卷积神经网络学习笔记 |
您所在的位置:网站首页 › transition翻译 › 卷积神经网络学习笔记 |
卷积神经网络学习笔记
|
完整代码及其数据,请移步小编的GitHub地址
传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote 这里结合网络的资料和DenseNet论文,捋一遍DenseNet,基本代码和图片都是来自网络,这里表示感谢,参考链接均在后文。下面开始。 DenseNet 论文写的很好,有想法的可以去看一下,我这里提供翻译地址: 深度学习论文翻译解析(十五):Densely Connected Convolutional Networks 自ResNet提出以后,ResNet的变种网络层出不穷,都各有其特点,网络性能也有一定的提升。本文学习CVPR 2017最佳论文 DenseNet,论文中提出的 DenseNet(Dense Convolutional Network)主要还是和ResNet以及Inception网络做对比,思想上有所借鉴,但是却是全新的结构,网络结构并不复杂,却非常有效,在CIFAR指标上全面超越ResNet,可以说是DenseNet吸收了ResNet 最精华的部分,并在此上做了更加创新的工作,使得网络性能进一步提升。 1,ResNet VS DenseNet首先,我们通过对ResNet的对比来大概了解一下 DenseNet。 下图为ResNet网络的短路连接机制(其中+代表的是元素级相加操作)。
可以看出ResNet是每个层与前面的某层(一般是2~3层)短路连接到一起,连接方式是通过元素级相加。 DenseNet的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另外一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能。 相比ResNet,DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在 channel维度上连接(Concat)在一起(这里各个层的特征图大小是相同的,后面会说明),并作为下一层的输入。对于一个 L 层的网络,DenseNet共包含L*(L+1)/2 个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接Concat来自不同层的特征图,这可以实现特征重用,提高效率,这一特点是DenseNet和ResNet最主要的区别。 需要明确一点,Dense connectivity 仅仅是在一个 Dense Block 里的,不同 Dense Block 之间是没有Dense Connectivity的。 下图为DenseNet网络的密集连接机制(其中C代表的是 channel级连接操作),在DenseNet中直接 concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。
如果用公式表示的话,传统的网络在 l 层的输出为:
而对于ResNet,增加了来自上一层输入的 identity函数:
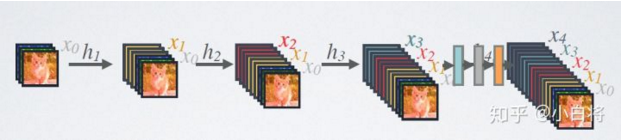
其中,上面的 Ht(*) 代表是非线性转换函数(non-linear-transformation),它是一个组合操作,其可能包括一系列的 BN(Batch Normalization),ReLU,Pooling及其Conv操作。注意这里的 l 层与 l-1 层之间实际上包含多个卷积层。 1.1 Keras中add和 concatenate 操作的不同说起ResNet和DenseNet的区别了,就不得不说一下代码层面了,毕竟我们的目的是实现它。 首先说结论,ResNet的使用都是 add 操作,而DenseNet和InceptionNet使用的都是 concatenate操作。 关于 Concatenate 操作 拼接,H,W 都不改变,但是通道数增加。 网络结构设计中很重要的一种操作,经常用于将特征联合,多个卷积提取框架提取的特征融合或者是将输出层的信息进行融合。Densenet 是做通道的合并,而Concatnate 是通道数的合并,也就是说描述图像本身的特征增加了,而每一特征下的信息是没有增加的。 Keras 中 Concatnate 函数与 concatnate 函数 这里直接分析源码,不多分析只看区别: 首先是 Concatenate()函数: class Concatenate(_Merge): """Layer that concatenates a list of inputs. It takes as input a list of tensors, all of the same shape except for the concatenation axis, and returns a single tensor, the concatenation of all inputs. # Arguments axis: Axis along which to concatenate. **kwargs: standard layer keyword arguments. """再来是 concatenate()函数: def concatenate(inputs, axis=-1, **kwargs): """Functional interface to the `Concatenate` layer. # Arguments inputs: A list of input tensors (at least 2). axis: Concatenation axis. **kwargs: Standard layer keyword arguments. # Returns A tensor, the concatenation of the inputs alongside axis `axis`. """ return Concatenate(axis=axis, **kwargs)(inputs)concatenate() 函数 是 Concatenate() 函数的接口函数,我们可以使用两个中的任意一个,但是方法要写正确。