Ext4 [54]和XFS [89]以及Windows OS上的NTFS [76],在现代社会中起着至关重要的作用。它们直接管理众多终端用户[12]的桌面、笔记本电脑和智能手机上的各种文件。此外,它们通常作为分布式存储系统(例如Lustre [63],GFS [1],HopsFS [22],MySQL NDB Cluster [73])的本地存储后端(backend),以实现规模化的存储管理。 为了满足不同的需求,许多文件系统都设计了一系列可通过实用程序控制的配置参数[41,45,48,52,56,58,94,100],使用户可以根据不同的权衡来调整系统。例如,Ext4包含超过85个配置参数,可以通过一组称为e2fsprogs的实用程序[52]进行修改。配置参数的组合代表超过10^37个配置状态[32]。 虽然配置参数提高了系统灵活性,但它们为可靠性带来了额外的复杂性。微妙的正确性问题通常依赖于特定的参数来触发[6,13];因此,它们可能会避开密集的测试,并对最终用户产生负面影响。例如,2020年12月,Windows OS的用户观察到NTFS的检查器实用程序(即ChkDsk[45])可能会破坏SSD上的NTFS[60,88]。事件最终被证明是与配置相关的:必须满足两个特定参数才能显示该问题,包括ChkDsk的“/f”参数和Windows OS中的另一个(未命名)参数[87]。 图1也展示了另一个涉及Ext4及其mke2fs和resize2fs实用程序[52]的配置相关问题。触发此错误的两个条件是:(1)在Ext4中启用sparse_super2功能(通过mke2fs);(2)resize2fs的size参数的值必须大于Ext4的大小(即扩展文件系统)。一旦触发,错误将使Ext4元数据损坏,并带有不正确的空闲块。问题的根本原因是逻辑上的:在特定配置下,在添加新块以进行扩展之前,会计算Ext4的最后一个块组的空闲块计数。  由于配置状态的组合爆炸以及在每个配置状态下仔细检查文件系统所需的大量时间,今天几乎不可能穷尽所有状态以进行彻底测试 [9]。随着越来越多的异构设备和先进功能的引入[65,83,86],配置状态预计会增长。因此,需要有有效的方法来帮助改善配置相关的测试,并有效地识别关键配置问题。 1.1 现有技术的局限性有一些实用的测试套件(test suites)可以确保文件系统在不同配置下的正确性(例如,xfstests [95])。不幸的是,它们在配置方面的覆盖范围有限:根据我们的研究,只有不到一半的配置参数被使用,这反映出需要更好的工具支持。此外,与配置相关的问题已经出现在其他软件系统中,并受到了很多关注 [4、13、24、33、35]。但不幸的是,现有的努力主要集中在单个应用程序中相对简单的配置问题(例如,拼写错误 [4]),这在解决涉及多个程序的文件系统配置挑战方面是有限的。有关详细信息,请参阅第 2 节。 1.2我们的努力与贡献本文介绍了解决文件系统日益增加的配置挑战的第一步。受最近一项关于 Hadoop [40] 和 OpenStack [77] 中配置问题的研究 [33] 的启发,我们关注配置依赖性,它描述了配置参数之间的依赖关系 [33]。这种依赖性已被确定为复杂性造成的问题的关键源头,捕获依赖关系对于改进配置设计和工具 [13、19、33] 至关重要。 虽然配置依赖性的基本概念已经在文献中提出(参见2节),但在文件系统环境中具体的依赖模式及其影响的理解仍然有限。因此,我们首先对两个主要文件系统(即Ext4和XFS)的78个配置相关问题进行了实证研究。通过审查实际的错误和相关的源代码,我们回答了一个重要的问题:文件系统中存在哪些关键的配置依赖关系。 我们的研究发现了一种称为多级配置依赖性的普遍模式。除了相对简单的配置约束(例如,值范围[13])之外,文件系统的不同实用程序的参数之间还存在隐式依赖关系。我们数据集中的大多数(96.2%)问题都需要满足这种深层配置依赖关系才能显现出来。有趣的是,应用于文件系统的工作负载不必是特定于配置的:71.8%的问题仅涉及通用文件系统操作。 我们基于研究,建立了一个可扩展的框架CONFD,用于自动提取多级配置依赖关系,并利用依赖指导的配置状态进行进一步分析。其中一个关键挑战是如何在通过不同实用程序指定的参数之间建立关联,这些实用程序具有不同的配置处理方式。我们通过元数据辅助的污点分析来解决这个挑战,它利用了给定文件系统的所有实用程序共享相同元数据结构的事实。此外,基于提取的依赖关系,我们创建了六个插件,以帮助从不同角度解决文件系统中的配置相关问题。 我们的实验表明,CONFD可以以低误报率(8.4%)为Ext4和XFS提取154种不同的配置依赖关系。此外,在依赖性指导下,CONFD插件可以识别各种配置相关的问题,包括不准确的文档、配置处理问题以及由有效配置引起的回归测试失败。 总之,本文具有以下贡献: 基于实际(real-world)问题,对文件系统的关键配置依赖性进行了分类;构建了CONFD原型来提取配置依赖关系,并暴露文件系统中的相关问题;与多种实用工具(如故障注入器(fault injector)[25],模糊测试器(fuzzer)[29],回归测试套件(regression test suites)[51,95])集成,以提高其配置覆盖率和有效性;在两个广泛使用的文件系统上评估方法,并证明其有效性。二、背景和相关工作2.1 背景文件系统配置。文件系统不同于许多应用程序的配置方法,这使得这个问题可以说更具挑战性。如图2所示,一个典型的文件系统可以通过一组实用程序在四个不同的阶段进行配置: 创建。在创建文件系统时,mkfs实用程序(例如,ext4的mke2fs)会生成初始配置。 