基于熵权法的TOPSIS综合评价方法 |
您所在的位置:网站首页 › topsis求权重 › 基于熵权法的TOPSIS综合评价方法 |
基于熵权法的TOPSIS综合评价方法
|
0 前言
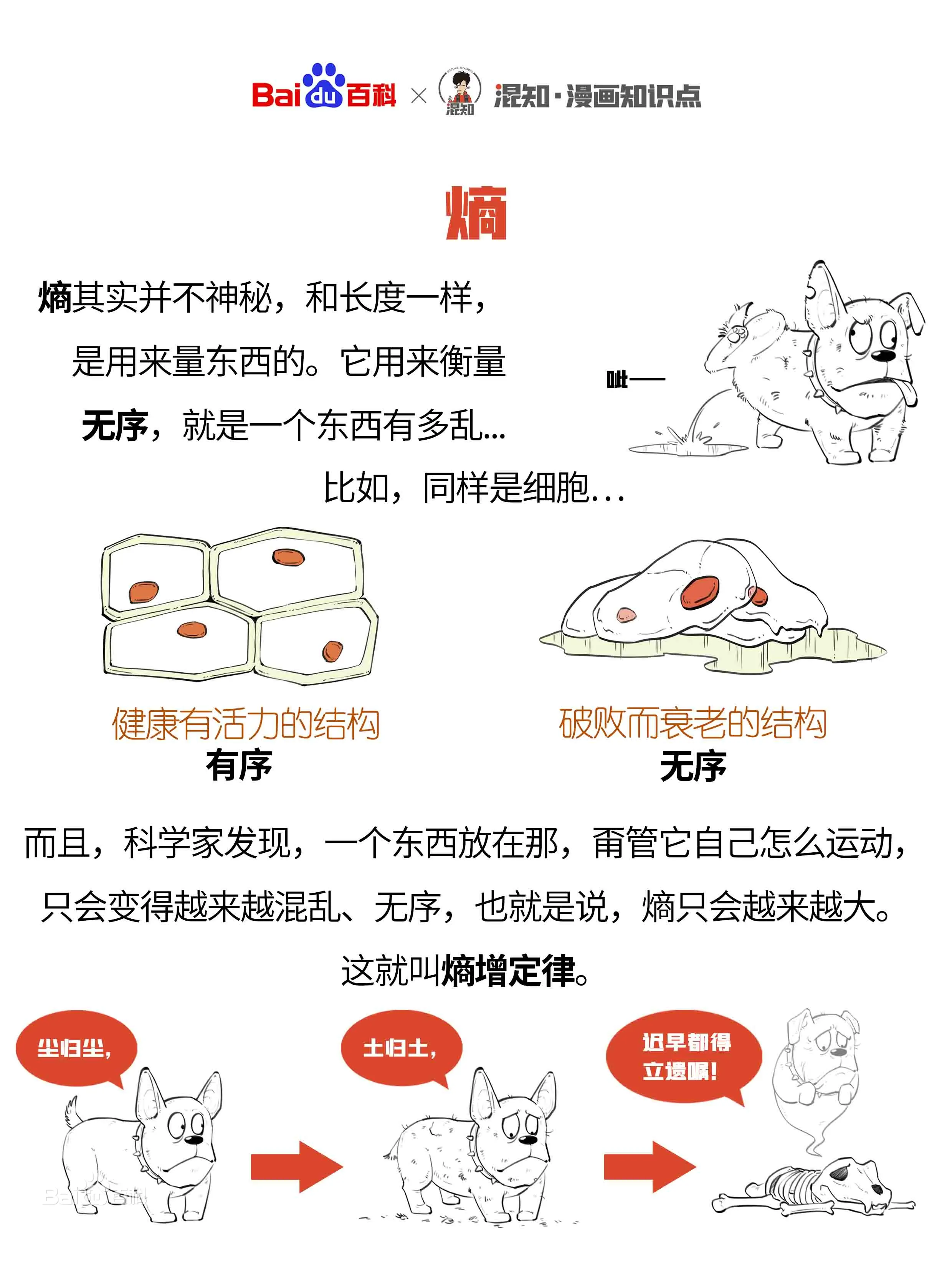
本文主要分享一下几个方面的内容: 熵权法的来源及原理 TOPSIS的原理 为啥这俩哥们可以合体,合体之后有什么奇效? 1 熵权法(EWM-【Entropy Weight Method】) 1.1 熵权法的来源 1.1.1 信息熵的来源 在分享信息熵来源时,我们先来看看 熵的概念。
根据这个公式,我们可以将熵看作是一个系统“混乱程度”的度量,因为一个系统越混乱,可以看作是微观状态分布越均匀。例如,设想有一组\(10\)个硬币,每一个硬币有两面,掷硬币时得到最有规律的状态是\(10\)个都是正面或\(10\)个都是反面,这两种状态都只有一种构型(排列)。反之,如果是最混乱的情况,有5个正面5个反面,排列构型可以有\(C_{10}^5\)排列组合数,共\(252\)种。 玻尔兹曼公式的另一种等价表述形式是$$S=-k_B\sum_ip_i\ln p_i$$ 其中\(i\)标记所有可能的微观态,\(p_i\)表示微观态的出现几率。 1948年,香农将统计物理中熵的概念引申到了信道通信中,从而开创了”信息论“这门学科。香农定义的“熵”又被称为“香农熵”或“信息熵”,即$$S\left(p_1,p_2,\cdots,p_n\right)=-K\sum_{i=1}^np_i\log_2p_i$$其中\(i\)标记概率空间中所有可能的样本,\(p_i\)表示该样本的出现几率,\(K\)是和单位选取相关的任意常数。可以明显看出“信息熵”的定义和“热力学熵”(玻尔兹曼公式)的定义只相差某个比例常数。 1.1.2 信息熵公式的推导下面一个例子让您搞明白信息熵公式为什么这样写。 在分享例子之前,我们首先要接受这样一个设想:即某事情发生的确定性越小,其包含的信息量越大,因为要使该事情发生的确定性变大,我们需要更多的信息去消除这种不确定性。比如现有小王和小红两个人,大家都知道小王动不动就往图书馆跑,小红动不动就TIMI。
期末考试到了,大家都以为小王成绩会很好,小红成绩会很差,但令人意想不到的是小红诚意是班级第一名,而小王成绩也很好。小红的成绩情况是不是包含了很多信息(咦?为啥整天TIMI,确是班级第一,偷摸学习了?作弊了?......),而小王的好成绩大家认为是理所应当的,包含的信息很少。我们知道概率只能在\(0\)到\(1\)之间,也就是说,最好在概率为\(1\)的时候,信息量为\(0\),且概率越小,信息量越大。后来人们发现,对数函数很符合这样的规律,某个事件的信息量与概率的关系是 \(i=\log(\frac{1}{p})\),这里的对数是以\(2\)为底的,\(p\)是事件发生的概率。