后面我们会做代码验证。 关于 Add 操作 加,H,W,C 都不改变,只是相应元素的值会改变。 信息之间的叠加,ResNet是做值的叠加,通道数是不变的。add是描述图像的特征下的信息量增多了,但是描述图像的维度本身没有增加,只是在每一维度下信息量在增加。 Keras 中 Add 函数与 add 函数 这里直接分析源码,不多分析只看区别: 首先是 Add()函数: class Add(_Merge): """Layer that adds a list of inputs. It takes as input a list of tensors, all of the same shape, and returns a single tensor (also of the same shape). # Examples ```python import keras input1 = keras.layers.Input(shape=(16,)) x1 = keras.layers.Dense(8, activation='relu')(input1) input2 = keras.layers.Input(shape=(32,)) x2 = keras.layers.Dense(8, activation='relu')(input2) # equivalent to added = keras.layers.add([x1, x2]) added = keras.layers.Add()([x1, x2]) out = keras.layers.Dense(4)(added) model = keras.models.Model(inputs=[input1, input2], outputs=out) ``` """再来是 add()函数: def add(inputs, **kwargs): """Functional interface to the `Add` layer. # Arguments inputs: A list of input tensors (at least 2). **kwargs: Standard layer keyword arguments. # Returns A tensor, the sum of the inputs. # Examples ```python import keras input1 = keras.layers.Input(shape=(16,)) x1 = keras.layers.Dense(8, activation='relu')(input1) input2 = keras.layers.Input(shape=(32,)) x2 = keras.layers.Dense(8, activation='relu')(input2) added = keras.layers.add([x1, x2]) out = keras.layers.Dense(4)(added) model = keras.models.Model(inputs=[input1, input2], outputs=out) ``` """ return Add(**kwargs)(inputs)add() 函数 是 Add() 函数的接口函数,我们可以使用两个中的任意一个,但是方法要写正确。后面我们会做代码验证。 代码展示Keras中四个函数的区别 代码如下: from keras.layers import Concatenate, Add, add, concatenate import numpy as np import tensorflow as tf matrix1 = np.array([[1,2,3], [4,5,6]]) matrix2 = np.array([[11,22,33], [44,55,66]]) # 将一个numpy数据转换为tensor t1 = tf.convert_to_tensor(matrix1) t2 = tf.convert_to_tensor(matrix2) print(t1) print(t2) ''' [[1 2 3] [4 5 6]] [[11 22 33] [44 55 66]] Tensor("Const:0", shape=(2, 3), dtype=int32) Tensor("Const_1:0", shape=(2, 3), dtype=int32) ''' exp_Add = Add()([t1, t2]) exp_Concatenate = Concatenate()([t1, t2]) print(exp_Add) print(exp_Concatenate) # 要对tensor进行操作,需要先启动一个Session with tf.Session() as sess: print('exp_Concatenate