挂载(Mount)。挂载文件系统时,可以通过mount指定某些配置(例如,“-o dax”以启用Direct Access或DAX功能[65])。 在线。许多实用程序可以通过在线修改元数据来直接更改已挂载的文件系统的配置(例如,Ext4 defragmenter(碎片整理程序) e4defrag[53],Windows NTFS checker(检查器) ChkDsk[45])。 离线。离线工具也可以修改文件系统映像并改变配置(例如,resize2fs [79],e2fsck [50])。 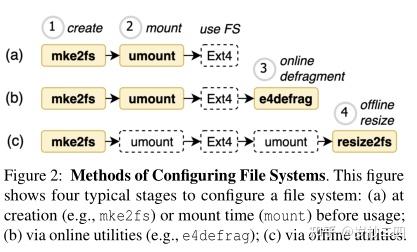 请注意,所有实用程序都有不同的配置参数来控制它们自己的行为,这最终会影响文件系统状态。此外,配置参数可能会在文件系统映像创建后很长一段时间内影响文件系统的行为,并且某些配置在以后无法更改。此外,参数的验证可以在用户级和内核级进行。例如,mke2fs的‘-O inline_data’参数和mount的‘-o dax’在ext4的ext4_ill_super函数中得到了进一步的验证。因此,我们认为有必要将文件系统本身以及所有关联的应用工具视为FS生态系统,以应对配置挑战。为简单起见,我们将文件系统和应用工具称为FS生态系统中的组件。 多阶段配置方法在文件系统中很常见。如表1所示,许多流行的文件系统遵循类似的模块化设计(modular designs),并且可以在不同的阶段通过不同的实用程序进行配置。因此,我们认为多组件配置的挑战是普遍的。我们在这项工作中重点关注ext4和XFS,因为它们是Linux上的两个主要文件系统,并且它们支持针对非易失性存储器(non-volatile memories, NVM)的最新DAX[65]配置。我们把其他的留作将来的工作(第6节)。  表一:不同文件系统的配置方法示例。最后四列列出了可以影响文件系统配置状态的示例实用程序。  FS测试套件。实际测试套件已经创建,以确保文件系统在各种配置下的正确性。不幸的是,由于配置的复杂性,它们在配置方面的覆盖范围有限。正如表2所示,根据我们的研究,在Linux文件系统的标准测试套件中(即xfstests [95],e2fsprogs / tests [51]),使用的配置参数不到一半。由于每个参数可能具有代表不同状态的广泛范围的值,因此未检测到的配置状态的总数量远多于未使用参数的数量,这意味着需要更好的工具支持。 配置约束和依赖性。配置约束和依赖性。配置约束指定软件的配置要求(例如,数据类型、值范围)[13]。直观地说,此类信息可以帮助识别重要的配置状态,并且它已被证明可有效解决广泛应用程序中的配置相关问题 [4、8、13、14、33]。配置依赖是一种特殊类型的约束,描述了参数之间的依赖关系/相关性(correlation) [13, 33],最近表明它对于解决云系统中的复杂配置问题至关重要 [33]。为简单起见,我们在本文的其余部分交替使用约束和依赖关系。请注意,虽然已经提出了基本概念,但在文件系统的上下文中对它们的理解有限。本文试图填补这一空白。 2.2 相关工作软件配置分析。软件配置问题已经在许多软件应用中得到研究[4,6,7,13,14,24,33,35]。例如,ConfErr [4] 操纵参数来模拟人为错误;Ctests[35]检测失败诱导的配置更改。一般来说,这些工作不会分析软件内部的深度依赖关系。最接近的工作是 cDEP [33],它特别观察 Hadoop [40] 和 OpenStack [77] 中的组件间依赖关系。不幸的是,他们的解决方案在很大程度上不适用于文件系统。这是因为它们的目标组件共享配置规范(例如 XML)和库 [39],这使它们在配置方面等同于一个单独的程序。相比之下,文件系统中的配置依赖可能跨越不同的程序和用户内核边界,这需要非常规(non-trivial)的机制来提取。此外,cDEP 依赖于Java 框架 [82],无法处理基于 C 的文件系统。 文件系统的可靠性。为了提高文件系统 [2、10、17、18、29] 及其实用程序 [3、25、26、27、78] 的可靠性,人们付出了巨大的努力。例如,Prabhakaran 等人 [2] 应用故障注入来分析文件系统的故障策略,并提出基于 IRON 分类法的改进设计; Xu 等人 [30] 和 Kim 等人 [29] 使用模糊测试来检测文件系统错误; SQCK [3] 和 RFSCK [25] 改进了文件系统的检查器实用程序以避免不准确的修复。尽管这些工作对其原始目标有效,但它们不考虑多组件配置问题。另一方面,本文的配置依赖关系可以与这些现有的工作集成,以提高它们的覆盖范围(见4.2节)。因此,我们将它们视为互补的。 配置管理工具。面对日益增加的挑战,从业者已经创建了专门的配置管理框架 [31、44]。例如,Facebook HYDRA [31] 支持优雅地管理分层配置。虽然有助于开发新应用程序,但重构 FS 生态系统以利用此类框架将需要大量努力(如果可能的话)。值得注意的是,该框架支持自动运行具有不同配置组合的程序。但是,由于它不理解配置依赖关系,它可能会生成许多无效的配置状态(参见5.2.3节)。本文旨在解决这些限制。 三、文件系统中的配置依赖在本节中,我们将对 Ext4 和 XFS 生态系统进行研究,以了解配置问题的潜在模式并指导解决方案的设计。我们分别在 §3.1 和 §3.2 中讨论了方法和发现。 