【梯度惩罚Wasserstein:GAN:超分】 |
您所在的位置:网站首页 › wasserstein距离微分 › 【梯度惩罚Wasserstein:GAN:超分】 |
【梯度惩罚Wasserstein:GAN:超分】
|
Single image super-resolution using Wasserstein generative adversarial network with gradient penalty
(基于梯度惩罚Wasserstein生成对抗网络的单幅图像超分辨率) 生成式对抗网络(GAN)由于其强大的样本生成能力,已被用于解决单幅图像超分辨率(SISR)问题,获得高感知质量的超分辨率(SR)图像。然而,GAN存在训练不稳定,甚至不能收敛的缺点。本文基于Wasserstein GAN提出了一种新的SISR方法,它是一种具有Wasserstein度量的训练更稳定的GAN。为了进一步提高SR性能,使训练过程更加简单和稳定,对原始WGAN进行了两处修改。首先,采用梯度惩罚(GP)代替权值裁剪。其次,在WGAN的生成器中构造一个新的“预激活”权重层的残差块。在4个不同的测试数据集上进行的大量实验表明,该方法在4倍放大倍数下的准确率和感知质量均上级原始的基于GAN的SR方法和许多其他方法。 介绍单幅图像超分辨率(SISR)是计算机视觉领域的一个研究热点,其目的是通过恢复丢失的高频细节,从一幅低分辨率(LR)图像恢复出一幅高分辨率(HR)图像。SISR在监控安防、智能手机、人脸识别、遥感图像、医学诊断成像等主流视觉应用中得到了广泛的应用。尽管如此,图像超分辨率仍然是一个难题,因为从数学的角度来看,它是一个欠定的反问题,而且解通常不是唯一的。因此,为了稳定逆问题并获得合理的SR图像,需要在SR过程中加入一些图像先验或合理的假设。 在过去的几年里,研究者们为解决SISR问题付出了巨大的努力,提出了许多解决方法。这些方法可以大致分为两类,基于插值的方法和基于学习的方法。基于插值的方法,包括最近邻插值、双线性插值、双三次插值和三次样条插值,试图在HR网格中生成未知像素。基于插值的方法具有高效、低计算复杂度的特点。