我们可以把\(\frac{1}{p}\)看成等可能信息数量,虽然我们遇到的更多情况是事件发生的可能性不一样的系统。实际上,我们总是可以把一个事件的概率值转换为一个等可能事件系统中发生某个事件的概率。举例来说,我们总是可以把一个概率值转换为“在N个球中随机摸一个球”这个等可能事件系统中摸出某个球的概率。
假设中彩票大奖的概率很低,只有两千万分之一,我们可以把这个概率值转换为在两千万个球中摸出中奖球的概率。在这个摸球系统中,就有两千万个等可能事件。说白了就是信息数量就是总可能数,也就是概率值的倒数,即 \(N = \frac{1}{p}\) 。
再举一个例子,假设我们有一个动了手脚的不均匀硬币,它正面朝上的概率是0.8,反面朝上的概率是0.2。
反面朝上0.2的概率可以想象有5个球的摸球系统中摸出某个球的概率。
而正面朝上0.8的概率可以想象成在有1.25个球的系统中摸出某个球的概率。
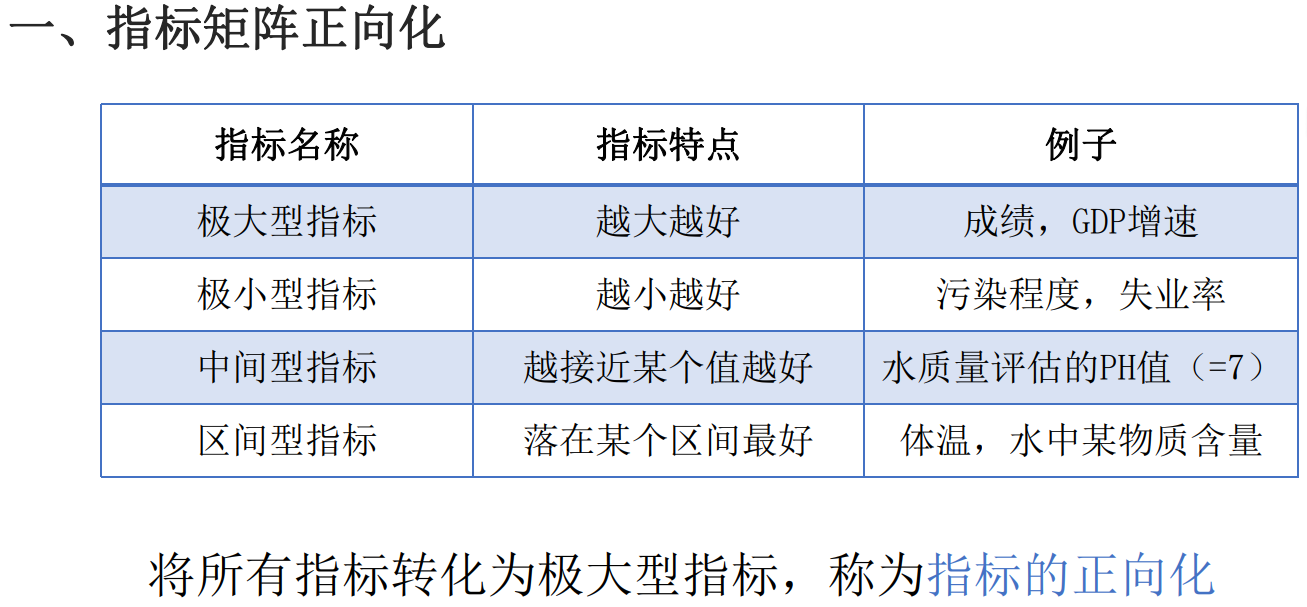
我们通过想象把一个非等概率事件的系统拆成了两个等概率事件的系统。而面对等概率事件系统,我们就可以很容易地计算它们的信息量。再把这两个想象出来的摸球系统的信息量加起来,就是这个不均匀硬币的信息量:\(\log5+\log1.25\),由于这两个我们想象出来的等概率系统本身出现的概率也不一样,因此我们需要分别乘上它们出现的概率,得\(0.2\cdot\log5+0.8\cdot\log1.25\)。 如果我们用符号去抽象这些具体的值,就是$$p_1\cdot\log\frac1{p_1}+p_2\cdot\log\frac1{p_2}\quad(1)$$ 对于有更多事件的一般情况,我们可以这么表示:$$\sum_ip_i\log\frac1{p_i}\quad\quad(2)$$ 整理后就是这个样子: \[\begin{aligned} \sum p_i\log\frac1{p_i}& =\sum_i(p_i\cdot\log p_i^{-1}) \\ &=\sum_i-p_i\log p_i\quad(3) \\ &=-\sum_ip_i\log p_i \end{aligned} \] 最后就得到了香农所提出的信息熵公式:\(-\sum_ip_i\log p_i\) 。我们可以看出,信息熵实际上就是我们给每个概率值想象出来的某个系统的信息量的平均值(平均信息量),或者说是信息量的期望。相信有些眼力超群的读者看出此公式少了个系数\(K\),其实系数\(K = \frac{1}{\log{n}}\),为什么要系数\(K\)非要是它呢?根据琴生不等式可以得出,当 \(p_1 = p_2 = ... = p_n = \frac{1}{n}\) 时,公式 \(-\sum_ip_i\log p_i\) 取得最大值 \(\log{n}\) 。所以乘以系数 \(K\) 其实就是把计算结果控制在区间 [0 , 1] 之间,或者叫它标准熵。 我觉得这位大佬讲得很好,可以结合着看看。—> 信息熵的前世今生 1.2 熵权法的原理如何利用信息熵的概念求出各个指标的权重呢? 一般来说,若某个指标的信息熵越小,表明指标值得变异程度越大,提供的信息量越多,在综合评价中所能起到的作用也越大,其权重也就越大。相反,某个指标的信息熵越大,表明指标值得变异程度越小,提供的信息量也越少,在综合评价中所起到的作用也越小,其权重也就越小。那基于此我们就可以根据信息熵计算各个指标的权重了。 1.2.1 指标正向化
