t |
您所在的位置:网站首页 › t分布主要用于 › t |
t
|
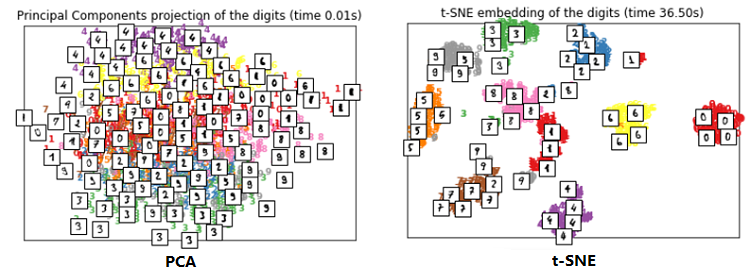
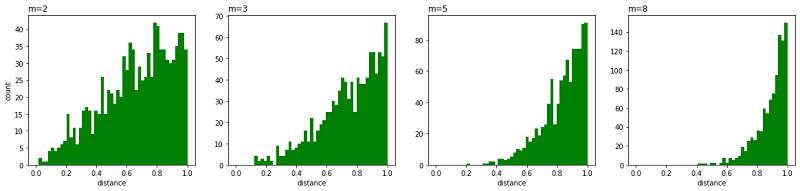
t-SNE 算法 1 前言t-SNE 即 t-distributed stochastic neighbor embedding 是一种用于降维的机器学习算法,在 2008 年由 Laurens van der Maaten 和 Geoffrey Hinton 提出。 t-SNE 是一种非线性降维算法,主要适用于将高维数据降维到 2 维或 3 维 ,方便可视化。但是由于以下种种原因导致它不适合于降维,仅适合可视化: 数据需要降维时,特征间常存在线性相关性,此时常使用线性降维算法,如 PCA。而对于特征之间存在非线性相关,我们并不会先使用非线性降维算法降维再搭配一个线性模型,而是直接使用非线性模型; 一般而言,我们降维并不会把数据维度降维到2 维或者3维,降维的维度一般较大,如降到 20 维,由于 t-SNE 算法使用自由度为 1 的 t 分布很难做到好的效果; t-SNE 算法计算复杂度很高,目标函数非凸,容易得到局部最优解;以下使用 t-SNE 和 PCA可视化手写数字的效果对比: 常见的降维算法: 主成分分析(线性) t-SNE (非参数/非线性) 萨蒙映射(非线性) 等距映射(非线性) 局部线性嵌入(非线性) 规范相关分析(非线性) SNE(非线性) 最小方差无偏估计(非线性) 拉普拉斯特征图(非线性) 2 SNE 算法t-SNE 算法是从 SNE 改进而来,所以先介绍 SNE 。给定一组高维数据 $ \{x_{1}, x_{2}, \ldots, x_{n} \} , x_i=(x_{i}^{(1)}$,$x_{i}^{(2)},x_{i}^{(3)},......x_{i}^{(n)}) $,目标是将这组数据降维到 2 维,SNE 的基本思想是若两个数据在高维空间中是相似的,那么降维到 2 维空间时距离得很近。 2.1 高维空间随机邻近嵌入(SNE) 采用首先通过将数据点之间的高维欧几里得距离转换为相似性的条件概率来描述两个数据之间的相似性。 假设高维空间中的两个点 $ x_{i}, x_{j}$ ,以点 $ x_{i}$ 为中心构建方差为 $ \sigma_{i}$ 的高斯分布。用 $ p_{j \mid i}$ 表示 $ x_{j}$ 在 $ x_{i}$ 邻域的概率,若 $ x_{j}$ 与 $ x_{i}$ 相距很近,那么 $ p_{j \mid i}$ 很大;反之, $ p_{j \mid i}$ 很小。 $ p_{j \mid i}$ 定义如下: $p_{j \mid i}=\frac{\exp \left(-\left\|x_{i}-x_{j}\right\|^{2} /\left(2 \sigma_{i}^{2}\right)\right)}{\sum_{k \neq i} \exp \left(-\left\|x_{i}-x_{k}\right\|^{2} /\left(2 \sigma_{i}^{2}\right)\right)}$ 只关心不同点对之间的相似度,所以设 $p_{i \mid i}=0$ 。 2.2 低维空间当把数据映射到低维空间后,高维数据点之间的相似性也应该在低维空间的数据点上体现出来。 假设 $ x_{i}, x_{j}$ 映射到低维空间后对应 $ y_{i}, y_{j}$,那么 $y_{j}$ 是 $ y_{i}$ 邻域的条件概率为 $ q_{j \mid i}$ : $q_{j \mid i}=\frac{\exp \left(-\left\|y_{i}-y_{j}\right\|^{2}\right)}{\sum \limits _{k \neq i} \exp \left(-\left\|y_{i}-y_{k}\right\|^{2}\right)}$ 低维空间中的方差直接设置为 $ \sigma_{i}=\frac{1}{\sqrt{2}} $ 。同样 $q_{i \mid i}=0$ 。 