由于其低通滤波特性,基于插值的方法通常产生具有锯齿状伪影和振铃的过平滑HR图像。基于学习的方法学习LR图像到HR图像的映射,然后根据预先建立的映射从测试LR图像推断SR图像。实验证明,该算法能够在一定程度上恢复丢失的图像细节,生成更有吸引力的SR图像。在Freeman等人的开创性工作之后,各种基于学习的方法被提出,例如基于稀疏表示的方法、基于支持向量回归的方法、锚定邻域回归方法、基于层次决策树的方法。为了追求更好的性能,许多研究人员通常在这些方法中采用后处理技巧来进一步减小重建误差,如迭代反投影、双边反投影和约束反投影。近年来,基于卷积神经网络(CNN)的深度学习方法在图像识别、分类、去噪等计算机视觉任务中取得了巨大成功。受SRCNN成功的鼓舞,提出了从FSRCNN、ESPCN、VDSR、DRCN、LapSRN、SRDenseNet到RCAN的变体。这些网络主要在网络深度和结构上有所不同。与传统的基于学习的随机共振方法相比,这些方法无疑取得了更好的性能。这些方法的共同之处在于它们都更加注重提高重建后的HR图像的峰值信噪比(PSNR)。然而,具有高PSNR的重构SR图像不一定产生良好的视觉感知。越来越多的研究者认识到,随机共振方法在提高客观评价指标如峰值信噪比(PSNR)的同时,还应改善重建图像的视觉质量。这一问题也成为感知图像恢复与处理(PIRM)的子挑战。 GAN是另一种高效的深度学习模型,具有很强的样本生成能力。Ledig等人首先提出使用带有感知损失函数的GAN来解决真实感SISR问题,并取得了令人满意的结果。研究人员已经提出了从ESRGAN、ESRGAN+ 、RFBESRGAN、周期中周期GAN(CinCGAN)、SinGAN、RankSRGAN、KernelGAN、RCA-GAN到AMSRGAN的各种基于GAN的变体,这些变体已经取得了更好的结果。尽管遗传算法网络在解决感知图像随机共振方面有着巨大的潜力,但它仍然面临着一个明显的困难,即训练的不稳定性。为了解决这个问题,Arjovsky等人对GAN的训练过程进行了深入的研究,发现如果鉴别器变得更好,则生成器的梯度将消失。