谷歌云TensorFlow性价比测试:CPU比GPU表现更好 |
您所在的位置:网站首页 › tensorflow安装cpu还是gpu › 谷歌云TensorFlow性价比测试:CPU比GPU表现更好 |
谷歌云TensorFlow性价比测试:CPU比GPU表现更好
|
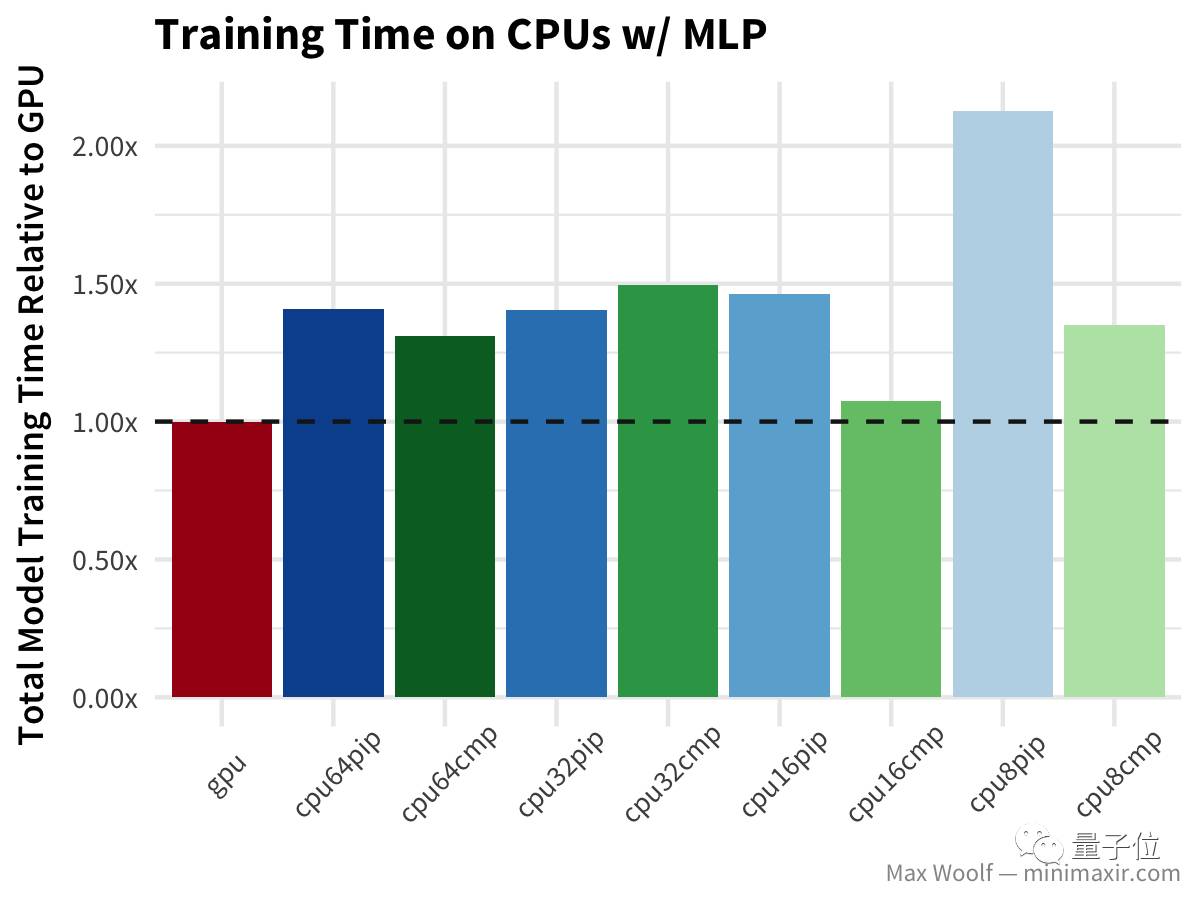
为了解决这些警告,并对SSE4.2/AVX/FMA进行优化,我们