大幅优化推理过程,字节高性能Transformer推理库获IPDPS 2023最佳论文奖 |
您所在的位置:网站首页 › transformer变长输入 › 大幅优化推理过程,字节高性能Transformer推理库获IPDPS 2023最佳论文奖 |
大幅优化推理过程,字节高性能Transformer推理库获IPDPS 2023最佳论文奖
|
机器之心专栏 机器之心编辑部 字节跳动与英伟达,加州大学河滨分校联合发表的论文 《ByteTransformer: A High-Performance Transformer Boosted for Variable-Length》在第 37 届 IEEE 国际并行和分布式处理大会(IPDPS 2023)中,从 396 篇投稿中脱颖而出,荣获了最佳论文。 论文《ByteTransformer: A High-Performance Transformer Boosted for Variable-Length》提出了字节跳动的 GPU Transformer 推理库 ——ByteTransformer。针对自然语言处理常见的可变长输入,论文提出了一套优化算法,这些算法在保证运算正确性的前提下,成功避免了传统实现中的冗余运算,实现了端到端的推理过程的大幅优化。另外,论文中还手动调优了 Transformer 中的 multi-head attention, layer normalization, activation 等核心算子, 将 ByteTransformer 的推理性提升至业界领先水平。与 PyTorch, TensorFlow, NVIDIA FasterTransformer, Microsoft DeepSpeed-Inference 等知名的深度学习库相比,ByteTransformer 在可变长输入下最高实现 131% 的加速。论文代码已开源。  论文地址:https://arxiv.org/abs/2210.03052 代码地址:https://github.com/bytedance/ByteTransformer Transformer 变长文本 padding free Transformer 在自然语言处理(NLP)中被广泛使用,随着 BERT、GPT-3 等大型模型的出现和发展,Transformer 模型的重要性变得越来越突出。