这种现象背后的原因是原始GAN所采用的KullbackLeibler(KL)或Jensen-Shannon(JS)散度不能在两个数据分布的支持度没有交集的情况下给予两个数据分布之间的有效度量。为了弥补这一缺陷,采用Wasserstein距离代替散度作为度量,证明了WassersteinGAN的训练比原来的更稳定。然而,它并不是最理想的,它采用了权值裁剪来加强Lipschitz约束,这可能导致产生较差的样本,甚至不能收敛。 受此启发,提出了一种基于WGAN的视觉质量较好的SISR方法。在我们提出的方法中,为了进一步提高SR性能,做了两个改进。一种是用梯度惩罚代替WGAN中的权值裁剪,以提高训练的稳定性。二是在发生器中采用一种新的“预激活”剩余块,以提高其性能。我们叫它SRWGAN-PA-GP。 方法 SRGANGAN为生成具有高感知质量的真实自然图像提供了强大的能力,SRGAN的基本思想如图1所示。 如前所述,原始GAN难以训练,训练不稳定的现象时有发生。为了解决GAN应用于图像SR时的这一问题,对SRGAN进行了两个改进。改进之处一是对生成器网络G和鉴别器网络D设计了新的网络结构,二是采用了新的损耗函数。 Network structure
研究表明,GAN训练困难或不稳定的主要原因是损失函数选择不当。为了缓解这个问题,提出了WGAN。当两个数据分布的支撑不相交时,该方法有效地测量了真实的距离。使用Kantorovich-Rubinstein对偶性获得原始WGAN值函数: |
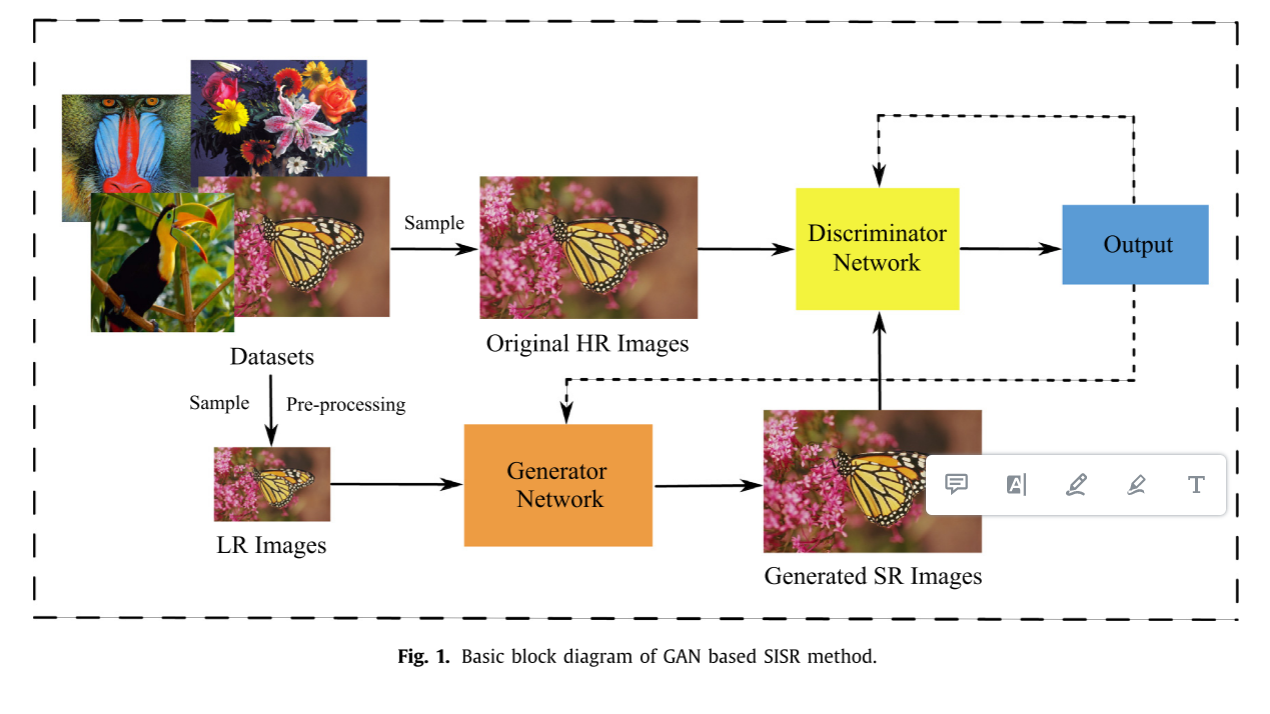 在SRGAN中,利用修正值函数来适应SR任务。价值函数如下所示:
在SRGAN中,利用修正值函数来适应SR任务。价值函数如下所示: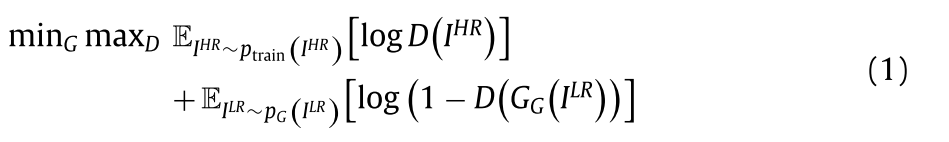 其中,
I
H
R
I^{HR}
IHR代表HR图像,
I
L
R
I^{LR}