从源代码编译了TensorFlow,并创建了第三个Docker容器。在新容器中训练模型时,大多数警告都不再出现,而且确实提高了训练速度。 这样,我们就可以使用Google Cloud Engine开始测试三大案例: 一个Tesla K80 GPU实例 一个64 Skylake vCPU实例,其中TensorFlow通过pip安装,以及8/16/32个vCPU的测试 一个65 Skylake vCPU实例,其中TensorFlow使用CPU指令编译(cmp),以及8/16/32个vCPU的测试 一个Tesla K80 GPU实例 一个64 Skylake vCPU实例,其中TensorFlow通过pip安装,以及8/16/32个vCPU的测试 一个65 Skylake vCPU实例,其中TensorFlow使用CPU指令编译(cmp),以及8/16/32个vCPU的测试 对于每个模型架构和软/硬件配置,下面的结论都使用GPU实例训练时间作为基准进行对比换算,因为在所有的情况下,GPU应该是训练速度最快的方案。 让我们从MNIST手写数字数据集+通用的多层感知器(MLP)架构 开始,使用密集的全连接层。训练时间越少越好。水平虚线是GPU的成绩,虚线以上代表比GPU表现更差。
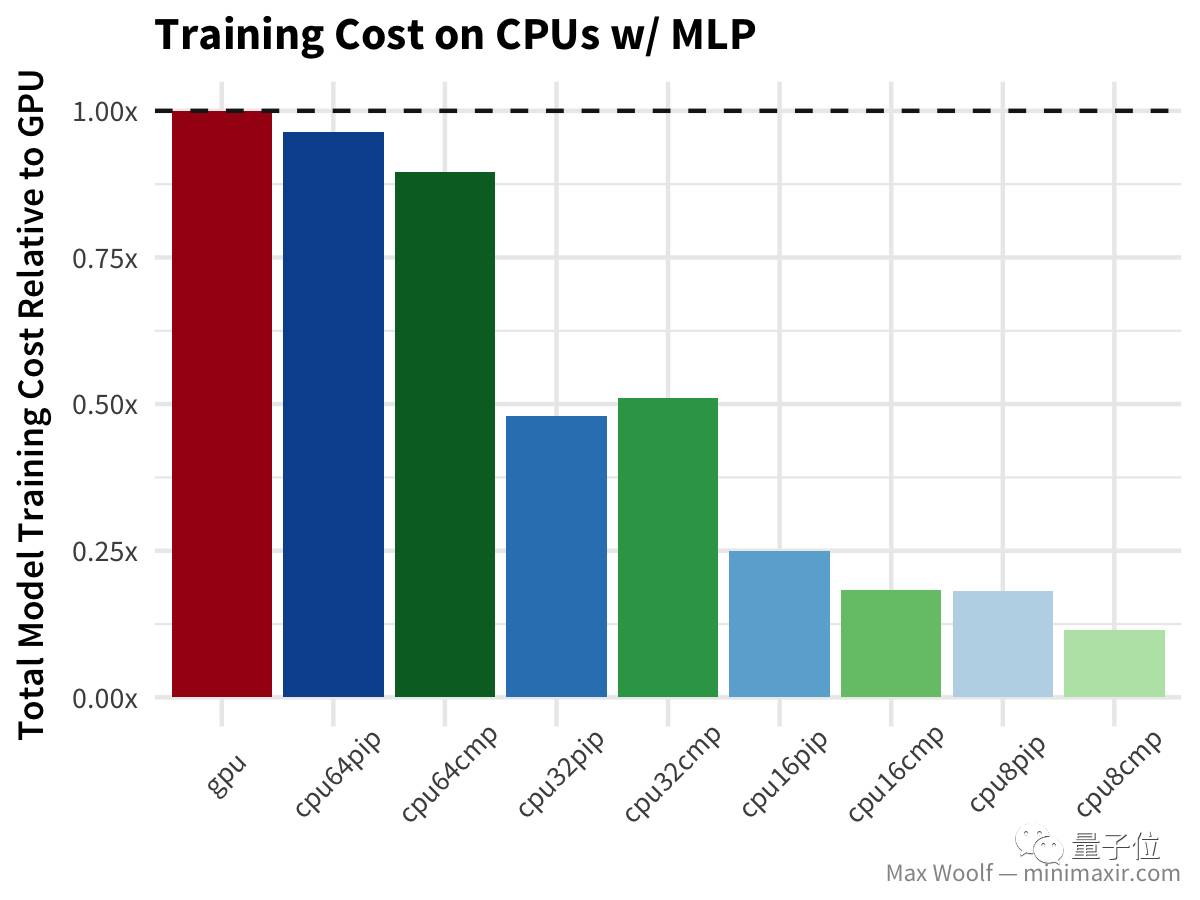
在这个环节的测试中,GPU是所有平台配置中最快的。