这些大型模型通常具有超过一亿个参数,需要大量的计算资源和时间进行训练和推理。因此,优化 Transformer 性能变得非常重要。 现有的一些深度学习框架,如 Tensorflow,PyTorch,TVM 以及 NVIDIA TensorRT 等,要求输入序列长度相同,才能利用批处理加速 Transformer 计算。然而,在实际场景中,输入序列通常是变长的,而零填充会引入大量的额外计算开销。有一些方法在 kernel launch 前对具有相似 seqlen 的输入分组,以最小化 padding,但无法实现 padding free。字节跳动 AML 团队先前提出的 “effective Transformer” [4],通过对输入的重排列,实现了 QKV projection 和 MLP 的 padding free,但 self attention 部分仍然需要 padding。 为了解决这个问题,字节跳动 AML 团队提出了 ByteTransformer,它实现了变长输入的 padding free 计算,并且实现了全面的 kernel fusion 以进一步提高性能。 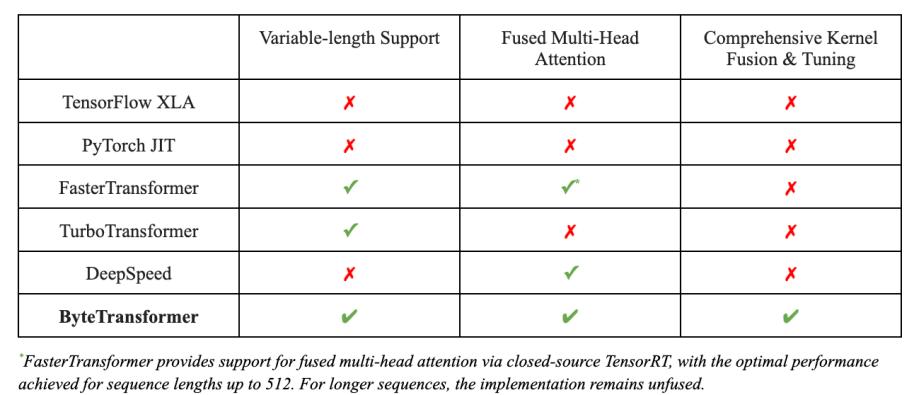 ByteTransformer 与其他工作 feature 对比 Remove padding 算法 这个算法源自字节跳动 AML 团队之前的工作 "effective Transformer",在 NVIDIA 开源 FasterTransformer 中也有集成。ByteTransformer 同样使用该算法去除对 attention 外矩阵乘的额外计算。 算法步骤: 计算 attention mask 的前缀和,作为 offsets 根据 offsets 把输入张量从 [batch_size, seqlen, hidden_size] 重排列为 valid_seqlen, hidden_size] ,再参与后续的矩阵乘计算,实现 padding free 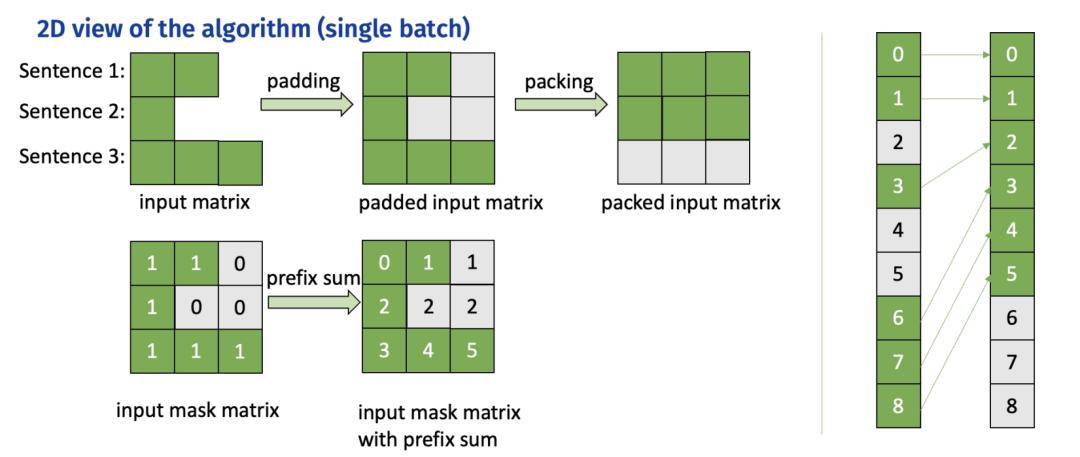 Remove padding 算法过程 FMHA (Fused Multi-Head Attention) 为了优化 attention 部分的性能,ByteTransformer 中实现了 fused multi-head attention 算子。