向量大小和归一化(vector magnitude & normalization)、向量范数(vector norm)、标量/向量/矩阵/张量 |
您所在的位置:网站首页 › unity向量归一化 › 向量大小和归一化(vector magnitude & normalization)、向量范数(vector norm)、标量/向量/矩阵/张量 |
向量大小和归一化(vector magnitude & normalization)、向量范数(vector norm)、标量/向量/矩阵/张量
|
一、向量大小
首先一个向量 空间向量
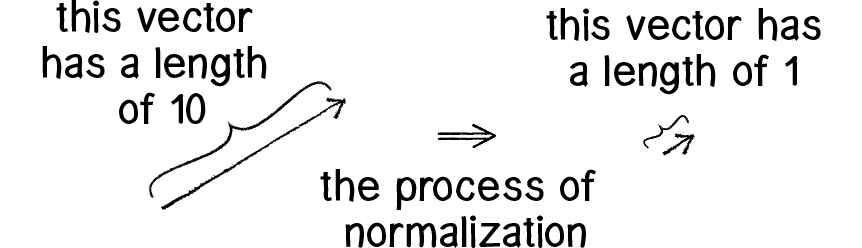
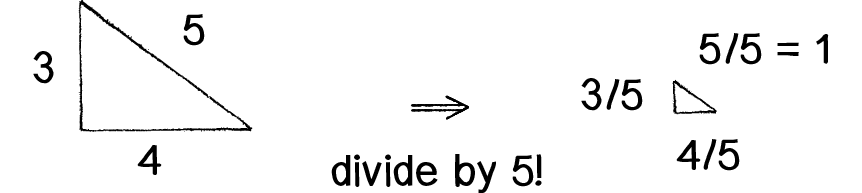
向量归一化即将向量的方向保持不变,大小归一化到1。向量
范数是一种加强了的距离或者长度定义,比距离多一个数乘的运算法则。有时候范数可以当距离来理解。 0、 1、 对 2、 对 3、 4、
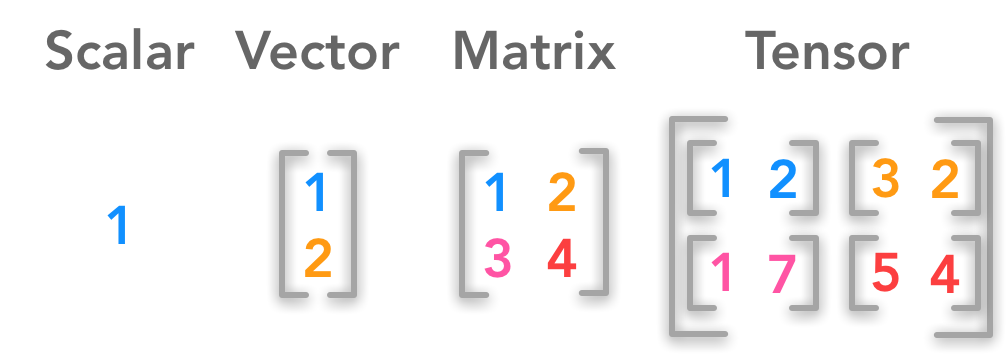
标量是一个数值(1): 向量是一列数值(1*n),有大小和方向: 矩阵是二维的两列数值(m*n),表示一个面: 张量是多维的多列数值(m*n*h),可以表示多维空间(如3维,4维,5维...)。 注意,标量可以看成0维张量,向量看成1维张量,矩阵看成2维张量。 对于矩阵、张量的范数计算,可以分别拉平到向量应用向量范数计算公式得到。 import tensorflow as tf import numpy as np >>> v=tf.ones([3,3]) >>> v >>> v1=tf.norm(v,ord=1) >>> v1 >>> v2=tf.norm(v,ord=2) >>> v2 >>> v3=tf.norm(v,ord=3) >>> v3 >>> vinf=tf.norm(v,ord=np.inf) >>> vinf 五、Keras的regularizers1、 2、 3、 【1】https://www.khanacademy.org/computing/computer-programming/programming-natural-simulations/programming-vectors/a/vector-magnitude-normalization 【2】https://hadrienj.github.io/posts/Deep-Learning-Book-Series-2.1-Scalars-Vectors-Matrices-and-Tensors/ 【3】https://www.overleaf.com/learn/latex/Bold,_italics_and_underlining 【4】https://blog.csdn.net/nanhuaibeian/article/details/103727168 【5】https://blog.csdn.net/a493823882/article/details/80569888 【6】https://keras.io/api/layers/regularizers/ |
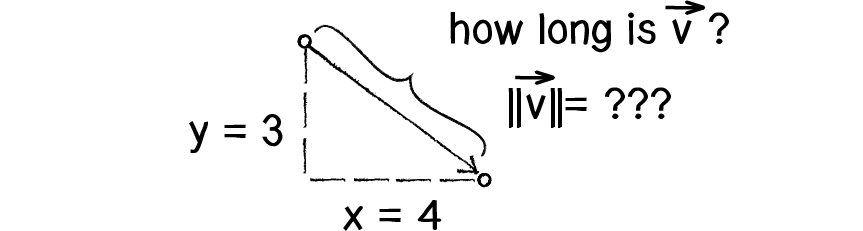
【本文地址】
今日新闻 |
推荐新闻 |