【生成模型】变分自编码器(VAE)及图变分自编码器(VGAE) |
您所在的位置:网站首页 › vae生成模型怎么用 › 【生成模型】变分自编码器(VAE)及图变分自编码器(VGAE) |
【生成模型】变分自编码器(VAE)及图变分自编码器(VGAE)
|
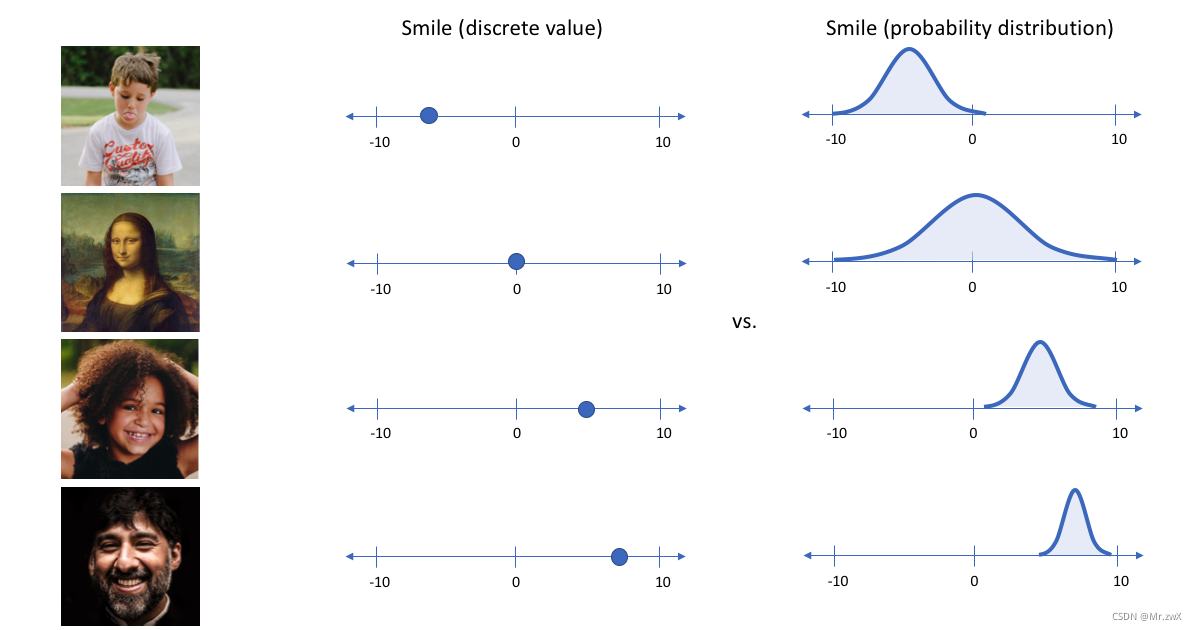
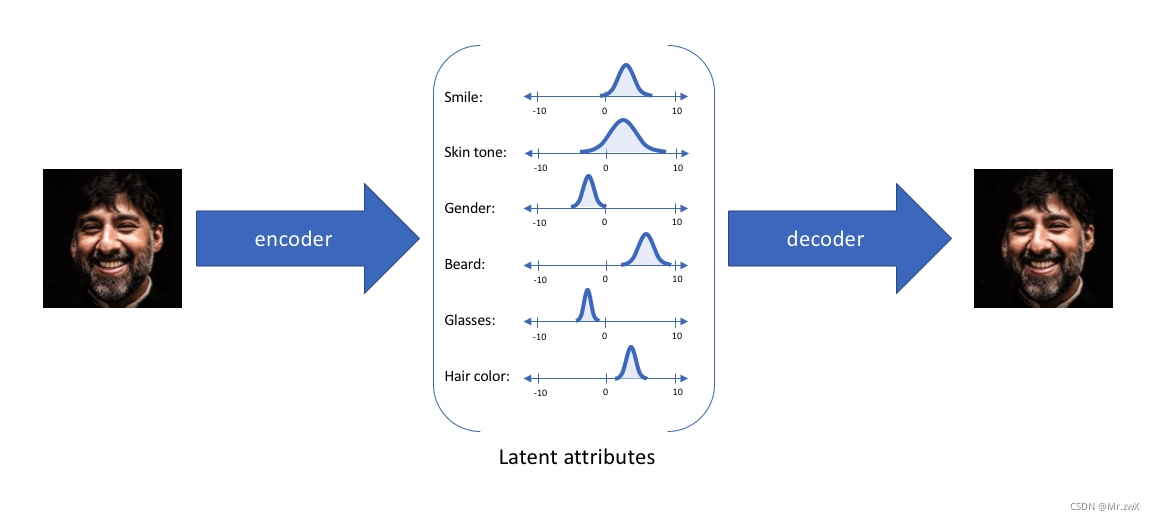
这段时间在学习机器学习中有关不确定性和概率分布的知识,发现了VAE这样一个有趣的方向,想抓紧时间整理一下VAE的主要思想和方法,然后思考如何迁移应用到自己的研究方向上。 变分自编码器(Variational Auto-Encoders,VAE)是深度生成模型的一种形式(GAN也是其中一种),VAE是基于变分贝叶斯推断的生成式网络结构。传统自编码器是通过数值方式描述潜在空间的不同,而VAE以概率的方式描述潜在空间的不同,是一种无监督式学习的生成模型。 举个简单的例子说明变分自编码模型,输入一张照片,想描述其中人物的笑容,如果用笑/没笑这样的二分类/某个单值表示则显得不是很适合(注:单值表示则是自编码器模型的特点)。更好的表述应该是用一个区间范围来表示笑的概率大小,如下图即是通过VAE的编码(encoder)得到图片中笑的概率分布情况。 通过VAE,可以将每一个特征表示为概率分布。那么如何通过这个概率分布来生成新的数据呢?这个过程叫做解码(decoder),从每个潜在状态分布中随机采样,生成一个向量,作为解码器模型的输入,从而得到新生成的结果。如下图所示,一张图片中的人物几大特征(smile skin gender beard…)通过encoder编码后生成不同特征的概率分布,这样能使decoder重新构建我们的输入。 现在学习VAE的模型结构是什么样的。如下图所示,模型分为两个部分:推断网络(编码器encoder)和生成网络(decoder)。 推断网络:用于原始输入数据的变分推断,生成隐变量的变分概率分布情况;生成网络:根据生成的隐变量变分概率分布还原为原始数据近似概率分布。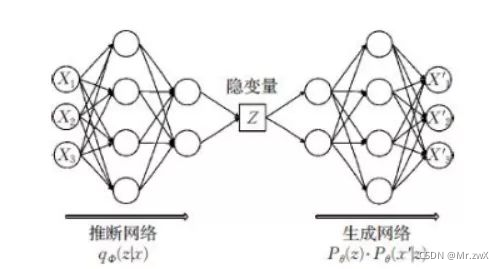 