对于 seqlen 长度,以 384 为界划分为两种实现方式: 对于短 seqlen, 因为可以把 QK 整行放在共享内存进行 softmax 操作,通过手写 kernel 的方式实现,矩阵乘通过调用 wmma 接口使用 TensorCore 保证高性能。 对于长 seqlen, 因为共享内存大小限制,不能在一个手写 kernel 中完成所有操作。基于高性能的 CUTLASS [5] grouped GEMM, 分成两个 gemm kernel 实现,并把 add_bias, softmax 等操作 fused 到 GEMM kernel 中。 1.CUTLASS grouped GEMM NVIDIA 开发的 grouped GEMM 可以在一个 kernel 中完成多个独立矩阵乘问题的计算,利用这个性质可以实现 Attention 中的 padding free。 Attention 中的两次矩阵乘操作,都可以拆解为 batch_size x head_num 个独立的矩阵乘子问题。 每个矩阵乘子问题,把问题大小传入到 grouped GEMM,其中 seqlen 传递真实的 valid seqlen 即可。 grouped GEMM 原理:kernel 中每个 threadblock (CTA) 固定 tiling size,每个矩阵乘子问题根据 problem size 和 tiling size,拆解为不同数量的待计算块,再把这些块平均分配到每个 threadblock 中进行计算。 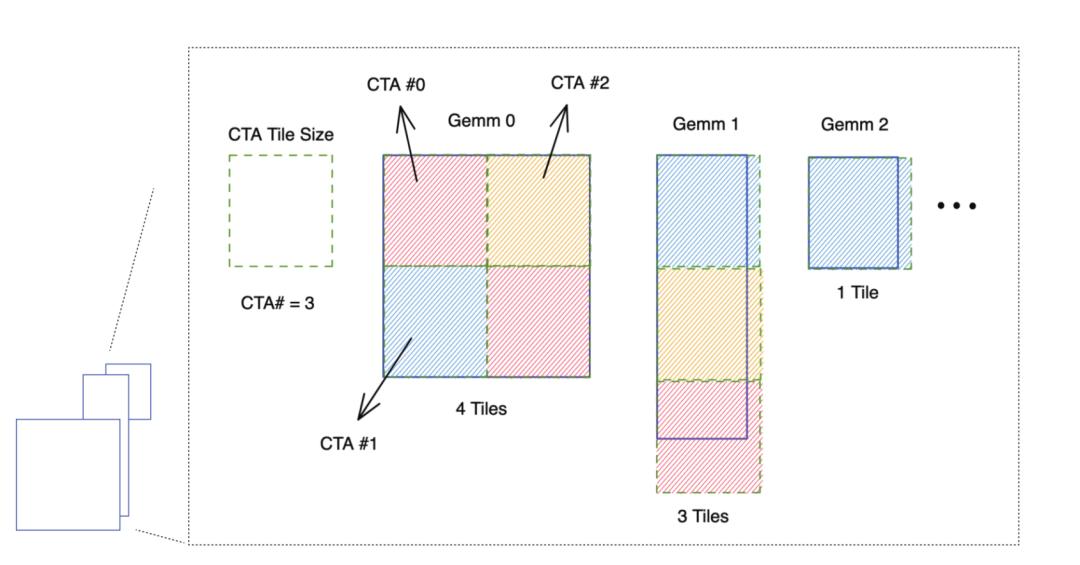 grouped GEMM 原理示意图。每个子问题拆解为不同数量的块,再对这些块均匀分配,高效地实现单个 kernel 计算多个独立 GEMM 问题 使用 grouped GEMM 实现 attention 时,由于子问题的数量 batch_size x head_num 通常较大,读取子问题参数会有不小的开销,因为从线程角度看,每个线程都需要遍历读取所有的子问题大小。 为了解决这个问题,ByteTransformer 对 grouped GEMM 中读取子问题参数进行了性能优化,使其可以忽略不计: 共享子问题参数。对同一个输入,不同 head 的 valid seqlen 相同,problem size 也相同,通过共享使参数存储量从 batch_size x head_num 减少到 batch_size。 