假设有 \(n\) 个要评价的对象,\(m\) 个评价指标(已经正向化了)构成的正向化矩阵如下: \[X=\begin{bmatrix} x_{11}&x_{12}&...&x_{1m}\\ x_{21}&x_{22}&...&x_{2m}\\ \vdots&\vdots&\ddots&\vdots\\ x_{n1}&x_{n2}&...&x_{nm} \end{bmatrix} \]那么,对其标准化的矩阵记为 \(Z\) ,\(Z\) 中的每一个元素: \(Z_{ij}=x_{ij}/\sqrt{\sum_{i=1}^nx_{ij}^2}\) 判断 \(Z\) 矩阵中是否存在着负数,如果存在,需要对 \(X\) 使用另一种标准化方法。 对矩阵 \(X\) 进行一次标准化得到 \(\widetilde{Z}\) 矩阵,其标准化的公式为: \[\tilde{z}_{ij}=\frac{x_{ij}-min\{x_{1j},x_{2j},\cdot\cdot\cdot,x_{nj}\}}{\max\{x_{1j},x_{2j},\cdot\cdot\cdot,x_{nj}\}-min\{x_{1j},x_{2j},\cdot\cdot\cdot,x_{nj}\}} \]1.2.3 计算每个元素所占比重(将其看作信息熵里的概率p(x))假设有 \(n\) 个要评价的对象,\(m\) 个评价指标,且经过了上一步处理得到的非负矩阵为: \[\widetilde{Z}=\begin{bmatrix}\widetilde{z}_{11}&\widetilde{z}_{12}&...&\widetilde{z}_{1m}\\\widetilde{z}_{21}&\widetilde{z}_{22}&...&\widetilde{z}_{2m}\\\vdots&&\ddots&\vdots\\\widetilde{z}_{n1}&\widetilde{z}_{n2}&...&\widetilde{z}_{nm}\end{bmatrix} \]我们计算概率矩阵 \(P\), 其中 \(P\) 中的每一个元素 \(P_{ij}\) 的计算公式如下: \[p_{ij}=\frac{\tilde{z}_{ij}}{\sqrt{\sum_{i=1}^n\tilde{z}_{ij}}} \]容易验证:\(\sum_{i=1}^np_{ij}=1\) ,即保证了每一个指标所对应的概率和为 \(1\) 。 1.2.4 计算每个指标的信息熵e,并求出权重 法一: 通过计算信息冗余度来计算权重对于第 \(j\) 个指标而言。