3.1 方法论我们的数据集包括两部分:(1)Ext4和XFS的源代码以及包括mke2fs、mount、e4defrag、resize2fs、e2fsck、mkfs.xfs和xfs_repair在内的七个重要实用程序,其详细描述见表3;(2)两个文件系统生态系统的一组78个与配置相关的错误补丁,这些补丁是通过关键字搜索(例如“配置”、“参数”、“选项”)、随机抽样和手动验证从源代码存储库的提交历史中收集而来的。请注意,补丁收集方法受到先前关于真实世界bugs的研究[5,12,36]的启发。虽然耗时,但已被证明对系统改进有价值[5,12]。另一方面,与先前的研究一样,应该以此方法来解释我们的研究结果。例如,78个补丁只代表触发和修复的问题的一个子集;可能还有其他尚未发现的配置相关问题(有关进一步讨论,请参见6节)。 3.2 发现基于数据集,我们深入分析了每个补丁和相关源代码以了解逻辑,从而能够识别关键的配置使用场景和配置约束。我们在表 3 和表 4 中总结了我们的发现,并在下面进行讨论。 发现#1:大多数情况 (96.2%) 涉及来自多个组件的关键参数。表 3 的第一列显示了文件系统的六种典型使用场景,涵盖了我们数据集中的所有错误案例(总共 78 个)。 96.2% 的错误案例需要至少两个关键实用程序(即每个使用场景中以粗体显示的实用程序)的特定参数才能显示出来。这反映了问题的复杂性,表明我们不能只考虑一个单一的组成部分。 发现#2:存在配置依赖关系的层次结构(hierarchy)。我们将从数据集中导出的配置约束分为以下三大类: 自依赖性 (Self Dependency,SD) 意味着各个参数必须满足自己的约束(例如,数据类型或值范围)。例如mke2fs的blocksize参数取2222222值范围为1024-65536,必须是2的幂。 • Cross-Parameter Dependency (CPD) 是指同一组件的多个参数必须满足相对关系约束(例如,两个 mke2fs 参数 meta_bg 和 resize_inode 不能一起使用)。 • 跨组件依赖性(Cross-Component Dependenc,CCD) 是指一个组件的参数或行为依赖于另一个组件的参数。图 1 中的两个依赖项都属于此类,因为它们涉及 mke2fs 的参数并且 resize2fs 的(错误)行为依赖于它们。 正如表 4 中总结的那样,每个主要类别可能包含几个描述更具体约束的子类别。这些约束一起形成了一个层次结构,我们称之为多级配置依赖关系。请注意,我们只观察了数据集中 8 个子类别中的 7 个。为了完整性,我们根据文献 [13] 在 CPD 中包含了看不见的“价值”子类别。  除此之外,在所有依赖关系中,有一个子集直接导致我们数据集中的错误:相关参数在错误补丁中明确提及,并且需要修改相应的功能来修复错误(即它们与根本原因有关)。我们将这个依赖关系的子集称为关键依赖关系(critical dependencies)。每个子类别的关键依赖关系的计数显示在表4的最后一列中。我们总共能够手动提取168个关键依赖关系,这比错误案例的数量要多。这是因为可能需要多个关键依赖关系才能触发错误。例如,图 1 中的两个依赖项都是此错误案例的关键依赖项。 如表 3 最后三列所示,SD 和 CCD 几乎总是涉及所有场景(分别为 100% 和 96.2%),而 CPD 不可忽略(10.3%)。这是因为 SD 表示相对简单的约束,总是需要首先满足这些约束才能使目标组件工作(例如,正确的拼写)。 SD 相对容易检查,一直是以前工作的重点[4]。但是,这并不意味着如果SD被检查到或被满足,就可以100% 避免错误。例如,与 bigalloc 和 extent 参数相关的错误(即涉及 CPD)可能仍然会出现,即使这两个参数拼写正确。换句话说,仅仅考虑单个参数的简单约束是不够的。 有趣的是,我们在 DAX 特性(feature)和其他看似无关的配置之间同时观察到了 CPD 和 CCD。在一种情况下,当在 mke2fs 中使用“-O inline_data”并随后使用“-o dax”挂载映像(image)时,会触发损坏(corruption)。在另一种情况下,DAX 特性与“has_journal”配置冲突,这可能导致在线更改日志模式(journaling mode)时出现损坏。这种意想不到的依赖性意味着将 DAX 支持添加到 Linux 内核的复杂性。 发现#3:配置参数在 FS 生态系统中以异构(heterogeneous)方式处理。我们确定了 FS 配置中异质性的四个主要来源。首先,不同的参数可能会映射到代码中不同类型的变量。例如,Ext4 的参数可以(至少)四种不同的方式存储,包括(i)局部变量,(ii)全局变量,(iii)通过位操作访问的位图中的位,以及(iv)直接在超级块(superblock)中。其次,在超级块内,参数可以保存在一个单独的字段中(例如,s_log_block_size)或作为复合字段的一个成员。第三,参数可以直接从超级块加载,也可以通过库调用加载。最后,不同的组件可能使用不同的函数来处理配置(例如,resize2fs 使用“main”函数,而 mke2fs 调用一个名为“PRS”的特殊函数)。这种异质性使得以前的解决方案大多不适用。 发现#4:71.8%的情况不需要配置特定的工作负载才能显现出来。有趣的是,尽管很复杂,但许多错误可以在不应用特定配置的工作负载的情况下触发。这表明我们可以使用对文件系统[51,95]施加压力的现有工作,来有效地分析与配置相关的问题。 四、提取和使用多级配置依赖基于这项研究,我们构建了一个名为 CONFD 的可扩展框架,以利用依赖信息来解决与配置相关的问题。