2.3 目标函数若 $y_{i}$ 和 $y_{j}$ 真实反映了高维数据点 $x_{i}$ 和 $x_{j}$ 之间的关系,那么条件概率 $p_{j \mid i}$ 与 $q_{j \mid i} $ 应该完全相等。这里只考虑了 $x_{i}$ 与 $x_{j}$ 之间的条件概率,若考虑 $x_{i}$ 与其他所有点之间的条件概率,则可构成一个条件概率分布 $P_{i}$。 同理在低维空间存在一个条件概率分布 $Q_{i}$ 且应该与 $P_{i}$ 对应。 衡量两个分布之间的相似性采用 KL 距离(Kullback-Leibler Divergence),SNE 最终目标就是对所有数据点最小化 KL 距 离,我们使用梯度下降算法最小化如下代价函数: $C=\sum\limits_{i} K L\left(P_{i}|| Q_{i}\right)=\sum \limits _{i} \sum \limits_{j} p_{j \mid i} \log \frac{p_{j \mid i}}{q_{j \mid i}}$ 但由于 KL 距离 是一个非对称的度量。最小化代价函数的目的是让 $p_{j \mid i}$ 和 $q_{j \mid i}$ 的值尽可能的接近,即低维空间中点的相似性应当与高维空间中点的相似性一致。但从代价函数的形式可以看出,当 $p_{j \mid i}$ 较大,$q_{j \mid i}$ 较小时,代价较高;而 $p_{j \mid i}$ 较小,$ q_{j \mid i}$ 较大时,代价较低。即高维空间中两个数据点距离较近时,若映射到低维空间后距离较远,那么将得到一个很高的惩罚,这当然没问题。反之,高维空间中两个数据点距离较远时,若映射到低维空间距离较近,将得到一个很低的惩罚值,显然应得到一个较高的惩罚。即SNE的代价函数更关注局部结构,而忽视了全局结构。 2.4 SNE缺点总结一下SNE的缺点: 不对称导致梯度计算复杂。由于条件概率 $p_{j \mid i}$ 不等于 $p_{i \mid j}$,$q_{j \mid i}$ 不等于 $q_{i \mid j} $,因此梯度计算中需要的计算量较大。目标函数计算梯度如下:$\frac{\delta C}{\delta y_{i}}=2 \sum \limits _{j}\left(p_{j \mid i}-q_{j \mid i}+p_{i \mid j}-q_{i \mid j}\right)\left(y_{i}-y_{j}\right)$ Crowing 问题。即不同类别的簇挤在一起,无法区分开来。拥挤问题与某个特定算法无关,而是由于高维空间距离分布和低维空间距离分布的差异造成的。如高维度数据在降维到 10 维,可以有很好的表达,但降维到 2 维后无法得到可信映射。假设一个以数据点 $x_i$ 为中心,半径为 $r$ 的 $m$ 维球(三维空间就是球),其体积是按 $r^m$ 增长的,假设数据点是在 $m$ 维球中均匀分布的,我们来看看其他数据点与 $x_i$ 的距离随维度增大而产生的变化。 从上图可以看到,随着维度的增大,大部分数据点都聚集在 $m$ 维球的表面附近,与点 $x_i$ 的距离分布极不均衡。如果直接将这种距离关系保留到低维,就会出现拥挤问题。 import matplotlib.pyplot as plt import numpy as np from numpy.linalg import norm npoints = 1000 # 抽取1000个m维球内均匀分布的点 plt.figure(figsize=(20, 4)) for i, m in enumerate((2, 3, 5, 8)): # 这里模拟m维球中的均匀分布用到了拒绝采样,即先生成m维立方中的均匀分布,再剔除m维球外部的点 accepts = [] while len(accepts) < 1000: points = np.random.rand(500, m) accepts.extend([d for d in norm(points, axis=1) if d |
【本文地址】
今日新闻 |
推荐新闻 |