决策树② |
您所在的位置:网站首页 › titanick2怎么样 › 决策树② |
决策树②
|
决策树系列目录(文末有大礼相送): 决策树①——信息熵&信息增益&基尼系数 决策树②——决策树算法原理(ID3,C4.5,CART) 决策树③——决策树参数介绍(分类和回归) 决策树④——决策树Sklearn调参(GridSearchCV) 决策树⑤——Python代码实现决策树 决策树应用实例①——泰坦尼克号分类 决策树应用实例②——用户流失预测模型 决策树应用实例③——银行借贷模型 决策树应用实例④——淘宝&京东白条(回归&均方差&随机森林) 决策树是一种运用统计概率分析的机器学习方法。它表示对象属性和对象值之间的一种映射,树中的每一个节点表示对象属性的判断条件,其分支表示符合节点条件的对象。树的叶子节点表示对象所属的预测结果,主要有ID3,C4.5和CART三种基础决策树 一、ID3算法1、算法原理 ID3是采用信息增益作为特征选择的标准,信息增益上一篇博客有介绍,公式如下: 2、算法过程 ① 计算训练集所有样本的信息熵 ② 计算按每一特征分类后的信息增益 ③ 选择信息增益最大的特征进行分类,得到子节点 ④ 在还未被选择的特征中迭代②和③,直到无特征可分或信息增益已经无法达到要求的标准时,算法终止 二、C4.5算法1、算法原理 ID3算法有2大缺点:1是类别越多的特征计算出的信息增益越大,易导致生成的决策树广而浅;2是只能处理离散变量,不能处理连续变量。 C4.5是在ID3的算法基础上,采用信息增益率来做为特征选择,通过增加类别的惩罚因子,规避了类别越多信息增益越大的问题,同时也可以对连续变量通过均值离散化的方式,解决无法处理连续变量的问题。 信息增益率的公式上一篇博客有介绍: 1、原理 C4.5虽然解决了ID3的两大问题,但是仍有自己的缺憾,那就是不能处理回归问题,CART因此诞生。 CART不再通过信息熵的方式选取最优划分特征,而是采用基尼系数,也叫基尼不纯度,两者衡量信息量的作用相当,但是基尼系数由于没有对数运算,可大大减少计算开销。 公式如下: 2、算法过程 ① 计算训练集所有样本的基尼系数 ② 计算某一特征下每一属性划分后左右两边的基尼系数,找到基尼系数和最小的划分属性 ③ 将每一个特征均按②中的方法计算,得到每一个特征最佳的划分属性 ④ 对比③中每一个特征的最优划分属性下的基尼系数和,最小的就是最优的划分特征 ⑤ 按最优的特征及最优属性划分,得到子节点 ⑥ 在还未被选择的特征中迭代②-⑤,直到无特征可分或信息增益率已经无法达到要求的标准时,算法终止 四、决策树应用场景可以用于二元或多元分类,以及回归,下面是我想到的一些业务场景: ① 判断什么样的用户流失概率最高 ② 根据用户的消费属性,判断是否可以打白条,以及白条金额上限设定 ③ 如何预测未来一段时间内,哪些顾客会流失,哪些顾客最有可能成为VIP客户 ④ 如何根据用户的历史相亲情况,匹配最佳相亲对象等 …… 本人互联网数据分析师,目前已出Excel,SQL,Pandas,Matplotlib,Seaborn,机器学习,统计学,个性推荐,关联算法,工作总结系列。 微信搜索并关注 " 数据小斑马" 公众号,回复“机器学习”就可以免费领取下方机器学习—周志华、统计学习方法-李航等9本经典书籍 |
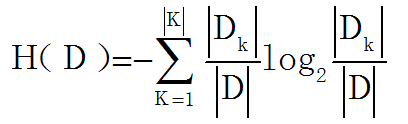
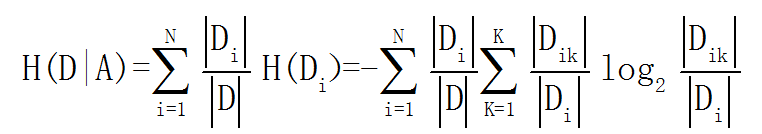
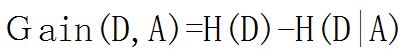 信息增益越大,说明此按此特征分类后越能消除信息的不确定性。
信息增益越大,说明此按此特征分类后越能消除信息的不确定性。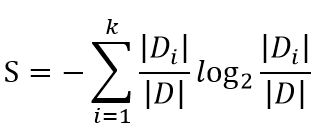
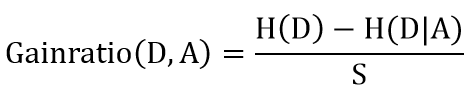 2、算法过程 ① 计算训练集所有样本的信息熵 ② 计算按每一特征分类后的信息增益率 ③ 选择信息增益率最大的特征进行分类,得到子节点 ④ 在还未被选择的特征中迭代②和③,直到无特征可分或信息增益率已经无法达到要求的标准时,算法终止
2、算法过程 ① 计算训练集所有样本的信息熵 ② 计算按每一特征分类后的信息增益率 ③ 选择信息增益率最大的特征进行分类,得到子节点 ④ 在还未被选择的特征中迭代②和③,直到无特征可分或信息增益率已经无法达到要求的标准时,算法终止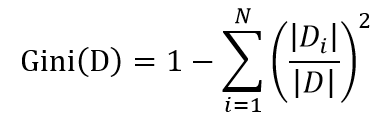
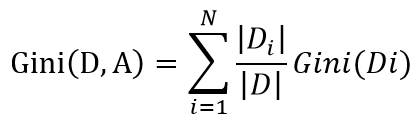 CART算法处理分类问题时,以叶子节点上样本投票预测类别,处理回归问题时,以叶子节点的样本均值作为预测值
CART算法处理分类问题时,以叶子节点上样本投票预测类别,处理回归问题时,以叶子节点的样本均值作为预测值
【本文地址】
今日新闻 |
推荐新闻 |