如图 3 所示,CONFD 由两个主要部分组成:(1)ConfD-core(黄框),用于提取多级配置依赖和生成关键的配置状态,其中包含三个子模块(即污点分析器(Taint Analyzer)、依赖关系分析器(Dependency Analyzer)和状态生成器(State Generator)); (2) ConfD-plugins(绿框),用于根据生成的配置状态检测各种与配置 相关的问题。我们分别在以下两个小节中对这两部分进行阐述。  4.1 抽取配置依赖4.1.1元数据辅助的污点分析 4.1 抽取配置依赖4.1.1元数据辅助的污点分析作为第一步,CONFD 的 Taint Analyzer 执行元数据辅助的污点分析并生成污点跟踪以捕获目标 FS 生态系统中配置参数的传播流。 它以目标系统的源代码作为输入,并使用 LLVM 编译器基础结构(infrastructure) [85] 生成源代码的中间表示 (IR)。然后,它基于经典的污点分析算法 [21],跟踪每个配置参数在 IR 中沿着数据流路径的传播。我们维护一个集合来保存初始配置变量和遍历 IR 时从初始配置变量派生的任何变量。当一个新变量被添加到集合中时,我们将相应的 IR 指令添加到污点跟踪中。我们维护每个配置参数与从中派生的变量之间的映射,以便在变量可能从多个参数派生时启用跟踪,这对于建立跨参数的相关性至关重要。我们的污点分析是上下文敏感的,可以处理内部程序和跨程序分析(intra-procedural and inter-procedural)。上下文敏感性对于跨程序分析很重要,因为一个函数可以从不同的上下文中调用,这对于准确推导不同污点跟踪(trace)之间的依赖关系也至关重要(§4.1.2)。 我们遇到的一个独特挑战是如何在 FS 生态系统的不同组件的参数之间建立映射。如 §3.2 所述,FS 生态系统中的组件倾向于以不同的方式加载配置,并使用不同的变量或函数处理等效的 FS 信息。我们基于一个关键观察来应对这一挑战:所有组件都需要访问相同的 FS 元数据结构。我们可以利用共享元数据结构来连接不同组件的相关参数。 更具体地说,与文件系统配置相关的参数值(最终)存储在文件系统的超级块结构中。例如,来自 mke2fs 的参数 -I inode-size 存储为超级块的第 27 个成员 (s_inode_size)。当另一个组件(例如,e2fsck)从超级块加载 s_inode_size 来访问它时,它本质上取决于 mke2fs 的 -I inode-size 参数。我们通过跟踪参数值在超级块中的写入位置,将 mke2fs 参数值映射到相关的超级块字段。同样,也跟踪其他组件对超级块的访问。基于对相同超级块字段(例如s_inode_size)的映射,我们可以建立不同组件的污点跟踪之间的联系。 请注意,由于 CONFD 在 LLVM IR 级别实现了污点分析,因此任何可以编译为 LLVM IR 的文件系统都可以从中受益以进行配置依赖性分析。当前原型使用支持 C/C++/Objective-C 语言的 LLVM 的 Clang 前端 [85] 4.1.2多级依赖分析给定每个配置参数的污点痕迹,依赖分析器根据我们的研究 (§3) 得出的多级依赖关系进一步分析参数之间的潜在相关性。 具体来说,每个参数的自依赖性 (SD) 是根据变量的数据类型和取值范围从它们各自的污点痕迹中导出的。我们还根据错误语句可能指示无效范围的观察,在范围检查之后立即检查错误语句。对于 CPD 和 CCD,我们比较了多个参数的污点痕迹。如果有公共线(上下文相关),我们认为它们是相关的。此外,在获取依赖(dependent)参数后,我们还利用后续的错误语句来进一步分析具体的依赖类型(例如,应该一起启用或禁用)。例如,mke2fs 中的两个参数 resize_inode 和 meta_bg 不能一起启用,因此在两个污点跟踪共享的条件检查之后必须有一个公共错误语句。所有提取的依赖项都以 JSON 格式存储[61],以简洁地描述参数和相应的依赖关系。 4.1.3依赖引导的状态生成使用依赖信息,状态生成器生成具体的配置状态以供进一步分析。相比于随机生成可能容易导致无用状态的配置组合(§5.2.3),它利用提取的多级依赖性来选择性地生成状态。 具体来说,State Generator 使用树形结构来维护不同的配置状态。树的根代表默认的配置状态,每个子节点表示与其父节点相比只有一个修改的配置状态。该模块的运行类似于树上的深度优先搜索 (Depth First Search,DFS),只是它利用依赖信息来指导哪些子节点值得追求。例如,给定 mke2fs 的 bigalloc 和 blocksize 参数之间的交叉参数依赖(CPD),如果当前节点修改 bigalloc,那么要考虑的子节点将是一个修改了 blocksize 的状态。 此外,该模块有许多选项,可以根据需要进行调整。第一个选项是“depth”,它决定了 DFS 允许的深度。较大的值会导致生成更多的状态。默认的“depth”是 3,这在我们的实验中效果很好。另一种选择是状态生成器运行所依据的“policy”。有以下两个基本政策: 遵循依赖关系。在此策略下,我们在创建配置状态时始终遵循提取的多级依赖关系。例如,如果根据多级依赖关系为mke2fs启用了RESIZE_INODE,则应始终启用sparse_super,因此模块可能会生成同时具有两个参数的状态(即‘mk2fs-O RESIZE_INODE,SISPSE_SUPERY’)。本质上,该策略仅为目标文件系统生态系统生成涉及关键参数的有效配置状态,这是正确运行许多文件系统应用程序或工具的基本要求。请注意,该策略与最近关于测试配置更改的工作是一致的,该工作表明有效的配置更改可能导致生产失败[35]。 违反依赖关系。