[医学图像Transformer] Medical Transformer: Gated Axial |
您所在的位置:网站首页 › transformer代码例子 › [医学图像Transformer] Medical Transformer: Gated Axial |
[医学图像Transformer] Medical Transformer: Gated Axial
|
医学图像Transformer:一种用于医学图像分割的门控轴向注意力网络 论文地址 开源代码 摘要大多数现有的基于Transformer的网络架构用于视觉应用,但需要大规模数据集来正确训练。然而,与用于视觉应用的数据集相比,用于医学成像的数据样本数量相对较低,使得难以有效地训练用于医学应用的Transformer。为此,我们提出了一个门控轴向注意(Gated Axial-Attention)模型,该模型通过在自注意模块中引入额外的控制机制来扩展现有的体系结构。此外,为了在医学图像上有效地训练模型,我们提出了局部-全局训练策略(LoGo),进一步提高了性能。具体来说,我们对整个图像和patch进行操作,分别学习全局和局部特征。 存在的问题及解决方案传统的卷积网络缺乏对图像中存在的长期相关性建模的能力。更准确地说,在卷积网络中,每个卷积核只处理整个图像中的局部像素子集,并迫使网络关注局部模式,而不是全局上下文。虽然有一些工作致力于改进这一问题,例如pyramids,atrous convolutions和attention mechanisms等。然而,可以注意到,由于大多数以前的方法不关注医学图像分割任务的这一方面,所以对于建模长期相关性仍有改进的余地。 我们观察到,基于Transformer的模型只有在大规模数据集上训练时才能很好地工作。当采用用于医学成像任务的Transformer时,这就成了问题,因为在医学数据集中可用于训练的具有相应标签的图像数量相对稀少。 为此,我们提出了一种门控位置敏感轴向(gated position-sensitive axial)注意机制,其中我们引入了四个门来控制位置嵌入提供给键、查询和值的信息量。这些门是可学习的参数,使得所提出的机制适用于任何大小的任何数据集。根据数据集的大小,这些门将了解图像的数量是否足以学习正确的位置嵌入(positional embedding)。基于通过位置嵌入学习的信息是否有用,门参数要么收敛到0,要么收敛到某个更高的值。此外,我们提出了一个局部-全局(LoGo)训练策略,其中我们使用一个浅的全局分支和一个深的局部分支来操作医学图像的patch。这种策略提高了分割性能,因为我们不仅对整个图像进行操作,而且关注局部块中存在的更精细的细节。 方法 Medical Transformer (MedT)
假定输入特征图为
x
∈
R
C
i
n
×
H
×
W
x \in \mathbb{R}^{C_{i n} \times H \times W}
x∈RCin×H×W,高度为
H
H
H,宽度为
W
W
W。自注意层的输出
y
∈
R
C
out
×
H
×
W
y \in \mathbb{R}^{C_{\text {out }} \times H \times W}
y∈RCout ×H×W可以通过如下公式计算得到: 为了克服计算相似度的计算复杂性,将单个自注意分解为两个自注意模块。第一个模块在特征图高度轴上执行自注意,第二个模块在宽度轴上执行自注意。这一操作被称为轴向注意机制。因此,在高度轴和宽度轴上应用的轴向注意有效地模拟了原始的自我注意机制,具有更好的计算效率。为了在通过自我注意机制计算亲和力的同时增加位置偏差,增加了位置偏差项以使亲和力(affinities)对位置信息敏感。这个偏置项通常被称为相对位置编码。这些位置编码通常可以通过训练来学习,并且已经被证明具有对图像的空间结构进行编码的能力。 Wang et al.结合轴向注意机制和位置编码提出了一种基于注意的图像分割模型。此外,与以前的注意模型不同,以前的注意模型只对查询使用相对位置编码,Wang et al.建议将它用于所有查询、键和值。查询、键和值中的这种额外位置偏差显示为捕捉具有精确位置信息的远程交互。对于任何给定的输入特征图
x
x
