【2023.06.30】记录陪学数学建模 |
您所在的位置:网站首页 › win10安全中心重置 › 【2023.06.30】记录陪学数学建模 |
【2023.06.30】记录陪学数学建模
|
目录
写在前面正文开始范数l~p~范数l~0~范数l~1~范数l~2~范数
三阶行列式的计算方法
写在前面
六月底这天突然发现自己闲出屁来了,于是想到之前答应某人要陪她学习,于是开始了陪学数学建模系列。今天我们开始第一讲,python语言介绍、环境安装和线性代数知识的补充与线性规划的引入。 正文开始在很多机器学习的著作当中经常可见范数这个词,今天就来记录一下各种范数。 范数 lp范数一般将任意向量x的lp范数定义为: ∣ ∣ x ∣ ∣ p = ∑ i ∣ x i ∣ p p ||x||_p=\sqrt[p]{\sum_{i} |x_i|^p} ∣∣x∣∣p=pi∑∣xi∣p l0范数∣ ∣ x ∣ ∣ 0 = ∑ i ∣ x i ∣ 0 0 ||x||_0=\sqrt[0]{\sum_{i} |x_i|^0} ∣∣x∣∣0=0i∑∣xi∣0 表示向量 x \bm{x} x中非0元素的个数,等同于 ∣ ∣ x ∣ ∣ 0 = ∑ ( 1 ∣ x i ≠ 0 ) ||x||_0=\sum(1|x_i\neq0) ∣∣x∣∣0=∑(1∣xi=0)。 在诸多机器学习的模型中,比如压缩感知,我们很多时候希望最小化向量的l0范数。一个标准的l0范数优化问题往往可以写成如下形式: m i n ∣ ∣ x ∣ ∣ 0 s . t . A x = b min||x||_0\\ s.t.A\bm{x}=\bm{b} min∣∣x∣∣0s.t.Ax=b 然而,由于l0范数仅仅表示向量中非0元素的个数,因此这个优化模型在数学上被认为是一个NP-hard问题,即直接求解它很复杂,也不可能找到解。需要注意的是,正是由于该优化问题难以求解,因此压缩感知模型是将l0范数最小化问题转换成l1范数最小化问题。 l1范数∣ ∣ x ∣ ∣ 1 = ∑ i ∣ x i ∣ 1 1 ||x||_1=\sqrt[1]{\sum_{i} |x_i|^1} ∣∣x∣∣1=1i∑∣xi∣1 等于向量中所有元素绝对值之和。 相应的,一个l1范数优化问题为 m i n ∣ ∣ x ∣ ∣ 1 s . t . A x = b min||x||_1\\ s.t.A\bm{x}=\bm{b} min∣∣x∣∣1s.t.Ax=b 这个问题相比于l0范数优化问题更容易求解,可以借助现有的凸优化算法(线性规划或者是非线性规划),就能够找到我们想要的可行解。鉴于此,依赖于l1范数优化问题的机器学习模型如压缩感知就能够进行求解。 l2范数l2范数同理如下: ∣ ∣ x ∣ ∣ 1 = ∑ i ∣ x i ∣ 1 1 ||x||_1=\sqrt[1]{\sum_{i} |x_i|^1} ∣∣x∣∣1=1i∑∣xi∣1 优化问题: m i n ∣ ∣ x ∣ ∣ 2 s . t . A x = b min||x||_2\\ s.t.A\bm{x}=\bm{b} min∣∣x∣∣2s.t.Ax=b 三阶行列式的计算方法
|
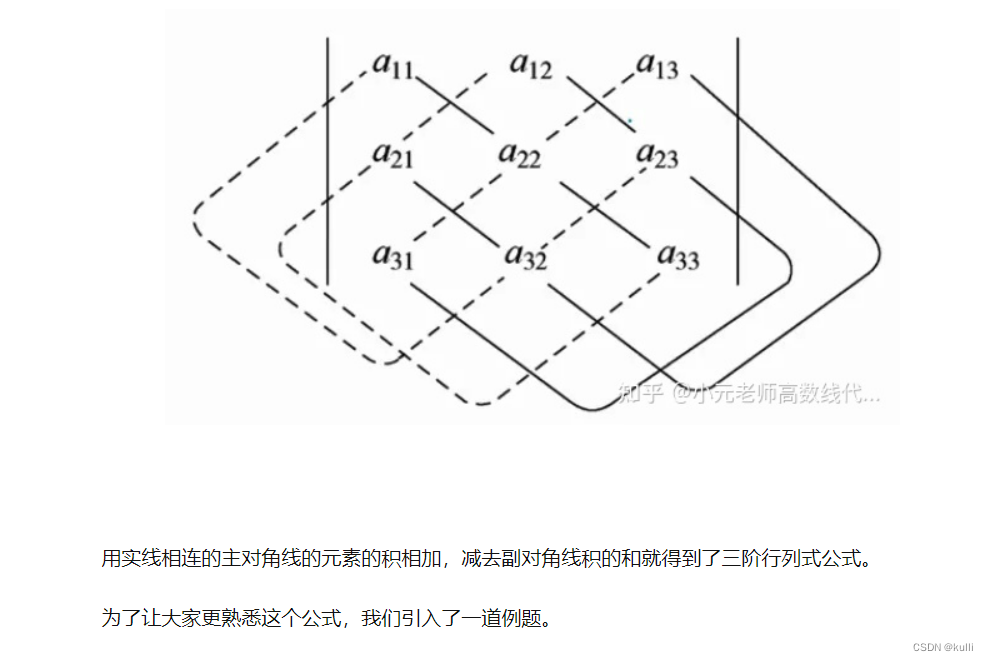 记住上面的图,实现相加,虚线相减!
记住上面的图,实现相加,虚线相减!【本文地址】
今日新闻 |
推荐新闻 |