除此之外我发现,32个vCPU和64个vCPU之间的性能非常相似,编译的TensorFlow库确实能大幅提高训练速度,但只变现在8和16个vCPU的情况下。也许vCPU之间协调沟通的开销,抵消了更多vCPU的性能优势;也许是这些开销与编译TensorFlow的CPU指令不同。 由于不同vCPU数量的训练速度之间差异很小,因此可以肯定缩减数量能带来成本优势。因为GCE实例的成本是按照比例分摊的(这与亚马逊EC2不同),所以可以更简单的计算成本。
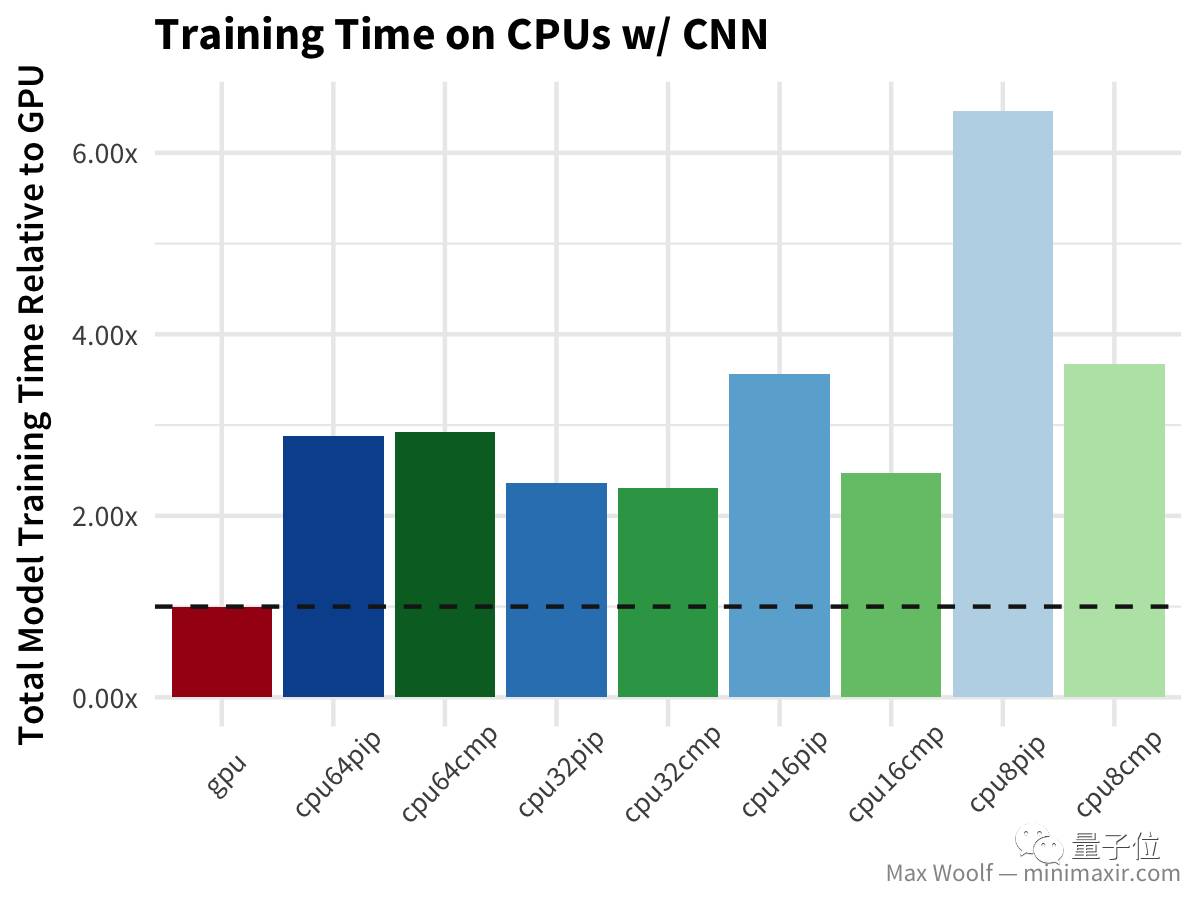
如上图所示,降低CPU数量对这个问题来说成本效益更高。 接着,我们使用相同的数据集,用卷积神经网络(CNN) 进行数字分类:
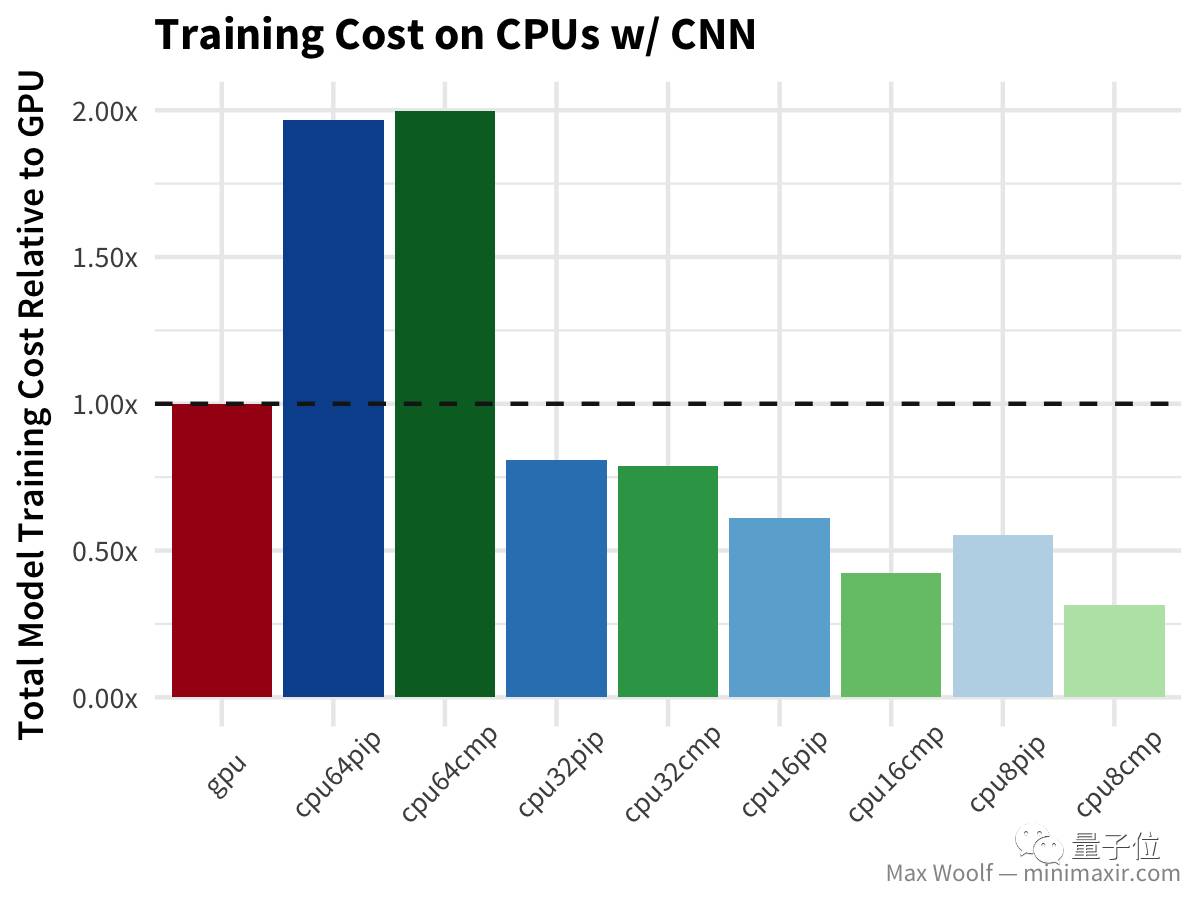
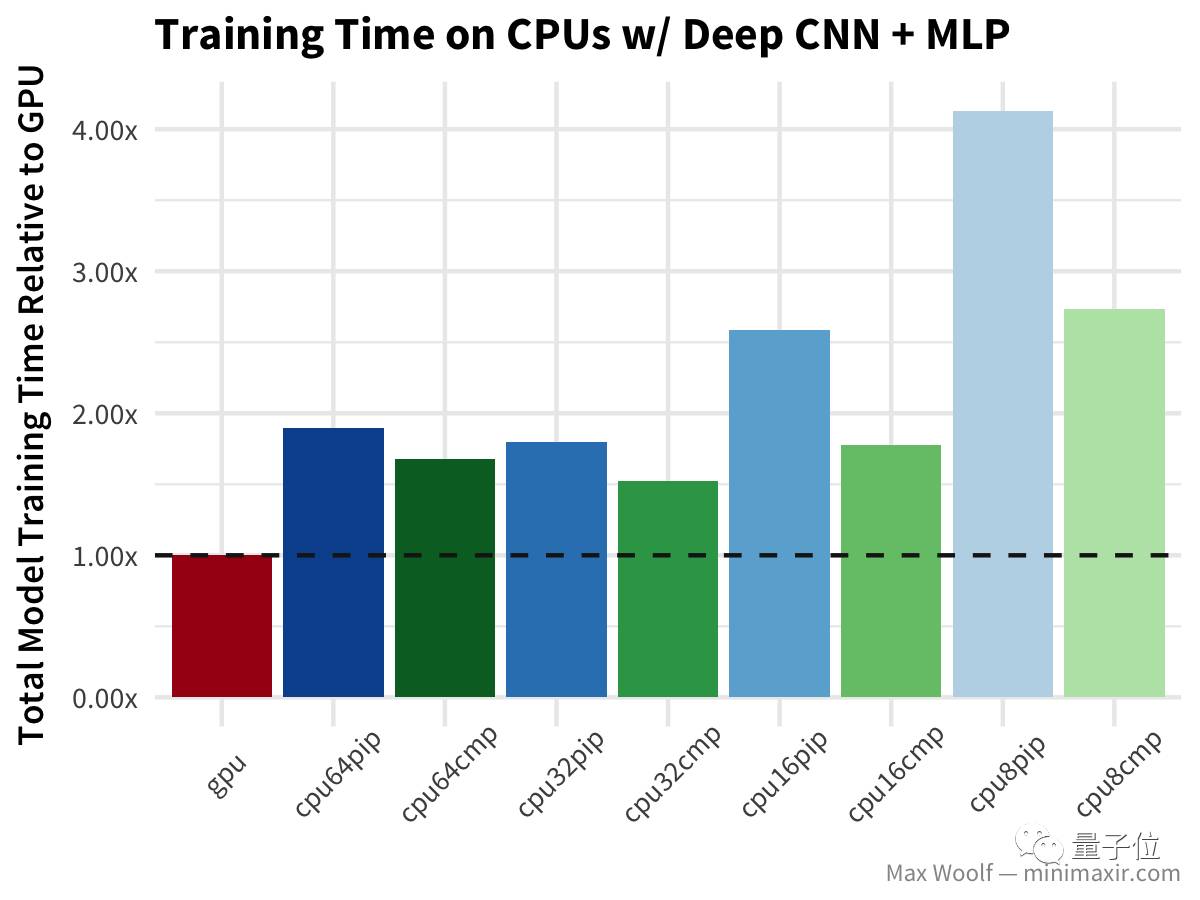
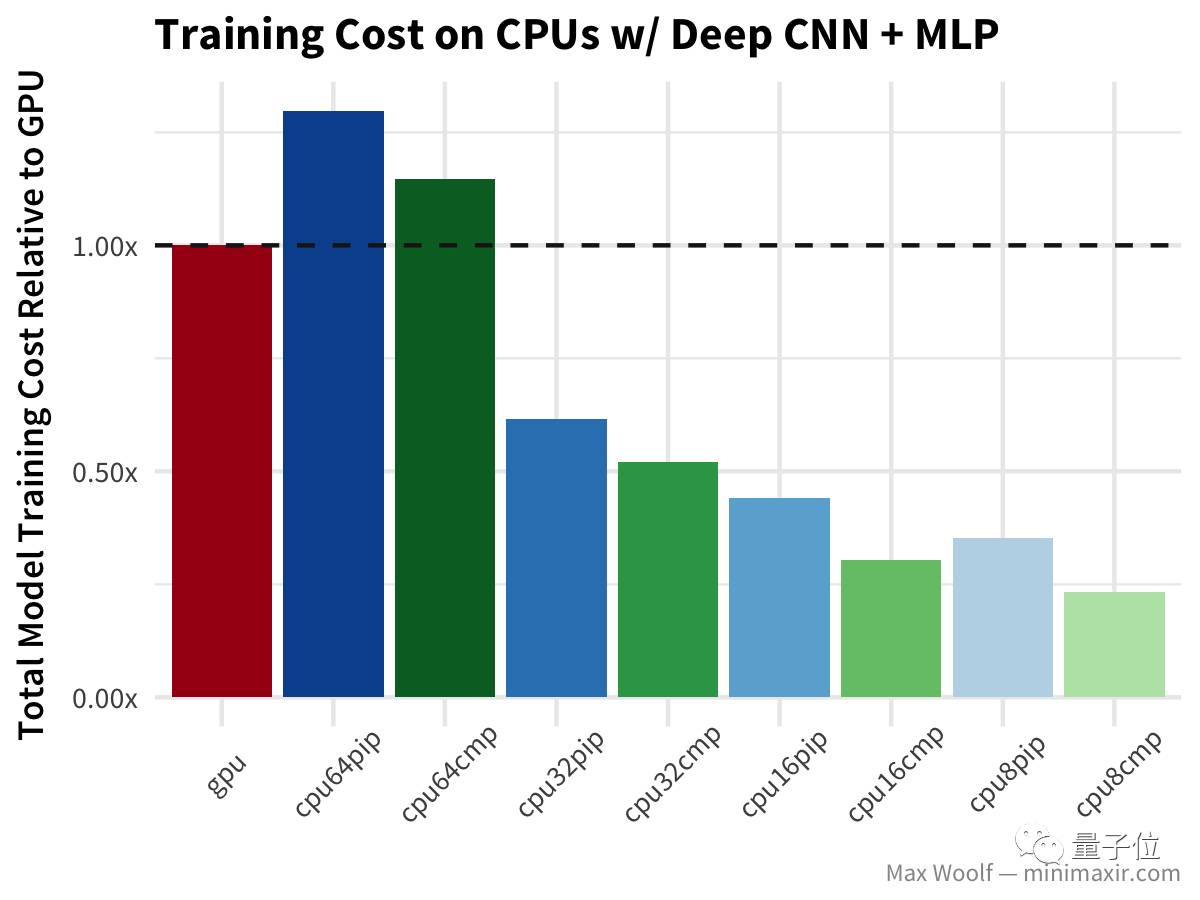