在此策略下,我们在创建配置状态时故意违反多级依赖关系。例如,mke2fs的RESIZE_INODE和SPARSE_SUPERR参数具有跨参数依赖关系(CPD):如果我们想要启用RESIZE_INODE,则必须启用稀疏_SUPER。为了违反CPD,模块可能会故意生成一个禁用sparse_super参数但启用resize_inode的状态(即“mke2fs-O resize_inode,ˆsparse_super”)。通过故意生成无效配置状态,我们可以检查目标系统的(错误)配置处理。请注意,此策略的灵感来自于之前关于模拟配置中的人为错误的工作[4]。然而,与已在成熟系统中得到很大处理的相对浅层违规(例如拼写错误)不同,我们考虑更微妙的违规,涉及非平凡(non-trivial)的依赖关系。 此外,为了为不同的用例提供更大的灵活性,状态生成器支持使用不同的权衡(例如,要考虑的参数数量、要使用的依赖类型(即SD/CPD/CCD))进一步定制两个基本策略。正如前面提到的,分析文件系统配置的一个关键挑战是空间太大,无法耗尽。例如,mke2fs本身就有超过8万亿个可能的参数组合。有了依赖关系指导,ConfD可以根据用例(use case)将空间减少到数百或数万(§4.2),这使得配置测试在实践中更易于管理。正如§5.2.1所示,依赖关系引导的状态生成将比依赖关系不可知的替代方案更有效地暴露配置问题。 4.1.4用户输入ConfD-core需要来自用户的三种类型的输入信息,可以在一个单独的JSON文件中指定。首先,要启动污点分析,污点分析器需要一个函数名作为入口点。对于实用程序,函数(可能调用子函数)预计将是处理配置的主要函数。对于文件系统本身,函数可以是用于处理配置的函数,也可以是感兴趣的函数(例如,新添加的FS函数)。其次,污点分析还需要源代码中表示配置和超级块的变量的名称,根据我们在ext4和XFS生态系统上的经验,这些名称在不同的程序中通常是不同的。第三,要生成有效的配置状态,状态生成器需要FS配置的命令行语法。请注意,所有输入都可以用JSON格式指定,对于要分析的每个程序,这是一次性工作。 4.2 利用配置依赖可以以不同的方式使用依赖性信息和依赖性引导的配置状态来解决不同的问题[4、13、33]。正如§2.2中提到的,现有的改进FS生态系统的工作涵盖了广泛的技术,包括故障注入(fault injection)[2,25]、模糊(fuzzing)[29,30]、回归测试套件[51,95]等。虽然这些工具对于它们的原始设计目标非常优秀,但它们大多与配置依赖无关,因此不能有效地解决棘手的配置相关问题。 当前的 CONFD 原型包括六个插件。如表 5 所示,前两个插件(#1 和#2)是从头构建的,接下来的两个插件(#3 和#4)基于开源研究原型(R),最后两个( #5 和 #6) 旨在增强标准测试套件 (S)。我们在下面更详细地讨论它们:  插件#1:配置规范检查器。Linux 文件系统的配置规范通过 Linux 手册页(man-pages)项目 [84] 进行维护。不幸的是,由于各种原因(例如,不断的系统升级、功能添加、错误修复),规范可能很容易变得不准确,这可能会使终端用户感到困惑,和/或导致配置相关的故障 [35、64]。 ConfD-specCk 插件旨在缓解该问题。它解析与文件系统配置(例如 mke2fs、mkfs.xfs)相关的 Linux 手册页,并根据关键字检查多级依赖关系的子集(表 4)。例如,对于 mke2fs(即 CPD),resize_inode 和 meta_bg 不能一起启用,因此meta_bg应该以“禁用”(或类似关键字)的形式出现在resize_inode的描述中,反之亦然。同样,值范围(即SD)和其他值依赖关系(例如,cluster_size需要“等于”或“大于”block_size)也应该在相应的描述中指定。这些来自man-pages的依赖关系以JSON格式存储,以便与ConfD-core(§4.1)从源代码中提取的依赖关系进行比较。不匹配意味着潜在的规范问题。 插件 #2:错误配置处理检查器。一个设计良好的文件系统应该能够优雅地处理来自最终用户的错误配置(无论是过失的还是有意的)。未能优雅地处理错误配置意味着错误配置漏洞(misconfiguration vulnerabilities)可能会损害系统可靠性和/或安全性 [13]。 ConfD-handlingCk 插件旨在暴露错误配置处理中的潜在问题。由于内置的“违反依赖性”策略(§4.1.3),插件可以直接利用 CONFD 生成的违反固有配置依赖性的无效配置状态。它应用此类自动生成的错误配置来驱动目标文件系统和实用程序,并相应地记录症状以供事后分析。 插件 #3:依赖性感知故障注入器。故障注入技术已被应用于改进文件系统和实用程序 [2、15、25、28、51]。通过系统地生成损坏的文件系统状态,它们能够彻底分析 FS 生态系统的稳健性(robustness)。然而,鉴于文件系统元数据的复杂性,一个公开的挑战是如何有效地生成易受攻击的状态。为了缓解挑战,我们通过 ConfD-rfsck 插件将一个开源故障注入器 rfsck [25] 与 CONFD 集成在一起。 ConfD-rfsck 不依赖于默认配置,而是利用依赖性引导配置来生成输入图像以启动故障注入活动。由于输入映像配置有由 CONFD 识别的相关参数,因此它们表示更复杂的状态,在错误情况下更难以保持一致。请注意,插件只需要提供具有不同配置的 FS 图像作为 rfsck 的输入。无需修改 rfsck 的源代码。如 §5.2 所示,这个简单的策略可以帮助有效地触发漏洞。 