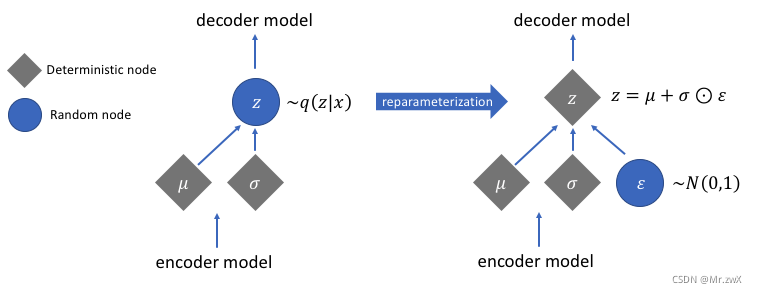
在VAE中,假设 p ( Z ∣ X ) p(Z|X) p(Z∣X)(后验分布)是满足正态分布的。给定一个真实样本 K k K_k Kk,假设存在一个专属于 X k X_k Xk的分布 p ( Z ∣ X k ) p(Z|X_k) p(Z∣Xk),进一步假设这个分布是正态分布(独立的、多元的)。由于这个专属性,有多少个样本X就有多少个正态分布,能更好让decoder做还原。 变分自编码器和自编码器有什么根本上的区别呢?变分自编码器的encoder和decoder的输出都是受参数约束变量的概率密度分布,而自编码器是某种特定数值的编码。 想根据观察到的x,推断出潜在空间的分布:
p
(
z
∣
x
)
=
p
(
x
∣
z
)
p
(
z
)
p
(
x
)
p(z|x)=\frac{p(x|z)p(z)}{p(x)}
p(z∣x)=p(x)p(x∣z)p(z) 计算
p
(
x
)
p(x)
p(x)是很复杂的,
p
(
x
)
=
∫
p
(
x
∣
z
)
p
(
z
)
d
z
p(x)=\int{p(x|z)p(z)}dz
p(x)=∫p(x∣z)p(z)dz 通常是个复杂的分布,我们可以用变分推断来估计这个值。 我们用另一个分布
q
(
z
∣
x
)
q(z|x)
q(z∣x)近似估计
p
(
z
∣
x
)
p(z|x)
p(z∣x),将
q
(
z
∣
x
)
q(z|x)
q(z∣x)定义为具有可伸缩性的分布。 KL散度 KL散度是两个概率分布的差值,要想保证 q ( z ∣ x ) q(z|x) q(z∣x)与 p ( z ∣ x ) p(z|x) p(z∣x)尽可能相似,我们的目的即是最小化这个KL散度: m i n K L ( q ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) minKL(q(z|x)||p(z|x)) minKL(q(z∣x)∣∣p(z∣x)) 