其信息熵计算公式为: \[e_j=-\frac1{lnn}\sum_{i=1}^np_{ij}ln(p_{ij})\quad\quad(j=1,2,\cdots,m) \]信息冗余度: \[d_i=1-e_i \]将信息冗余度归一化,得到每个指标的熵权: \[W_j=\frac{d_j}{\sum_{j=1}^md_j}\quad\quad(j=1,2,\cdots,m) \] 法二: 通过计算信息熵直接计算权重 这里k指的是指标个数,即k=m。 \[w_j=\frac{1-e_j}{k-\Sigma e_j}(\mathfrak{j}=1,2,\ldots,m) \]其实,两种方式本质上是一样的 1.2.5 最后计算每个方案的综合评分 \[s_i=\sum_{j=1}^mw_j\cdot p_{ij} \]以上就是熵权法的原理了🌞。 2 TOPSIS的原理(逼近理想解,也叫优劣解距离法)前面的预处理阶段与熵权法一样,不一样的地方从数据标准化后的部分开始 经过了正向化处理和标准化处理的评分矩阵Z,里面的数据全部是极大型数据。我们就可以从中取出理想最优解和最劣解。因此我们取出每个指标,即每一列中最大的数,构成理想最优解向量,即 \[z^{+}=\left[\begin{array}{c}z_{1}^{+},z_{2}^{+},\ldots,z_{n}^{+}\\\end{array}\right]=\left[\max\left\{z_{11},z_{21},\ldots,z_{n1}\right\},\max\left\{z_{12},z_{22},\ldots,z_{n2}\right\},\ldots,\max\left\{z_{1m},z_{2m},\ldots,z_{mn}\right\}\right] \]同理,取每一列中最小的数计算理想最劣解向量: \[z^-=\left[z_1^-,z_2^-,\ldots,z_m^-\right]=\left[\min\left\{z_{11},z_{21},\ldots,z_{n1}\right\},\min\left\{z_{12},z_{22},\ldots,z_{n2}\right\},\ldots,\min\left\{z_{1m},z_{2m},\ldots,z_{m}\right\}\right] \]其中 \(z^+就是z_{max},z^-就是z_{min}\) 。 定义第 $i(i = 1,2,…,n) $个评价对象与最大值的距离: \[D_i^+=\sqrt{\sum_{j=1}^m(Z_j^+-z_{ij})^2} \]定义第 $i(i = 1,2,…,n) $个评价对象与最小值的距离 : \[D_i^-=\sqrt{\sum_{j=1}^m(Z_j^--z_{ij})^2} \]那么,我们可以计算得出第 \(i( i = 1,2,…,n)\)个评价对象未归一化的得分: \[S_i=\frac{D_i^-}{D_i^++D_i^-} \]很明显 \(0≤Si≤1\),且 \(Si\) 越大 \(Di+\) 越小,即越接近最大值。 