ILR代表LR图像,ptrain和pG代表真实的数据分布和生成数据分布。G是一个可微函数,由带参数的多层感知器表示,D表示x来自真实的数据集而不是生成器的概率,它输出单个标量。D和G被训练以分别最小化和最大化目标函数。生成元G隐含地定义了概率分布pG为当z ∝ pz时得到的样本G(z)的分布。最后,当pG = ptrain时,D和G将达到一个纳什(Nash)均衡,它们不能进一步改进。鉴别器网络不能区分这两个分布,这意味着D(x)= 1 / 2。 大多数情况下,峰值信噪比的大小与人的主观视觉效果不一致。为了强调视觉质量,SRGAN采用以下感知损失(包含内容损失和对抗损失)
l
S
R
l^{SR}
lSR作为总损失函数,
其中,
I
H
R
I^{HR}
IHR代表HR图像,
I
L
R
I^{LR}
ILR代表LR图像,ptrain和pG代表真实的数据分布和生成数据分布。G是一个可微函数,由带参数的多层感知器表示,D表示x来自真实的数据集而不是生成器的概率,它输出单个标量。D和G被训练以分别最小化和最大化目标函数。生成元G隐含地定义了概率分布pG为当z ∝ pz时得到的样本G(z)的分布。最后,当pG = ptrain时,D和G将达到一个纳什(Nash)均衡,它们不能进一步改进。鉴别器网络不能区分这两个分布,这意味着D(x)= 1 / 2。 大多数情况下,峰值信噪比的大小与人的主观视觉效果不一致。为了强调视觉质量,SRGAN采用以下感知损失(包含内容损失和对抗损失)
l
S
R
l^{SR}
lSR作为总损失函数, 在
l
S
R
l^{SR}
lSR中,内容损失包括两个部分,逐像素均方误差(MSE)损失和VGG损失,传统的超分辨率任务通常将逐像素MSE作为其损失函数,计算如下:
在
l
S
R
l^{SR}
lSR中,内容损失包括两个部分,逐像素均方误差(MSE)损失和VGG损失,传统的超分辨率任务通常将逐像素MSE作为其损失函数,计算如下: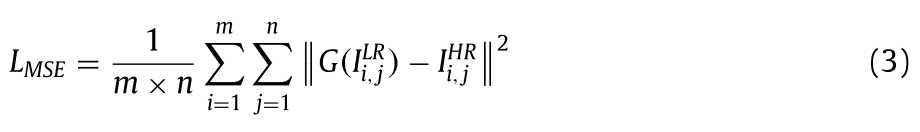 其中,m和n分别表示两个对比图像的高度和宽度;i和j表示图像中的每个像素值。虽然最小化MSE损失有助于提高重建图像和目标图像之间的峰值信噪比,但它常常模糊图像的细节并且缺乏高频内容。因此,VGG损失同时被用作新的发电机损失函数。VGG损失通过计算欧几里得距离来度量重构图像和原始图像之间的特征表示的差异,欧几里得距离被描述为:
其中,m和n分别表示两个对比图像的高度和宽度;i和j表示图像中的每个像素值。虽然最小化MSE损失有助于提高重建图像和目标图像之间的峰值信噪比,但它常常模糊图像的细节并且缺乏高频内容。因此,VGG损失同时被用作新的发电机损失函数。VGG损失通过计算欧几里得距离来度量重构图像和原始图像之间的特征表示的差异,欧几里得距离被描述为: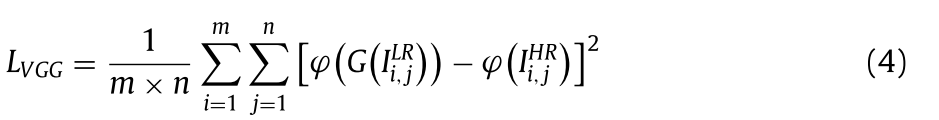 其中φ描述了激活函数后的特征图,m和n表示相应特征图的维数。最后,对抗性损失描述为:
其中φ描述了激活函数后的特征图,m和n表示相应特征图的维数。最后,对抗性损失描述为: 它可以通过试图欺骗鉴别器网络来促使网络偏爱存在于自然图像流形上的解。
它可以通过试图欺骗鉴别器网络来促使网络偏爱存在于自然图像流形上的解。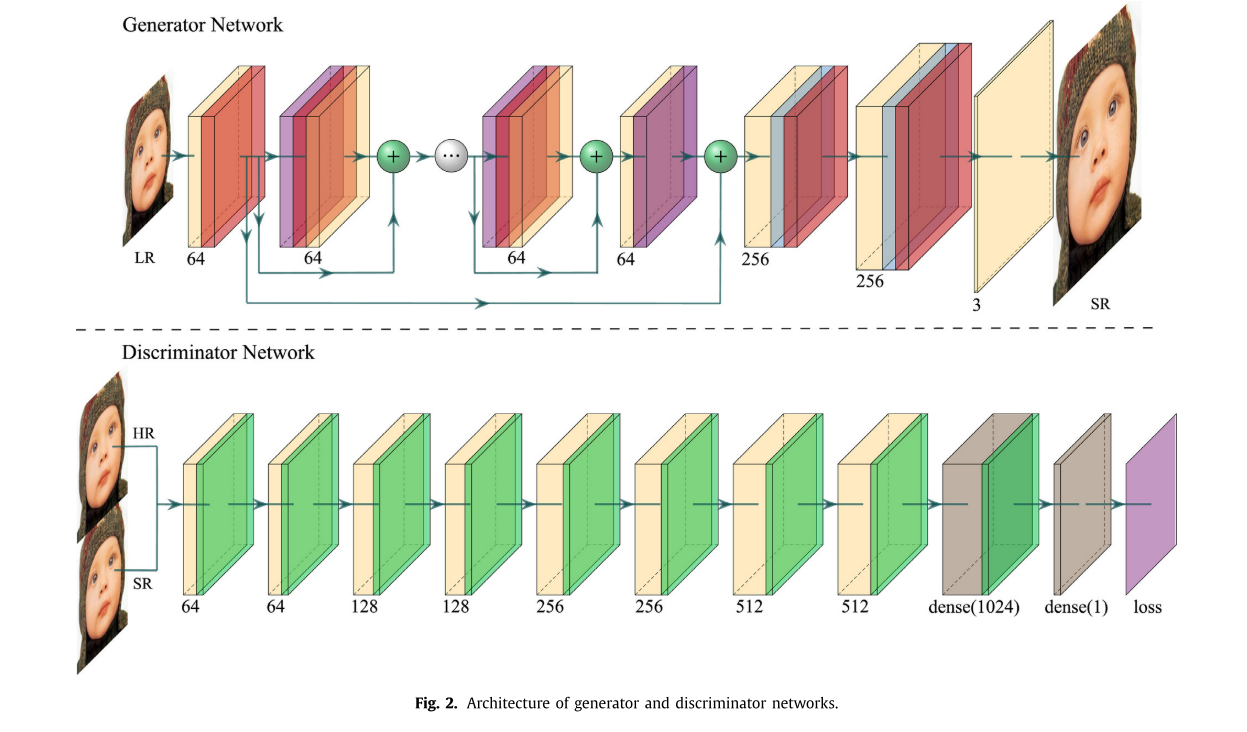 新设计的生成器网络G和鉴别器网络D的结构如图2所示。G的核心是16个残差网络,在每个残差单元中,我们采用图3所示的全预激活结构,其中Xi和X~i +1代表残差网络的输入和输出,其中我们将batchnormal层和ParameterReLU层放在卷积层之前。这表明特征映射F(Xi~)= Xi,得到了最快的误差下降和最小的训练损失,使得优化比原始的ResNet容易,相反,在捷径连接中加入的1 × 1卷积和丢包运算会阻碍信息的传递,从而给优化带来困难。
新设计的生成器网络G和鉴别器网络D的结构如图2所示。G的核心是16个残差网络,在每个残差单元中,我们采用图3所示的全预激活结构,其中Xi和X~i +1代表残差网络的输入和输出,其中我们将batchnormal层和ParameterReLU层放在卷积层之前。这表明特征映射F(Xi~)= Xi,得到了最快的误差下降和最小的训练损失,使得优化比原始的ResNet容易,相反,在捷径连接中加入的1 × 1卷积和丢包运算会阻碍信息的传递,从而给优化带来困难。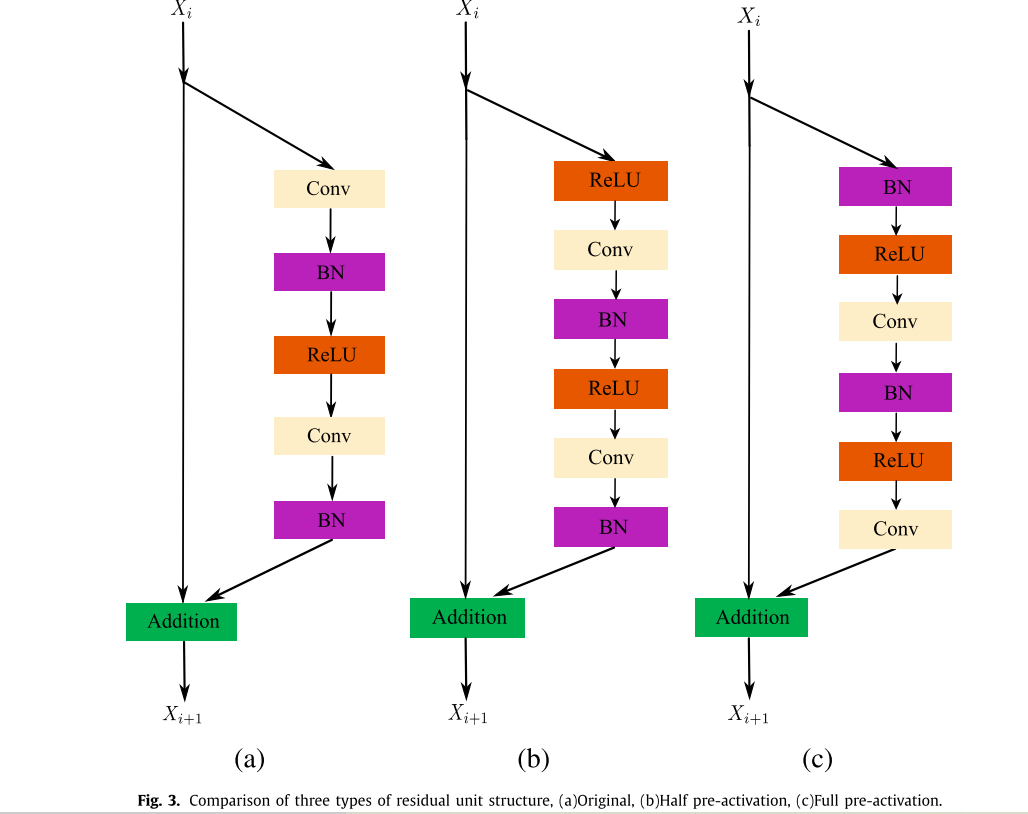 在预激活结构中引入批量正态,与传统的后激活和半预激活结构相比,可以改善模型的正则化程度,提高泛化能力。