转换一下,通过最大化下式,即最小化了上式: E q ( z ∣ x ) l o g p ( z ∣ x ) − K L ( q ( z ∣ x ) ∣ ∣ p ( z ) ) E_{q(z|x)}logp(z|x)-KL(q(z|x)||p(z)) Eq(z∣x)logp(z∣x)−KL(q(z∣x)∣∣p(z)) 其中, E q ( z ∣ x ) l o g p ( z ∣ x ) E_{q(z|x)}logp(z|x) Eq(z∣x)logp(z∣x)表示重构的可能性, m i n K L ( q ( z ∣ x ) ∣ ∣ p ( z ∣ x ) ) minKL(q(z|x)||p(z|x)) minKL(q(z∣x)∣∣p(z∣x))表示要学习的分布 q ( z ∣ x ) q(z|x) q(z∣x)有多逼近真实的后验分布 p ( z ∣ x ) p(z|x) p(z∣x). 损失函数 损失函数包含两部分: L ( x , x ^ ) + K L ( q ( z ∣ x ) ∣ ∣ p ( z ) ) L(x,\hat{x})+KL(q(z|x)||p(z)) L(x,x^)+KL(q(z∣x)∣∣p(z)) 分布标准化处理 有博主把这一部分写得非常清楚,借鉴一部分过来供大家理解学习,出处附在参考资料中。 重参数技巧(reparameterization trick) 为什么要用重参数技巧?在decoder过程中,我们要从
p
(
z
∣
x
)
p(z|x)
p(z∣x)中采样一个
z
z
z出来,尽管采样的结果
p
(
z
∣
x
)
p(z|x)
p(z∣x)是一个分布(已知高斯分布的参数,故可求导训练),但是随机采样这个过程是不可求导训练的。 如何解决这个问题?用重参数技巧。从
N
(
μ
,
σ
2
)
N(\mu,\sigma^2)
N(μ,σ2)中采样一个
z
z
z出来,相当于从
N
(
0
,
I
)
N(0,I)
N(0,I)中采样一个
ϵ
\epsilon
ϵ出来,然后做参数的线性变换让
z
=
μ
+
ϵ
×
σ
.