x,带有位置编码和宽度轴的更新自我关注机制可以写成: 具体来说,轴向注意能够以良好的计算效率计算非局部环境,能够将位置偏差编码到机制中,并能够在输入特征图中编码远程交互信息。然而,他们的模型是在大规模的分割数据集上评估的,因此轴向注意力更容易学习键、查询和值的位置偏差。我们认为,对于小规模数据集的实验(医学图像分割中经常出现这种情况),位置偏差很难学习,因此在编码远程交互时并不总是准确的。在学习的相对位置编码不够精确的情况下,将它们添加到相应的键、查询和值张量将导致性能下降。因此,我们提出了一种改进的轴向注意块,它可以控制位置偏差对非局部上下文编码的影响。根据提出的修改,应用在宽度轴上的自注意机制可以写成: 很明显,在patches上训练一个Transformer更快,而且有助于提取图像的细节。然而,对于像医学图像分割这样的任务来说,单独的逐块训练是不够的。分割掩码很可能会大于patch大小。这限制了网络学习片间的像素信息或依赖性。为了提高对图像的整体理解,我们建议使用网络的两个分支,即一个全局分支处理图像的原始分辨率,一个局部分支处理图像的patches。 在全局分支中,我们减少了门控轴向Transformer的数量,因为我们发现所提出的Transformer模型的前几个块足以模拟长程相关性。在局部分支中,通过网络转发每个patch,并根据它们的位置对输出特征图进行重新采样,以获得最终的输出特征图。然后将两个分支的输出特征图相加,并通过1 × 1卷积层,产生输出分割掩码。由于全局分支专注于高级信息,而局部分支专注于更精细的细节,因此具有在图像的全局上下文上操作的较浅模型和在patches上操作的较深模型的这种策略提高了性能。 实验
在这项工作中,我们探索使用基于Transformer的编码器架构进行医学图像分割,而无需任何预训练。我们提出了一个门控轴向注意层,作为网络编码器多头注意模型的构建模块。我们还提出了一个LoGo训练策略,在该策略中,我们使用相同的网络架构在全分辨率和patch中训练图像。全局分支通过对长期依赖关系建模来帮助网络学习高级特征,而局部分支通过对patch进行操作来关注更精细的特征。利用这些,我们提出了MedT(医用Transformer),它将轴向注意力作为编码器的主要构件,并使用LoGo策略来训练图像。我们在三个数据集上进行了广泛的实验,在这些数据集上,我们实现了MedT优于卷积和其他相关的基于Transformer的架构的良好性能。 |
 为了首先理解为什么医学图像的长程相关性很重要,我们设想了一个早产儿超声扫描的例子,并根据图1中的扫描对脑室进行了分割预测。对于提供有效分割的网络,它应该能够理解哪些像素对应于掩码(mask),哪些对应于背景。给定单个像素,网络需要了解它是更接近背景的像素还是更接近分割掩码的像素。由于图像的背景是分散的,学习对应于背景的像素之间的长程相关性可以在网络中有助于防止将背景像素误分类为前景,类似地,每当分割掩码(前景)很大时,学习对应于掩码的像素之间的长程相关性也有助于做出有效的预测。在图1(b)和(c)中,我们可以看到卷积网络将背景误分类为脑室,而提出的基于Transformer的方法没有犯这个错误。
为了首先理解为什么医学图像的长程相关性很重要,我们设想了一个早产儿超声扫描的例子,并根据图1中的扫描对脑室进行了分割预测。对于提供有效分割的网络,它应该能够理解哪些像素对应于掩码(mask),哪些对应于背景。给定单个像素,网络需要了解它是更接近背景的像素还是更接近分割掩码的像素。由于图像的背景是分散的,学习对应于背景的像素之间的长程相关性可以在网络中有助于防止将背景像素误分类为前景,类似地,每当分割掩码(前景)很大时,学习对应于掩码的像素之间的长程相关性也有助于做出有效的预测。在图1(b)和(c)中,我们可以看到卷积网络将背景误分类为脑室,而提出的基于Transformer的方法没有犯这个错误。 MedT主要由两个分支构成,全局分支(Global Branch)和局部分支(Local Branch)。在两个分支的编码器中,我们使用我们提出的Transformer层,而在解码器中使用简单的conv块。编码器Bottleneck包括1×1卷积层和两层多头注意层,其中一层沿高度轴操作,另一层沿宽度轴操作。每个多头注意块由提出的门控轴向注意层(gated axial attention layer)组成。
MedT主要由两个分支构成,全局分支(Global Branch)和局部分支(Local Branch)。在两个分支的编码器中,我们使用我们提出的Transformer层,而在解码器中使用简单的conv块。编码器Bottleneck包括1×1卷积层和两层多头注意层,其中一层沿高度轴操作,另一层沿宽度轴操作。每个多头注意块由提出的门控轴向注意层(gated axial attention layer)组成。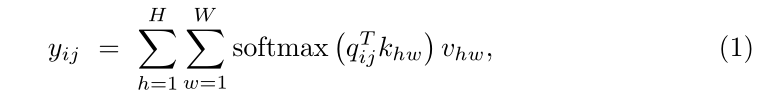 其中queries为
q
=
W
Q
x
q=W_Qx