以上就是TOPSIS方法的原理了。 3 为啥这俩哥们可以合体,合体之后有什么奇效?我们可以回想一下TOPSIS的原理,先求出正负理想解,然后计算每个评价对象与正负理想解的欧式距离(也就是差的平方和,然后开根号),TOPSIS在计算每个评价指标的时候,似乎没有考虑每个指标的重要程度,即默认了每个指标的重要程度是相等的,这显然是不太合理的,所以在此我们就可以进行优化。也就是和熵权法求权重的那一步合体。
有了各个指标的重要程度,就可以得出一个更加合理的评价模型。因为熵权法是基于原始数据计算各个指标的权重的,客观性很强。 模型总结Topsis优劣解距离法模型是一种常用的综合评价方法,能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。相对于层次分析法而言,Topsis法是解决决策层中数据已知的评价类模型。它可以解决多数据量的题目,数据计算简单易行。但对于各数据量之间的关系,我们需要使用熵权法或层次分析法来建立权重。 熵权法的原理是指标的变异程度越小,所反映的信息量也越少,其对应的权值也应该越低。因此数据本身就告诉了我们权重。所以说熵权法是一种客观的方法。但就如评价三好学生的例子,只有学习成绩与违纪次数去评价一个学生,使用了熵权法之后,反而违纪次数的权重近于0,显然不符合常理。因此使用此方法后我们需要人工干预,判断一下权重是否合理(如2021年国赛C283论文)。综合来说,在比赛中,对于决策层中数据已知的问题,使用Topsis模型十分合适 解题步骤: 熵权法确定权重 1.1 数据标准化 1.2 求出各指标的信息熵 1.3 计算各指标的差异系数 1.4 确定各指标的权重 1.5 分别用权重乘以归一化后的数据 将原始矩阵正向化 (变为极大型指标) 正向化矩阵标准化 确定最优方案和最劣方案 计算各评价对象与最优方案、最劣方案的接近程度 计算各评价对象与最优方案的贴近程度 根据贴近程度大小进行排序,给出评价结果、 优点: 避免了数据的主观性,不用通过检验,能够很好的刻画多个影响指标的综合影响力度 评估程序简单,计算过程简单易懂。 对于数据分布及样本量、指标多少无严格限制,既适于小样本资料,也适于多评价单元、多指标的大系统,较为灵活、方便 缺点: 必须有两个以上的研究对象才可以进行使用 需要的每个指标的数据,对应的权重计算会有一定难度 不确定指标的选取个数为多少适宜,才能够很好刻画指标的影响力度以上便是笔者分享的关于熵权法和TOPSIS合体的所有内容了,这是笔者在学习时的一些记录,通过写出来加深对知识的理解程度,希望笔者的分享能够帮助到您,感谢您的观看!❤️ 参考https://blog.csdn.net/weixin_57449924/article/details/123850208 https://blog.51cto.com/greyfoss/5469200 |




【本文地址】
今日新闻 |
推荐新闻 |