ParameterReLU用作所有激活函数。同时,将生成器的第一层和最后一层卷积核的大小设置为9 × 9,以进一步提高性能。跳跃连接[13]的使用不仅可以传递本层的特征信息,还可以传递前几层的特征信息,从而可以利用更多的特征实现局部和全局的特征融合,合理数量的跳跃连接结构可以缓解梯度消失问题,改善特征传播,从而提高图像超分辨率重建效果。在最后两层,我们采用两个因子均为2的亚像素卷积层来上采样其分辨率和下采样嵌入维数,从而减轻计算负担。在图2中,黄色和红色块是卷积层和ParameterReLU层,紫色和蓝色块是批处理正常层和子像素卷积层,绿色圆圈中嵌入的加号表示逐元素相加。正如残差网络的设计初衷一样,跳过连接可以解决在网络层较深的情况下梯度消失的问题,同时有助于反向传播,加快训练过程。白色圆圈中的省略号包括另外省略的14个残留块。 鉴别器网络结构是基于VGG 19网络设计的,我们删除了所有的pooling层和batchnormal层,删除了最后一个sigmoid激活函数,采用LeakyReLU作为我们的激活函数。使用RMSprop优化器,在鉴别器网络中引入带梯度惩罚的Wasserstein距离,以最小化Wasserstein-GP损失为优化目标,将二元分类问题转化为回归问题。在图2中,绿色方块和灰色方块分别代表LeakyReLU层和全连接层,其他图示与生成器相同。
在预激活结构中引入批量正态,与传统的后激活和半预激活结构相比,可以改善模型的正则化程度,提高泛化能力。ParameterReLU用作所有激活函数。同时,将生成器的第一层和最后一层卷积核的大小设置为9 × 9,以进一步提高性能。跳跃连接[13]的使用不仅可以传递本层的特征信息,还可以传递前几层的特征信息,从而可以利用更多的特征实现局部和全局的特征融合,合理数量的跳跃连接结构可以缓解梯度消失问题,改善特征传播,从而提高图像超分辨率重建效果。在最后两层,我们采用两个因子均为2的亚像素卷积层来上采样其分辨率和下采样嵌入维数,从而减轻计算负担。