插件 #4:基于依赖的文件系统模糊测试(Dependency-aware FS Fuzzer.)。模糊测试技术也被用于提高文件系统的可靠性 [11, 29]。尽管如此,由于在每种配置下运行实际文件系统需要很长的状态探索时间(例如,可能需要数周时间才能触发一个错误 [29]),因此模糊文件系统仍然具有挑战性。换句话说,探索不太有趣的配置状态的时间代价很高。为了减轻挑战,我们通过 ConfD-gt-hydra 插件将一个开源模糊器 gt-hydra 2 与 CONFD 集成在一起。与插件 #3 类似,ConfD-gt-hydra 利用 CONFD 生成的依赖项引导配置来创建具有更复杂依赖项的 FS 映像,因此更容易出现模糊测试漏洞。该插件仅更改 gt-hydra 输入图像的配置;无需修改基础工具的源代码。 插件 #5 & #6:依赖关系感知回归测试套件。除了研究原型,还有为文件系统开发的标准回归测试套件(例如,xfstests [95] 和 e2fsprogs/tests [51]),其中包括精心设计的工作负载和测试oracle,以确保目标的质量。然而,现有的测试套件只使用配置参数的一个子集,而且它们大多是依赖不可知(dependency-agnostic)的。为了解决这个限制,我们创建了两个插件:ConfD-xfstests 和 ConfD-e2fsprogs,分别用于 xfstests 和 e2fsprogs/tests。插件扫描测试脚本并使用CONFD生成的配置状态自动替换测试用例的内置 FS 配置 这两个插件使用CONFD的“遵循依赖关系”策略来驱动测试用例深入到目标功能中,而不会因为表面的配置错误而提前终止。在这样做的过程中,我们重用了精心设计的测试逻辑,并使用依赖关系意识增强了测试套件。如果任何测试用例使用CONFD提供的有效配置失败,则结果将被保存以供事后分析。 五、实验结果在本节中,我们描述了应用ConfD分析ext4和XFS的实验结果。首先(§5.1),我们证明了ConfD能够有效地从目标系统中提取154个多级配置依赖项,并且具有较低的误报率(8.4%)。其次(§5.2),我们证明了与现有的依赖项无关的解决方案相比,ConfD可以更有效地帮助解决与配置相关的问题。通过实验,我们发现了各种与配置相关的问题,包括17个规范(specification)问题,18个配置处理问题,以及10个由有效配置导致的回归测试失败。 5.1 ConfD可以提取多级依赖关系吗?表6总结了ConfD自动从ext4和XFS中提取的多级配置依赖项。如表所示,我们总共能够提取154个唯一依赖项,包括35个自依赖项(SD)、58个跨参数依赖项(CPD)和61个跨组件依赖项(CCD)。在ext4和XFS上都观察到了多级依赖关系,这与我们的手工研究(§3)一致。 我们手动检查了ConfD自动提取的所有154个依赖项,发现总体误报率为8.4%(13/154),这与之前分析其他软件系统中的配置约束的工作相似[13,33]。请注意,ConfD旨在处理FS生态系统的独特配置方法(§2和§3.2),与现有工作的目标相比,这可以说是更具挑战性的分析方法。  5.2 ConfD能否帮助解决配置问题?5.2.1依赖不可知型与依赖引导型 5.2 ConfD能否帮助解决配置问题?5.2.1依赖不可知型与依赖引导型在这一部分中,我们将比较两个开源研究原型(即,rfsck[25]和GT-Hyda[29])在有和没有ConfD支持的情况下的有效性。我们将重点放在这两个研究原型和相应的插件上进行比较,因为它们提供了量化的度量来直观地衡量有效性。我们将其他插件的结果推迟到下一节。 在第一个实验中,我们使用故障注入器(fault injectors)rfsck和confd-rfsck来分析ext4及其检查器实用程序e2fsck。故障注入器中断检查器操作并检查中断的检查器是否可能导致文件系统上不可修复的损坏(即,不能通过另一次运行的检查器来修复)。它们报告修复的FS映像的数量,其中包含无法修复的损坏(即“无法修复的映像”)。每个无法修复的映像都意味着FS生态系统中存在一个可能导致数据丢失的漏洞[25]。 实验结果汇总在表 7 中。rfsck使用默认配置报告了11个无法修复的映像。ConfD-RFSCK可以探索不同的配置状态,并对25种配置状态下生成的报告进行了分析比较。在25个中的4个状态,ConfD-rfsck生成的不可修复的映像少于11个;在4个状态下,ConfD-rfsck生成相同数量的不可修复的映像(即‘=11’);在大多数状态(17个)中,ConfD-rfsck生成更多不可修复的映像(即‘>11’),这表明它在暴露FS生态系统中的潜在漏洞方面更有效。 表8进一步比较了rfsck和confD-rfsck引发的不可修复的损坏症状。总体而言,ConfD-rfsck会触发三种不同类型的症状,而rfsck在我们的实验中只会触发一种症状。由于不同的症状通常意味着FS生态系统中元数据保护和/或恢复中的不同漏洞,因此结果还表明,confD-rfsck使用的依赖关系引导的配置状态可以帮助提高rfsck的有效性。 在第二个实验中,我们应用gt-hydra和ConfD-gt-hydra对ext4文件系统进行了模糊处理(fuzz)。模糊器(fuzzers)系统地生成各种输入(即,FS元数据损坏和系统调用)以探索文件系统中用于触发潜在错误的不同代码路径[29]。我们每个模糊器连续运行两周。模糊器报告在运行期内在目标文件系统上检测到的可靠性问题的数量。根据所使用的错误检查器,问题可能包括不同类型。我们使用默认的SYMC3检查器,可以检测崩溃不一致性错误(crash inconsistency bugs)。 