模型中各变量对模型的解释程度 |
您所在的位置:网站首页 › vip占比怎么算 › 模型中各变量对模型的解释程度 |
模型中各变量对模型的解释程度
|
在建立一个模型后,我们会关心这个模型对于因变量的解释程度,甚至想知道各个自变量分别对模型的贡献有多少。对于非线性模型,如 Random Forest 和 XGBoost 等由于其建模过程就是筛选变量的过程,可以计算变量的重要性;但对于大多数非线性模型,是比较难确定各个变量的贡献程度,本文仅讨论广义线性模型中的变量贡献程度。因此本文分为两种情况来看:普通线性模型与广义线性模型。 普通线性回归模型 将因变量的变异进行分解(如ANOVA),可求得 其中,SS是 Sums of Squares 的缩写,SSR 表示来自Regression 的变异,SSE 表示随机变异(未能解释的变异),SSTO 表示总变异,SSTO=SSR+SSE。则 由于随着变量增加,
关于各个变量的贡献程度,Yi-Chun E. Chao 等人写了篇paper总结,详细内容见文末参考文献。 各个变量相对重要性的评价,令 (1)对于所有的 (2)所有的 (3) 下面探讨几个可能可以度量 单变量 r2 各个变量自己单独建立回归模型(或作相关分析),可以求得各个变量的 但是仅当各个变量完全不相关时,这个式子才成立: Type III SS 与 Type I SS 这部分详细内容建议参考:Sequential (or Extra) Sums of Squares Type III SS 在软件里一般显示为Adjust SS,指的是,将p个变量纳入回归模型后,各个变量的额外贡献度(独立贡献度),一般来说,各个变量的SS之和是小于SSR的,仅当各个变量完全不相关时,各个变量的SS的和才等于SSR。相应地,可以求出Type III Type I SS 在软件里一般显示为Sequential SS,指的是,在之前p-1个变量的基础上,再加入当前变量,SSR的增加量。因此各个变量的SS之和是等于SSR的。但是这个SS依赖于进入模型的顺序(先进入模型的占便宜)。相应地,有Type III 偏 这部分详细内容请参考:Partial R-squared 偏 比如:在含有x1的模型的基础上,新增变量 x2 和 x3,则 这个概念一般用于检验新加入的变量有没有价值。 Pratt’s Index 这个指标首先由Pratt 等人提出。Pratt 指数是一个乘积:
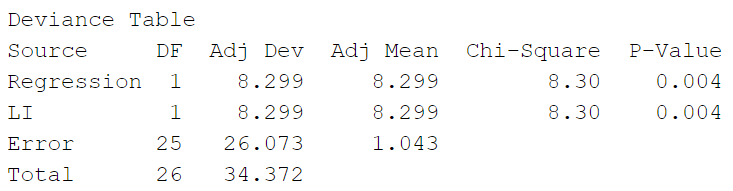
但是存在一个问题就是,有时候Pratt指数可能是负数值。对于这个问题,笔者不知是否可以修改成 Dj 其他方法包括:General Dominance Index VIP值 PLSR(偏最小二乘法回归)本质上也是线性模型,综合求解过程中的参数(映射变换的系数和映射维度本身对因变量的解释程度),可以求得VIP值(Variable Importance in Projection),变量的 VIP 值反映的也是该变量对模型的解释程度。VIP值可用于变量的筛选。 对应的PLS-DA(偏最小二乘判别分析)属于广义线性模型,原理和PLSR基本一致,只是将回归任务变成了分类任务,也有VIP值。 广义线性模型 这里的非线性模型主要包括 Logistic 回归 和 Cox 回归。 由于 Logistic 回归中, 其中, 这种 伪 似然比检验 Logistic回归中,似然比检验(Likelihood Ratio Test),又叫 Deviance Test,用于评估模型中某些参数是否应该为0,或者说,新模型(复杂模型,full model)比原模型(简单模型,reduced model)中新增的参数是否为真实有效的约束。具体讲解可以参考:似然比检验 LRT 统计量为: 该统计量服从卡方分布。其中, 定义deviance为 log likelihood 的负2倍。该统计量也常常记为: 此处引用 Logistic Regression 中的一个例子: 以自变量LI进行拟合得到模型,并与无自变量的模型(null model)进行对比(似然比检验),得到结果如下: 可以算出无自变量的模型的log likelihood为 当前模型的 log likelihood 为
|
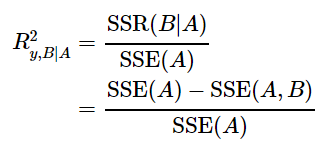

【本文地址】