z=\mu+\epsilon\times\sigma.
z=μ+ϵ×σ. 主要思想 将变分自编码器(VAE)迁移到图领域中(graph),将已知图通过图卷积层(GCN)编码(decoder),学习到节点向量表示的分布,在分布中采样得到节点的向量表示,然后解码(link prediction)重构图。 模型结构 解码器两两计算两点间存在边的概率来重构图: p ( A ∣ Z ) = ∑ i = 1 N ∑ i = 1 N p ( A i j ∣ z i , z j ) p(A|Z)=\sum_{i=1}^N\sum_{i=1}^Np(A_{ij}|z_i, z_j) p(A∣Z)=i=1∑Ni=1∑Np(Aij∣zi,zj) 故有, p ( A i j = 1 ∣ z i , z j ) = s i g m o i d ( z i T z j ) p(A_{ij}=1|z_i,z_j)=sigmoid(z_i^Tz_j) p(Aij=1∣zi,zj)=sigmoid(ziTzj)。 损失函数 损失函数包含两部分:生成图和原始图之间的距离度量、节点表示向量分布和正态分布的散度。 L = E q ( Z ∣ X , A ) [ l o g p ( A ∣ Z ) ] − K L [ q ( Z ∣ X , A ) ∣ ∣ P ( Z ) ] L=E_q(Z|X,A)[logp(A|Z)]-KL[q(Z|X,A)||P(Z)] L=Eq(Z∣X,A)[logp(A∣Z)]−KL[q(Z∣X,A)∣∣P(Z)] 其中, E q ( Z ∣ X , A ) [ l o g p ( A ∣ Z ) ] E_q(Z|X,A)[logp(A|Z)] Eq(Z∣X,A)[logp(A∣Z)]是交叉熵损失函数。 理解到VAE的思想后,理解VGAE就会稍轻松一些,VAE用在CV领域比较多,通过生成模型生成具有相似特征的图像,但是将VAE应用到graph领域,有什么价值呢?在前面的推导中,VGAE得到图节点编码后,两两计算节点间存在边的概率大小,基于此重构图。可以看到,VGAE其实有做链路预测(link prediction) 的作用,举个简单的例子:在推荐系统中,通过重构图来捕获user与item之间可能的connection。 补充:图自编码器(GAE)除了VGAE,还有GAE模型——图自编码器,GAE同样在VGAE这篇paper中提出了。 编码器仍然是两层GCN网络: Z = G C N ( X , A ) Z=GCN(X,A) Z=GCN(X,A) 解码器通过两两计算两点间存在边的概率来重构图: A ~ = s i g m o i d ( Z Z T ) \widetilde{A}=sigmoid(ZZ^T) A =sigmoid(ZZT) 损失函数衡量了生成图和原始图之间的差异值: L = E q ( Z ∣ X , A ) [ l o g p ( A ∣ Z ) ] L=E_{q(Z|X,A)}[logp(A|Z)] L=Eq(Z∣X,A)[logp(A∣Z)] 可以发现,GAE与VGAE相比少了变分,即少了概率表征这一特点,所以损失函数中不需要再加入KL散度。 参考资料 变分自编码器是什么?PAPER:《Auto-Encoding Variational Bayes》从自编码器到变分自编码器(其二)变分自编码器(一):原来是这么一回事VGAE(Variational graph auto-encoders)论文详解 |