同时,由于模糊器基于AFL Fuzzer[38],它们也默认报告崩溃和挂起问题(由AFL检测)。请注意,ConfD-GT-Hyda引入的唯一区别是依赖关系引导的配置,即它不会更改报告问题的测试逻辑或标准。因此,可以使用问题的类型(例如“崩溃”,“挂起”,“崩溃不一致性”)和报告的问题数量作为评估有效性的度量标准。 模糊实验的结果总结在表 9 中。为了使比较公平,我们将两个模糊测试器限制在相同的总执行时间(即每个两周)。我们将 ConfD-gt-hydra 设置为每 12 小时切换到一个新的依赖驱动的配置状态,在两周内探索28个关键配置状态。虽然探索 ConfD-gt-hydra 中的每个配置的时间仅为 gt-hydra 用于其配置的 1/28,但 ConfD-gt-hydra 的总体结果更好:gt-hydra在两周期结束时只检测到Ext4上的1个问题,而ConfD-gt-hydra总共检测到17个问题。有趣的是,实验中报告的所有问题都是“挂起”的。这是意料之中的,因为触发更复杂的语义错误可能需要数周时间。    综上所述,以上两组对比实验表明,CONFD 可以增强现有 FS 工具快速识别漏洞的有效性,这对于故障注入或模糊测试等耗时方法特别有价值。请注意,在所有实验中,我们不会随机生成配置组合。这是因为没有任何内在依赖性(inherent dependencies)知识的朴素算法很容易导致浪费时间的配置,这将在 §5.2.3 中进一步演示。 5.2.2配置问题总结 表 10 总结了我们实验中由 CONFD 插件触发的配置相关问题。总体而言,我们观察到了 300 多个不同类型的问题。问题多种多样,因为插件是为不同的目的或基于不同的基础工具而创建的(表 5)。请注意,所有问题都需要由 CONFD 生成的依赖项引导的配置状态才能显示出来。换句话说,持续运行原始研究原型或标准测试套件无法暴露问题。此外,由于我们没有更改基础工具的测试逻辑,因此增强功能完全由来自 CONFD 的依赖信息提供。由于 ConfD-rfsck 和 ConfD-gt-hydra 已在 §5.2.1 中讨论过,我们将在下面重点介绍其他内容。 表 11 总结了 ConfD-specCk 检测到的规范问题。我们总共发现了 17 个不准确的规范问题。这些问题主要表现为未记录的关键依赖项或错误的依赖项,可能同时发生在Ext4和XFS上,涉及 SD、CPD 和 CCD。例如,CONFD 提取的 CPD 指定 mke2fs 的两个参数(即 meta_bg 和 resize_inode)不能一起使用,但 Linux 手册页(man-pages)中没有此 CPD。作为另一个例子,存在一种 CCD,这意味着当通过 mke2fs 启用 bigalloc 功能时,resize2fs 可能不会用于 Ext4。违反 CCD 可能会破坏文件系统,不幸的是,规范中没有提到这一点。  表 12 总结了通过 ConfD-handlingCk 识别的错误配置的次优处理。我们遵循文献 [13] 中的标准:当发生错误配置(即违反依赖关系)时,系统应查明有问题的参数的名称/值或其位置信息;否则就意味着错误配置漏洞。具体来说,根据不同的反应,有六种类型的错误配置漏洞,包括“提前终止”、“功能失败”、“无声违规”、“无声无知”、“崩溃/挂起”和“部分报告”( Early Termination’, ‘Functional Failure’, ‘Silent Violation’,‘Silent Ignorance’, ‘Crash/Hang’, and ‘Partial Report’.)。前五种类型基于 [13] 中的定义,而最后一种在我们的研究中是特有的,因为我们考虑了更复杂的多级依赖关系。 例如,mke2fs 参数 -E encoding 启用 casefold 功能并在 Ext4 中设置编码。但是,如果用户在使用 -E encoding时尝试禁用 casefold 功能,该实用程序会在不通知用户的情况下静默启用 casefold 功能,而不是显示错误或警告。我们将此视为“无声违规”。 当违反多个依赖项时,实用程序通常只显示部分消息(即“部分报告”)。例如mkfs.xfs参数sunit涉及两个依赖:(1)它不允许有单位后缀(unit suffixes),(2)它不能和su一起指定。但是当两个依赖关系都被违反时,该实用程序可能只会显示其中一个违规情况。 总的来说,我们观察到 6 种次优反应中的 4 种,这表明 FS 生态系统无法避免其他实际系统(practical systems)中报告的错误配置漏洞。请注意,ConfD-handlingCk 利用 CONFD 的静态分析来小心地违反特定的依赖关系,这避免了许多用于测试的重复和有效配置状态。这减少了事后分析所需的手动工作。 在 ConfD-xfstests 和 ConfD-e2fsprogs 方面,我们观察到 10 个新的测试用例失败,这些失败可能是由 CONFD 生成的有效配置状态引起的。例如,当将在线碎片整理(defragmentation)工具 e4defrag 应用于启用了 bigalloc 功能的文件系统时,ConfD-xfstests 会触发 Ext4 损坏。请注意,一个 FS测试用例可能涉及多个实用程序。由于测试用例和 FS 生态系统的复杂性,在实践中,测试用例可能会由于各种微妙的原因(例如,挂载(mount)时)而失败,即使对于开发人员来说,诊断起来也很耗时 [47]。在我们的实验中,我们在更改有效配置后观察到超过 10 个新的失败测试用例。我们只计算在撰写本文时我们已经手动验证和复现的案例。