在图2中,黄色和红色块是卷积层和ParameterReLU层,紫色和蓝色块是批处理正常层和子像素卷积层,绿色圆圈中嵌入的加号表示逐元素相加。正如残差网络的设计初衷一样,跳过连接可以解决在网络层较深的情况下梯度消失的问题,同时有助于反向传播,加快训练过程。白色圆圈中的省略号包括另外省略的14个残留块。 鉴别器网络结构是基于VGG 19网络设计的,我们删除了所有的pooling层和batchnormal层,删除了最后一个sigmoid激活函数,采用LeakyReLU作为我们的激活函数。使用RMSprop优化器,在鉴别器网络中引入带梯度惩罚的Wasserstein距离,以最小化Wasserstein-GP损失为优化目标,将二元分类问题转化为回归问题。在图2中,绿色方块和灰色方块分别代表LeakyReLU层和全连接层,其他图示与生成器相同。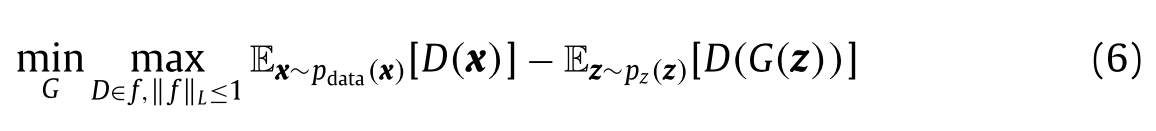 其中f是1-Lipschitz函数,它约束所用连续函数的导数处处小于1。直观的解释是,当输入样本稍有变化时,鉴别器给出的分数不可能变化太剧烈。最初的限制通常是通过重量剪裁实现的:一旦鉴别器的参数被更新,则检查参数的绝对值是否超过阈值c,然后将这些参数限幅回[-c,c]的范围。鉴别器希望尽可能地鉴别真实的样本的差异,但权值裁剪独立地限制了每个网络参数的取值范围。可以将权重推向剪切范围的两个极值,对于每个值,梯度随着在网络中移动得更远而指数地增长或衰减。因此,它仍然存在由于梯度范数的爆炸或消失而导致模型崩溃的问题。 因此,本文将WGAN-GP中描述的一种更稳定的梯度惩罚方法引入鉴别器网络中,代替加权裁剪的Wasserstein距离,为强制Lipschitz函数的约束提供了一种替代方法。我们考虑约束输出相对于其输入图像的梯度范数,并修改WGAN的损失函数。当梯度值被约束在1附近时,将获得更好的效果。我们根据两个数据分布x^和z之间的线性插值定义x,它满足以下方程:
其中f是1-Lipschitz函数,它约束所用连续函数的导数处处小于1。直观的解释是,当输入样本稍有变化时,鉴别器给出的分数不可能变化太剧烈。最初的限制通常是通过重量剪裁实现的:一旦鉴别器的参数被更新,则检查参数的绝对值是否超过阈值c,然后将这些参数限幅回[-c,c]的范围。鉴别器希望尽可能地鉴别真实的样本的差异,但权值裁剪独立地限制了每个网络参数的取值范围。可以将权重推向剪切范围的两个极值,对于每个值,梯度随着在网络中移动得更远而指数地增长或衰减。因此,它仍然存在由于梯度范数的爆炸或消失而导致模型崩溃的问题。 因此,本文将WGAN-GP中描述的一种更稳定的梯度惩罚方法引入鉴别器网络中,代替加权裁剪的Wasserstein距离,为强制Lipschitz函数的约束提供了一种替代方法。我们考虑约束输出相对于其输入图像的梯度范数,并修改WGAN的损失函数。当梯度值被约束在1附近时,将获得更好的效果。我们根据两个数据分布x^和z之间的线性插值定义x,它满足以下方程:  因此,我们删除了公式(1)中的对数函数,并得到新的对抗损失函数,如下图所示:
因此,我们删除了公式(1)中的对数函数,并得到新的对抗损失函数,如下图所示: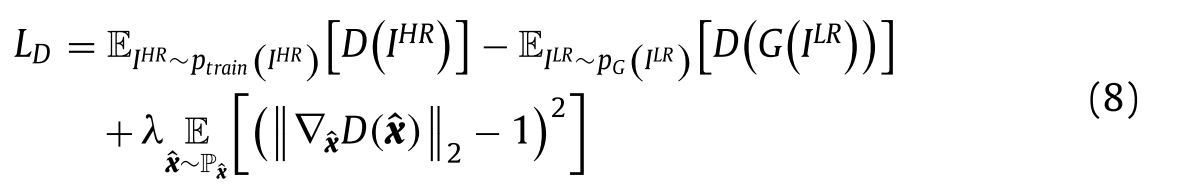 其中前两项是原始评论损失,最后一项是梯度惩罚。▽是微分算子,λ是梯度罚系数。这种约束使得实验更加充分,得到了更好的结果。 SRGAN中提出的内容损失保留为我们的总体的生成器损失函数,结合了MSE损失和VGG损失,如下图所示:
其中前两项是原始评论损失,最后一项是梯度惩罚。▽是微分算子,λ是梯度罚系数。这种约束使得实验更加充分,得到了更好的结果。 SRGAN中提出的内容损失保留为我们的总体的生成器损失函数,结合了MSE损失和VGG损失,如下图所示: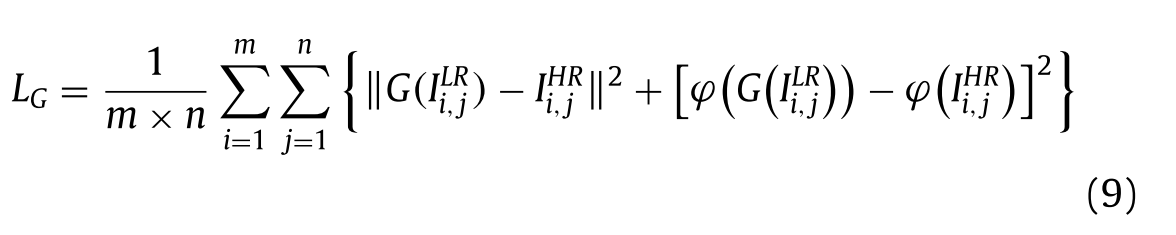 如上所述,我们联合收割机公式中的新损失函数公式(8)-(9),因此我们提出的方法的最终目标函数将被获得作为等式(10):
如上所述,我们联合收割机公式中的新损失函数公式(8)-(9),因此我们提出的方法的最终目标函数将被获得作为等式(10):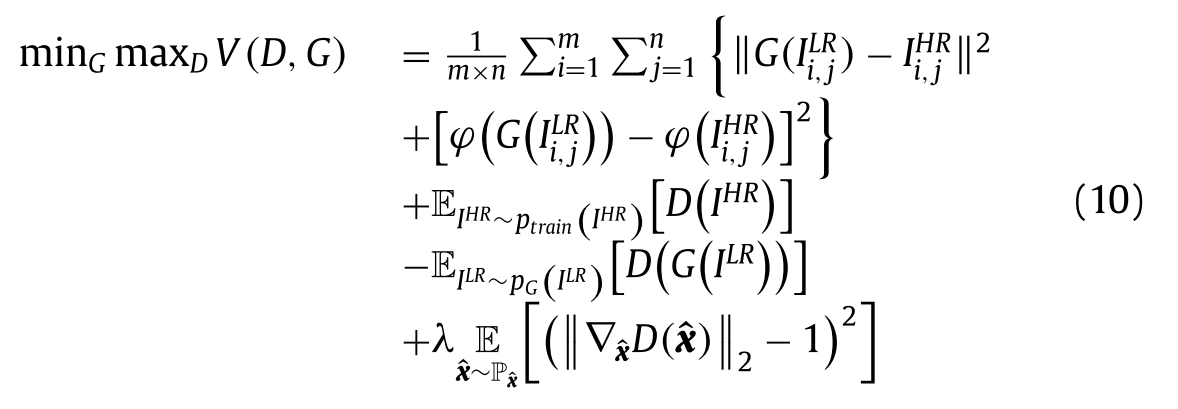 算法的总体过程和具体步骤如算法1所示:
算法的总体过程和具体步骤如算法1所示:
【本文地址】