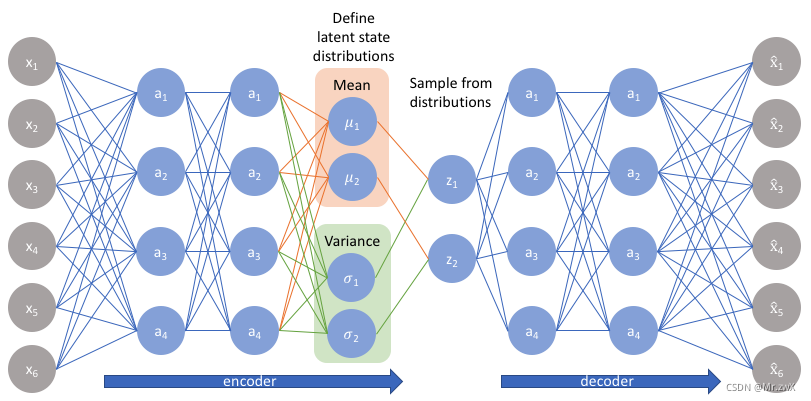
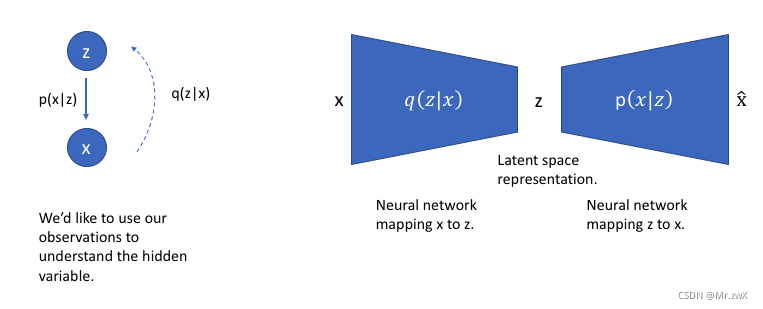 使用
q
q
q来推断可能隐藏的变量(潜在状态),这些变量可以用于生成观察值。我们可以进一步将这个模型构造成神经网络结构,其中编码器模型(encoder)学习从
x
x
x到
z
z
z的映射,解码器模型(decoder)学习从
z
z
z到
x
x
x的映射。
使用
q
q
q来推断可能隐藏的变量(潜在状态),这些变量可以用于生成观察值。我们可以进一步将这个模型构造成神经网络结构,其中编码器模型(encoder)学习从
x
x
x到
z
z
z的映射,解码器模型(decoder)学习从
z
z
z到
x
x
x的映射。
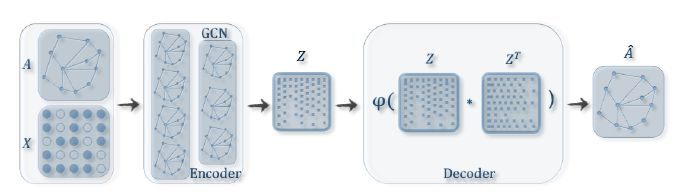 输入:邻接矩阵A和特征矩阵X 过程:通过编码器(图卷积网络)学习节点低维向量表示的均值
μ
\mu
μ和方差
σ
\sigma
σ,然后用解码器(链路预测)生成图。 编码器是简单的两层GCN网络:
q
(
Z
∣
X
,
A
)
=
∑
i
=
1
N
q
(
z
i
∣
X
,
A
)
q(Z|X,A)=\sum_{i=1}^N q(z_i|X,A)
q(Z∣X,A)=i=1∑Nq(zi∣X,A) 其中,
q
(
z
i
∣
X
,
A
)
=
N
(
z
i
∣
μ
i
,
d
i
a
g
(
σ
2
)
)
q(z_i|X,A)=N(z_i|\mu_i,diag(\sigma^2))
q(zi∣X,A)=N(zi∣μi,diag(σ2)),
μ
\mu
μ是节点向量表示
μ
=
G
C
N
μ
(
X
,
A
)
\mu = GCN_{\mu}(X,A)
μ=GCNμ(X,A)的均值,
σ
\sigma
σ是节点向量表示的方差
l
o
g
σ
=
G
C
N
σ
(
X
,
A
)
log\sigma=GCN_\sigma(X,A)
logσ=GCNσ(X,A)。 两层卷积网络定义如下:
G
C
N
(
X
,
A
)
=
A
~
R
e
L
U
(
A
~
X
W
0
)
W
1
GCN(X,A)=\widetilde{A} ReLU(\widetilde{A}XW_0)W_1
GCN(X,A)=A
ReLU(A
XW0)W1 其中,
A
~
=
D
^
−
1
2
A
^
D
^
−
1
2
\widetilde{A}=\widehat{D}^{-\frac{1}{2}}\widehat{A}\widehat{D}^{-\frac{1}{2}}
A
=D