此外,由于 CONFD 在不修改测试逻辑的情况下限制了对配置状态的更改,因此它可能有助于将测试用例失败的根本原因缩小到与配置相关的代码路径。 5.2.3状态生成:FB-HYDRA 与 CONFDCONFD 的一个独特功能是它根据多级依赖关系生成配置状态,这对于分析配置空间巨大的配置问题至关重要。据我们所知,FB-HYDRA 配置管理框架 [31] 提供了最相似的功能。它包括一个“多运行(multirun)”功能,以支持在不同的运行中自动运行具有不同配置的应用程序。我们在本节中比较了 FB-HYDRA 和 CONFD 生成的配置状态,以证明差异。 表13显示了在给定相同的配置参数集的情况下,FB-Hydra和ConfD为相同程序(即,mke2f)生成的状态。为了简单起见,我们在这个实验中只使用了10个有限范围的参数。如表所示,即使使用此简化方案,FBHYDRA也可能会生成许多重复或无效的状态。  这是因为FB-Hydra对mke2f的配置约束不敏感(agnostic)。具体地说,FB-Hydra为每个参数及其可能的值维护一个列表。它将所有列表传递给itertools.product()函数,该函数返回列表中值的笛卡尔乘积。这种简单的算法与FS生态系统不兼容。例如,‘mke2fs-b 1024-C 2048’和‘mke2fs-C 2048-b 1024’在实践中是等价的,但在FB-HYDRA中被认为是不同的。此外,由于违反依赖关系,FB-HYDRA很容易创建无效状态,这表明依赖关系分析的重要性。 请注意,FB-HYDRA具有CONFD没有的其他功能(例如,对Python库的支持)。此外,FB-Hydra支持插件,这使得从CONFD的状态生成中受益成为可能(有关更多讨论,请参阅§6)。因此,我们认为FB-HYDRA和CONFD是互补的。 6. 限制和未来工作没有任何研究或工具是完美的,我们的工作也不例外。在本节中,我们将讨论我们工作的局限性以及一些有希望的扩展。 多层次分类学的局限性。如§3.1中简要提到的,解释多级配置依赖关系时应考虑到研究方法,因为它们源自两个FS生态系统中与配置相关的不完整问题集。很可能在FS生态系统中存在更复杂的依赖关系,这值得进一步研究。 ConfD框架的局限性。当前的原型需要一些用户输入(§4.1.4)来指导自动依赖分析,我们希望通过更复杂的状态分析来减少这些输入。此外,ConfD只能处理用于污点分析的LLVM IR的一个子集,并且它一次只考虑CPD和CCD的两个参数,这可能会导致不完全依赖或误报。我们希望在未来通过更先进的软件工程工作来改进这些,这可能会进一步提高有效性。同样,插件也有局限性。例如,为了简单起见,ConfD-handlingCk对于一个配置状态最多只能导致两个违规;如果我们考虑两个以上的违规,可能会有更多的问题。由于不规则的配置处理,ConfD-xfstests只转换测试套件的一个子集。尽管有这些限制,但在我们的实验中,ConfD在分析依赖项和暴露与配置相关的问题方面一直很有效,所以我们相信它将对社区有价值。 其他文件系统和工具集成。如表1中所述,许多文件系统可以通过不同的实用程序进行配置,这些实用程序在进行少量定制(例如,以JSON格式4.1.4提供特定于FS的输入)之后,可能会从ConfD的多级依赖关系分析中受益。此外,除了当前插件中使用的基本工具外,ConfD还是对其他现代工具的补充。例如,FBHYDRA[31]使用YAML文件存储与ConfD使用的JSON文件兼容的配置。此外,它还支持一组名为“Sweepers”的插件来操作参数的选择。ConfD中基于依赖关系的状态生成可以作为FB-Hydra[31]的一个特殊“Sweepers”来实现。类似地,由ConfD生成的配置可以潜在地集成到CI/CD框架[62]中,以实现流水线的面向配置的测试和部署。我们将与其他文件系统(例如,ZFS)和工具的集成留到未来的工作中。 支持其他软件。配置依赖关系不仅限于文件系统。例如,NDCTL[74]是一个在Linux中配置libnvdimm子系统的实用程序。我们预计,将NDCTL添加到依赖项分析可能有助于更有效地解决特定于NVM的配置问题。此外,研究人员还观察到本地文件系统和其他软件(例如数据库[16]、分布式存储系统[20、23、34、37])之间的功能或正确性依赖关系,其中许多也与配置有关。这项工作中研究的依赖关系可以作为研究文件系统以外的配置相关问题的基础。此外,由于LLVM支持通过各种前端将多种语言(如C++、RUST、SWIFT)编译成IR[85],ConfD的核心分析预计也适用于用其他语言编写的软件。 更好的配置设计。这项工作中研究的配置挑战的另一个角度是,我们今天可能有太多的参数。有人可能会争辩说,减少参数以避免漏洞或混淆可能更好,而不是为更多功能添加新的配置。此外,有人可能会建议(在理论上)我们可以在文件系统本身中实现所有实用程序功能,以避免复杂的跨组件配置依赖。从本质上讲,这些都是文件系统和配置设计之间的权衡,值得社区进行更多研究。我们希望通过对实际配置问题的研究和ConfD原型的发布,我们的工作可以帮助识别有问题的配置参数,并进一步帮助减少这些参数,从而从总体上改进配置设计。 七、总结我们对 78 个实际配置问题进行了研究,并构建了一个名为 CONFD 的可扩展框架来解决各种配置问题。我们在 Ext4 和 XFS 上的实验表明,CONFD 可以通过利用配置依赖关系来帮助有效地解决配置问题。将来,我们希望进一步改进 CONFD 并研究第 6 节中讨论的其他系统。我们希望 CONFD 能够促进后续研究,以解决一般配置日益增加的挑战。 |
【本文地址】
今日新闻 |
推荐新闻 |