warp prefetch. 原始实现中,每个 CUDA thread 依次读取所有的子问题 problem size,效率很低。改为一个 warp 内线程读取连续的 32 个子问题参数,然后通过 warp 内线程通信交换数据,每个线程的读取次数降低到 1/32。 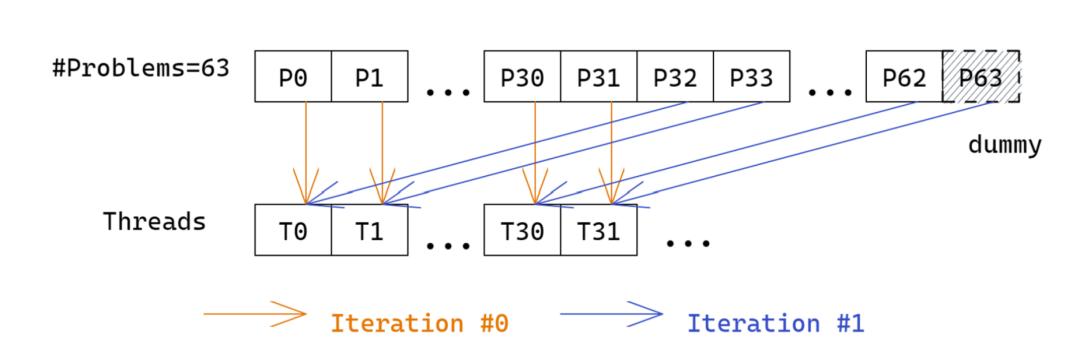 warp prefetch 示意图。每个 iteration 一个 warp 读取 32 个子问题 size 2.softmax fusion 为了进一步提高性能,把 Q x K 之后的 softmax 也 fuse 到矩阵乘算子中,相比单独的 softmax kernel 节省了中间矩阵的访存操作。 因为 softmax 需要对整行数据做归约,但因为共享内存大小的限制,一个 threadblock 内不能容纳整行数据,同时 threadblock 间的通信很低效,所以不能仅在 Q x K 的 epilogue 中完成整个 softmax 的操作。把 softmax 拆分成三步计算,分别 fuse 到 Q x K 的 epilogue 中, QK x V 的 prologue 中,以及中间再添加一个轻量的 kernel 做规约。 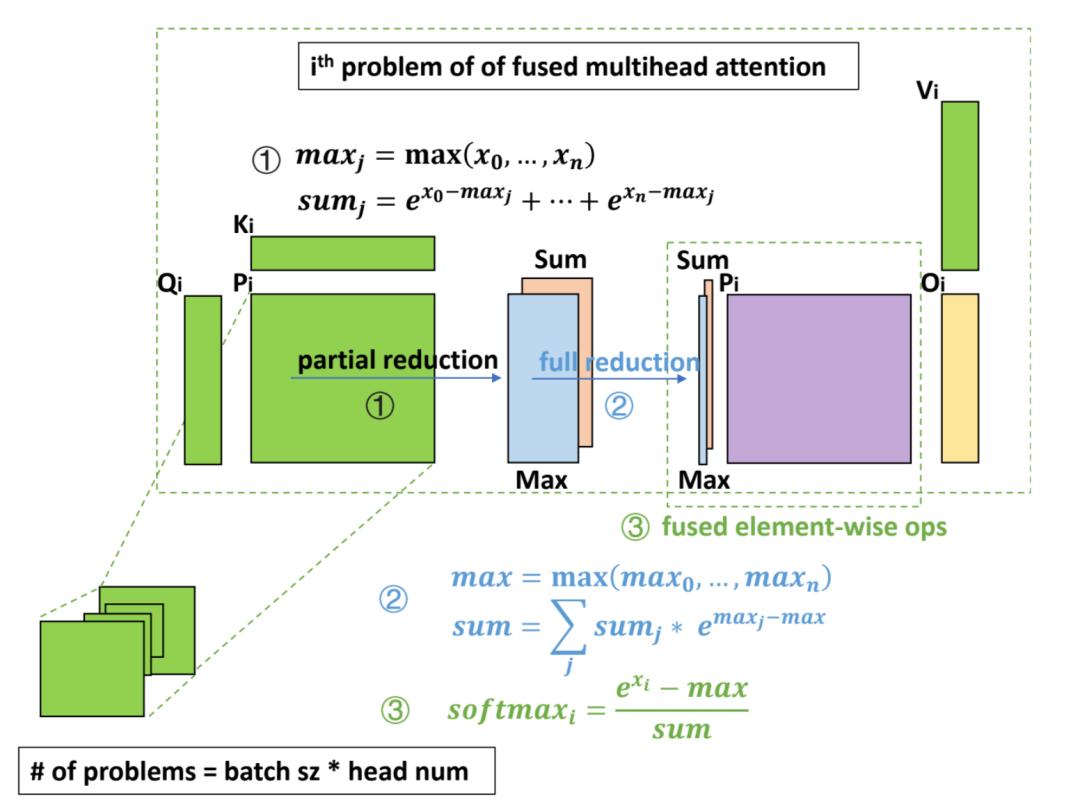 softmax fusion 流程示意图。分为三步计算,大部分计算 fuse 到前后的 GEMM kernel 中 算法步骤: partial reduction:Q x K 的 epilogue 中,每个 threadblock 内部规约,计算出 max 和 sum 两个值。 full reduction:一个轻量级的 kernel,把每一行的 partial reduction 结果继续规约到整行的结果。 element-wise op:修改了 CUTLASS 的代码,使其支持 prologue fusion,即在加载输入矩阵后,fuse 一些 element-wise 的操作。在 QK x V 的 prologue 中,读取当前行的规约结果,计算出 softmax 的最终结果,再参与后续的矩阵乘计算。 3.性能数据 3.1 短 seqlen 手写 kernel 的性能 在 |
【本文地址】