−21A
D
−21,
A
^
=
A
+
I
\widehat{A}=A+I
A
=A+I,
D
^
\widehat{D}
D
是
A
^
\widehat{A}
A
对应的度矩阵。 值得注意的是,
G
C
N
μ
(
X
,
A
)
GCN_{\mu}(X,A)
GCNμ(X,A)和
G
C
N
σ
(
X
,
A
)
GCN_\sigma(X,A)
GCNσ(X,A)共享参数
W
0
W_0
W0,而各自的
W
1
W_1
W1不同。采样过程和VAE相同,都是用了重参数技巧(reparameterization trick)。
输入:邻接矩阵A和特征矩阵X 过程:通过编码器(图卷积网络)学习节点低维向量表示的均值
μ
\mu
μ和方差
σ
\sigma
σ,然后用解码器(链路预测)生成图。 编码器是简单的两层GCN网络:
q
(
Z
∣
X
,
A
)
=
∑
i
=
1
N
q
(
z
i
∣
X
,
A
)
q(Z|X,A)=\sum_{i=1}^N q(z_i|X,A)
q(Z∣X,A)=i=1∑Nq(zi∣X,A) 其中,
q
(
z
i
∣
X
,
A
)
=
N
(
z
i
∣
μ
i
,
d
i
a
g
(
σ
2
)
)
q(z_i|X,A)=N(z_i|\mu_i,diag(\sigma^2))
q(zi∣X,A)=N(zi∣μi,diag(σ2)),
μ
\mu
μ是节点向量表示
μ
=
G
C
N
μ
(
X
,
A
)
\mu = GCN_{\mu}(X,A)
μ=GCNμ(X,A)的均值,
σ
\sigma
σ是节点向量表示的方差
l
o
g
σ
=
G
C
N
σ
(
X
,
A
)
log\sigma=GCN_\sigma(X,A)
logσ=GCNσ(X,A)。 两层卷积网络定义如下:
G
C
N
(
X
,
A
)
=
A
~
R
e
L
U
(
A
~
X
W
0
)
W
1
GCN(X,A)=\widetilde{A} ReLU(\widetilde{A}XW_0)W_1
GCN(X,A)=A
ReLU(A
XW0)W1 其中,
A
~
=
D
^
−
1
2
A
^
D
^
−
1
2
\widetilde{A}=\widehat{D}^{-\frac{1}{2}}\widehat{A}\widehat{D}^{-\frac{1}{2}}
A
=D
−21A
D
−21,
A
^
=
A
+
I
\widehat{A}=A+I
A
=A+I,
D
^
\widehat{D}
D
是
A
^
\widehat{A}
A
对应的度矩阵。 值得注意的是,
G
C
N
μ
(
X
,
A
)
GCN_{\mu}(X,A)
GCNμ(X,A)和
G
C
N
σ
(
X
,
A
)
GCN_\sigma(X,A)
GCNσ(X,A)共享参数
W
0
W_0
W0,而各自的
W
1
W_1
W1不同。采样过程和VAE相同,都是用了重参数技巧(reparameterization trick)。【本文地址】
今日新闻 |
推荐新闻 |