is ', exp_Add.eval()) print('exp_Concatenate is ', exp_Concatenate.eval()) ''' exp_Concatenate is [[12 24 36] [48 60 72]] exp_Concatenate is [[ 1 2 3 11 22 33] [ 4 5 6 44 55 66]] Tensor("add_1/add:0", shape=(2, 3), dtype=int32) Tensor("concatenate_1/concat:0", shape=(2, 6), dtype=int32) ''' exp_Add1 = add([t1, t2]) exp_Concatenate1 = concatenate([t1, t2]) print(exp_Add1) print(exp_Concatenate1) ''' Tensor("add_2/add:0", shape=(2, 3), dtype=int32) Tensor("concatenate_2/concat:0", shape=(2, 6), dtype=int32) ''' with tf.Session() as sess: print(exp_Add1.eval() == exp_Add.eval()) print(exp_Concatenate1.eval() == exp_Concatenate.eval()) ''' [[ True True True] [ True True True]] [[ True True True True True True] [ True True True True True True]] '''2,DenseNet网络架构 当CNNs增加深度的时候,就会出现一个紧要的问题:当输入或者梯度的信息通过很多层之后,它可能会消失或过度膨胀。研究表明,如果卷积网络在接近输入和接近输出地层之间包含较短地连接,那么,该网络可以显著地加深,变得更精确并且能够更有效的训练。在论文中提出的架构为了确保网络层之间的最大信息流,将所有层直接彼此连接。为了保持前馈特性,每个层从前面的所有层获得额外的输入,并将自己的特征映射传递到后面的所有层。该论文基于这个观察提出了以前馈的方式将每个层与其他层连接的密集卷积网络(DenseNet)。 原作者通过观察目前深度网络的一个重要特点就是都加入了 shorter connections,能够让网络更深,更准确,更高效。作者充分利用了 skip connections ,设计了一种稠密卷积神经网络(Dense Convolutional Network),让每一层都接受它前面所有层的输出。对于传统卷积结构,L层一共有L个 connections,但DenseNet,L层一共有L(L-1)/2 个 Connection。 2.1 DenseNet闪光点 1,相比ResNet 拥有更少的参数数量 2,旁路加强了特征的重用 3,网络更易于训练,并具有一定的正则效果 4,缓解了梯度消失(gradient vanishing)和模型退化(model degradation)的问题 2.2 DenseNet 网络分析DenseNet 是一种具有密集连接的卷积神经网络。在该网络中,任何两层之间都有直接的连接,也就是说,网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入。 下图是一个五层的密集块:
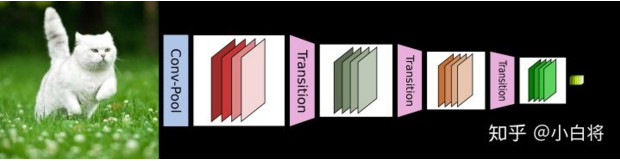
DenseNet 的前向过程如上图所示,可以更直观地理解其密集连接方式,比如 h3 的输入不仅包括来自 h2 的 x2,还包括前面两层的 x1 和 x2,他们是在 channel 维度上连接在一起的。 下图给出了DenseNet的网络结构,它共包含 4个 DenseBlock,各个 DenseBlock之间通过Transition 连接在一起。
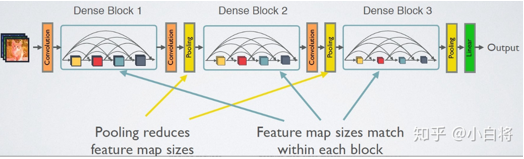
CNN网络一般要经过Pooling或者 stride>1 的Conv 来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用 DenseBlock + Transition 的结构,其中 DenseBlock 是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而 Transition模块是连接两个相邻的 DenseBlock ,并且通过 Pooling使特征图大小降低。 2.3 Dense Block首先展示一下Dense Block网络结构: Dense Block模块:BN + ReLU + Conv(3*3) + dropout transition layer模块:BN + ReLU + Conv(1*1)(filter_num:m) + dropout + Pooling(2*2) 我们知道DenseNet的网络结构主要由DenseBlock和 Transition组成,下面具体来学习网络的实现细节,首先看网络结构:
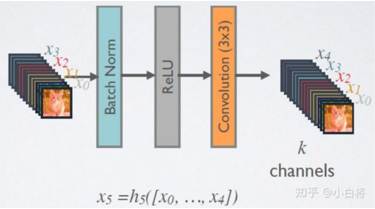
在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合 H(*) 采用的是 BN+ReLU+3*3Conv 的结构,如下图所示:
该架构与ResNet相比,在将特性传递到层之前,没有通过求和来组合特性,而是通过连接他们的方式来组合特性。因此第 x 层(输入层不算在内)将由 x个输出的特征图,这些输入是之前所有层提取出的特征信息,或者说采用 x 个卷积核, x 在DenseNet称为 growth rate,这是一个超参数,一般情况下使用较小的 k(比如12),就可以得到较佳的性能。假定输入层的特征图的 channels 数为 k0,那么 l 层的输入的 channel 数为 k0 + k(l - 1),因此随着层数的增加,尽管k设定的较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有 K 个特征是自己独有的,因为它的密集连接特性,研究人员将其称为 Dense Convolutional Network(DenseNet)。 因为不需要重新学习冗余特征图,这种密集连接模式相对于传统的卷积网络只需要更少的参数。传统的前馈体系结构可以看做是具有一种状态的算法,这种状态从一个层传递到另一个层。每个层从其前一层读取状态并将其写入后续层。它改变状态,但也传递需要保留的信息。研究提出的密集网络体系结构明确区分了添加到网络的信息和保留的信息。密集网层非常窄(例如:每层12个过滤器),仅向网络的“集体知识”添加一小组特征映射,并且保持其余特征映射不变,并且最终分类器基于网络中的所有特征映射做出决策。 除了参数更少,另一个DenseNets 的优点是改进了整个网络的信息流和梯度,这使得他们易于训练。每个层直接访问来自损失函数和原始输入信号的梯度,带来了隐式深度监控。这使得训练深层网络变得更简单。此外,研究人员观察到密集连接具有规则化效果,这减少了对训练集较小的任务的过拟合。 2.4 DenseNet-B首先展示一下 DenseNet-B 网络结构: Dense Block模块:BN + ReLU + Conv(1*1)(filter_num:4K) + dropout + BN + ReLU + Conv(3*3) + dropout transition layer模块:BN + ReLU + Conv(1*1)(filter_num:m) + dropout + Pooling(2*2) 密集连接不会带来冗余吗?不会!密集连接这个词给人的第一感觉就是极大地增加了网络的参数量和计算量。但是实际上DenseNet比其他网络效率更高,其关键就在于网络每层计算量的减少以及特征的重复利用。DenseNet 则是让 l 层的输入直接影响到之后的所有层,它的输出为:xl = H1([X0, X1, ... Xl-1]),其中 [X0, x1, ...Xl-1] 就是将之前的 feature map 以通道的维度进行合并。并且由于每一层都包含之前所有层的输出信息,因此其只需要很少的特征图就够了,这也是为什么 DenseNet的参数量较其他模型大大减少的原因。这种Dense Connection 相当于每一层都直接连接 input 和 loss,因此就可以减轻梯度消失现象,这样更深网络不是问题。需要明确一点,Dense Connectivity 仅仅是在一个 Dense Block里的,不同Dense Block 之间是没有Dense Connectivity的,比如下图所示:
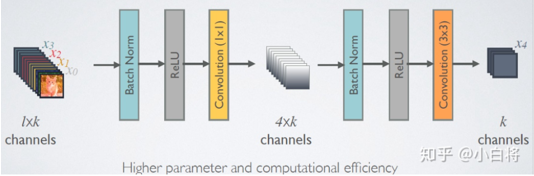
天底下没有免费的午餐,网络自然也不例外。在同层深度下获得更好的收敛率,自然是由额外代价的,其代价之一就是其恐怖如斯的内存占用。 每一个DenseBlock模块的输出维度有多大呢? 假设一个L层的Dense Block模块中输出K个 feature map,即网络增长率为K,其中已经加入了Bottleneck单元,那么第L层的输入为K0 + K*(L-1)(其中第K0为输入层的维度),而总共输出的维度为:第一层的维度 + 第二层的维度 + 第三层的维度 + ... + 第L层的维度,加入Bottleneck单元后每层的输出维度为4K,那么最终 Dense Block模块的输出维度为4K*L。也就是说随着Dense Block 模块深度的加深,即随着层数L的增加,最终输出的 feature map 的维度也是一个很大的数,为了解决这个问题,在transition layer模块中加入了1*1卷积做降维。 为了解决这个问题,在Dense Block模块中加入了 Bottleneck单元,如下图所示,即 BN + ReLU + 1*1Conv + BN + ReLU + 3*3 Conv,称为 DenseNet-B结构。其中1*1Conv降维得到 4k 个特征图它起到的作用是降低特征数量,从而提升计算效率(K为增长率)。
首先展示一下 DenseNet-BC 网络结构: Dense Block模块:BN + ReLU + Conv(1*1)(filter_num:4K) + dropout + BN + ReLU + Conv(3*3) + dropout transition layer模块:BN + ReLU + Conv(1*1)(filter_num:θm,其中 0 |

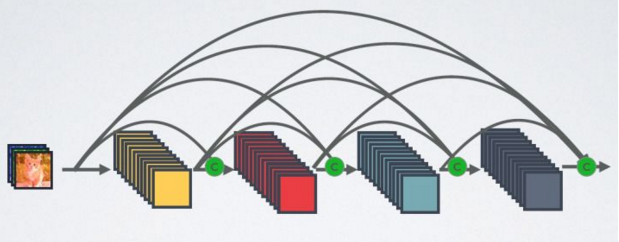
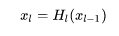
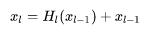 在DenseNet中,会连接前面所有层作为输入:
在DenseNet中,会连接前面所有层作为输入: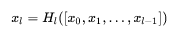

【本文地址】
今日新闻 |
推荐新闻 |