q=WQx,keys为
k
=
W
K
x
k=W_Kx
k=WKx,values为
W
V
x
W_Vx
WVx,这些都是通过对输入
x
x
x计算投影所得。这里,
q
i
j
q_{ij}
qij,
k
i
j
k_{ij}
kij,
v
i
j
v_{ij}
vij分别表示在所有任意位置
i
∈
{
1
,
…
,
H
}
i \in\{1, \ldots, H\}
i∈{1,…,H} and
j
∈
{
1
,
…
,
W
}
j \in\{1, \ldots, W\}
j∈{1,…,W}上的query,key和value。投影矩阵
W
Q
,
W
K
,
W
V
∈
R
C
i
n
×
C
out
W_{Q}, W_{K}, W_{V} \in \mathbb{R}^{C_{i n} \times C_{\text {out }}}
WQ,WK,WV∈RCin×Cout 是可学习的。正如公式(1)所示,使用softmax
(
q
T
k
)
(q^Tk)
(qTk)计算的全局亲和度(global affinities)将值
v
v
v聚合起来。因此,与卷积不同,自注意机制能够从整个特征图中捕获非局部信息。然而,计算这样的相似性在计算上是非常昂贵的,并且随着特征图尺寸的增加,对视觉模型体系结构使用自注意通常变得不可行。此外,与卷积层不同,自注意层在计算非局部上下文时不利用任何位置信息。位置信息通常在视觉模型中用于捕捉对象的结构。
其中queries为
q
=
W
Q
x
q=W_Qx
q=WQx,keys为
k
=
W
K
x
k=W_Kx
k=WKx,values为
W
V
x
W_Vx
WVx,这些都是通过对输入
x
x
x计算投影所得。这里,
q
i
j
q_{ij}
qij,
k
i
j
k_{ij}
kij,
v
i
j
v_{ij}
vij分别表示在所有任意位置
i
∈
{
1
,
…
,
H
}
i \in\{1, \ldots, H\}
i∈{1,…,H} and
j
∈
{
1
,
…
,
W
}
j \in\{1, \ldots, W\}
j∈{1,…,W}上的query,key和value。投影矩阵
W
Q
,
W
K
,
W
V
∈
R
C
i
n
×
C
out
W_{Q}, W_{K}, W_{V} \in \mathbb{R}^{C_{i n} \times C_{\text {out }}}
WQ,WK,WV∈RCin×Cout 是可学习的。正如公式(1)所示,使用softmax
(
q
T
k
)
(q^Tk)
(qTk)计算的全局亲和度(global affinities)将值
v
v
v聚合起来。因此,与卷积不同,自注意机制能够从整个特征图中捕获非局部信息。然而,计算这样的相似性在计算上是非常昂贵的,并且随着特征图尺寸的增加,对视觉模型体系结构使用自注意通常变得不可行。此外,与卷积层不同,自注意层在计算非局部上下文时不利用任何位置信息。位置信息通常在视觉模型中用于捕捉对象的结构。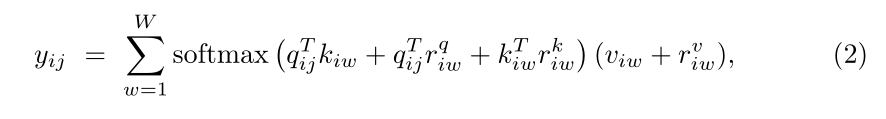 其中
r
q
,
r
k
,
r
v
∈
R
W
×
W
r^{q}, r^{k}, r^{v} \in \mathbb{R}^{W \times W}
rq,rk,rv∈RW×W对应于宽度轴向注意力。
其中
r
q
,
r
k
,
r
v
∈
R
W
×
W
r^{q}, r^{k}, r^{v} \in \mathbb{R}^{W \times W}
rq,rk,rv∈RW×W对应于宽度轴向注意力。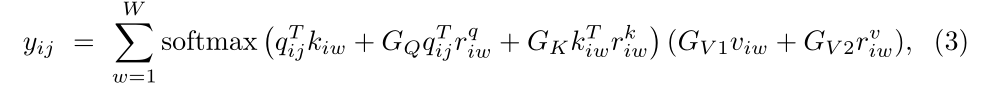 同样地,
G
Q
,
G
K
,
G
V
1
,
G
V
2
∈
R
G_{Q}, G_{K}, G_{V 1}, G_{V 2} \in \mathbb{R}
GQ,GK,GV1,GV2∈R都是可学习的参数,它们一起创建门控机制,控制学习的相对位置编码对编码非局部上下文的影响。具体来说,如果相对位置编码被精确地学习,那么与没有被精确地学习的编码相比,门控机制将赋予它更高的权重。
同样地,
G
Q
,
G
K
,
G
V
1
,
G
V
2
∈
R
G_{Q}, G_{K}, G_{V 1}, G_{V 2} \in \mathbb{R}
GQ,GK,GV1,GV2∈R都是可学习的参数,它们一起创建门控机制,控制学习的相对位置编码对编码非局部上下文的影响。具体来说,如果相对位置编码被精确地学习,那么与没有被精确地学习的编码相比,门控机制将赋予它更高的权重。

【本文地址】
今日新闻 |
推荐新闻 |