在CNN中,GPU的速度是CPU的两倍以上,而且从成本效率上看,64个vCPU甚至高于GPU,而且64个vCPU的训练时间比32个vCPU还长。 继续,我们在CNN方向上更深一步,基于CIFAR-10图像分类数据集,使用一个使用深度covnet+多层感知器 构建图像分类器模型(类似于VGG-16架构)。
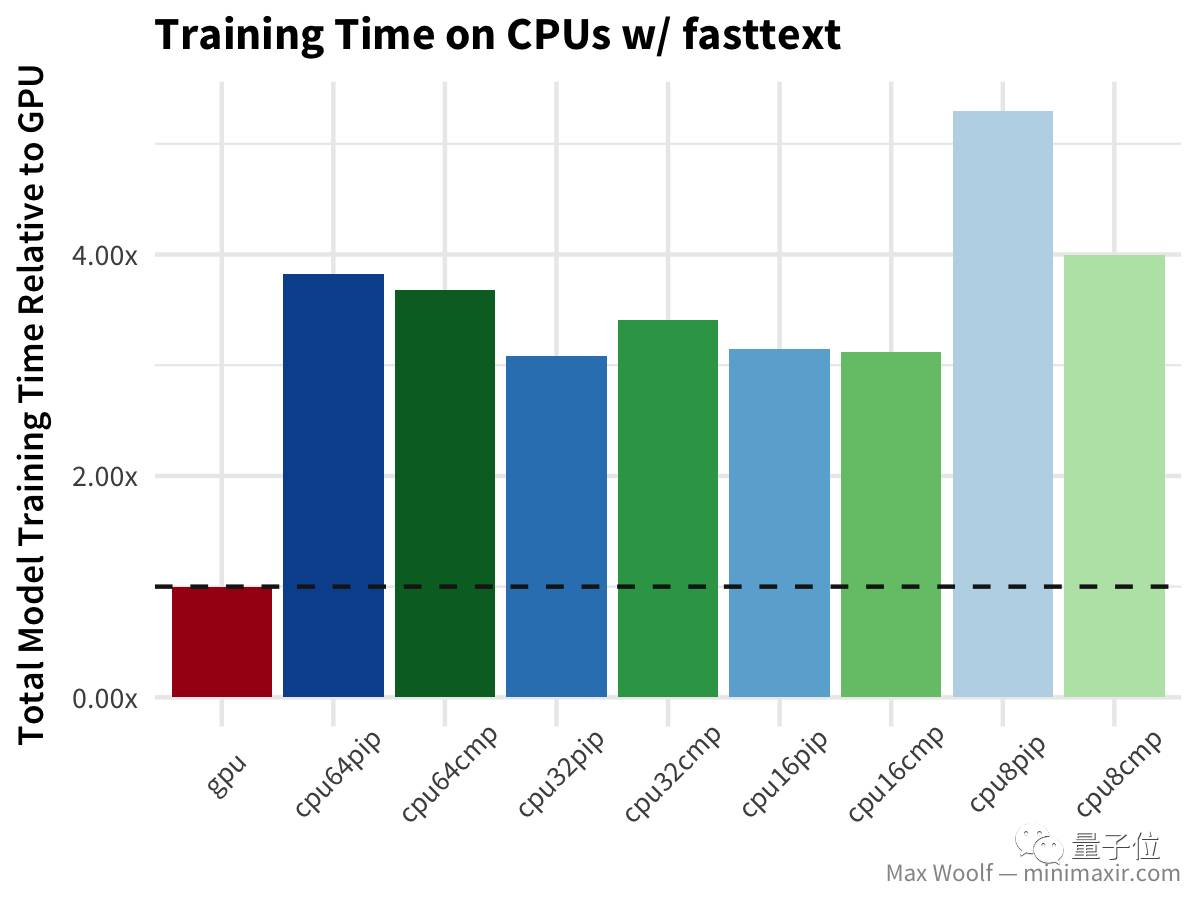
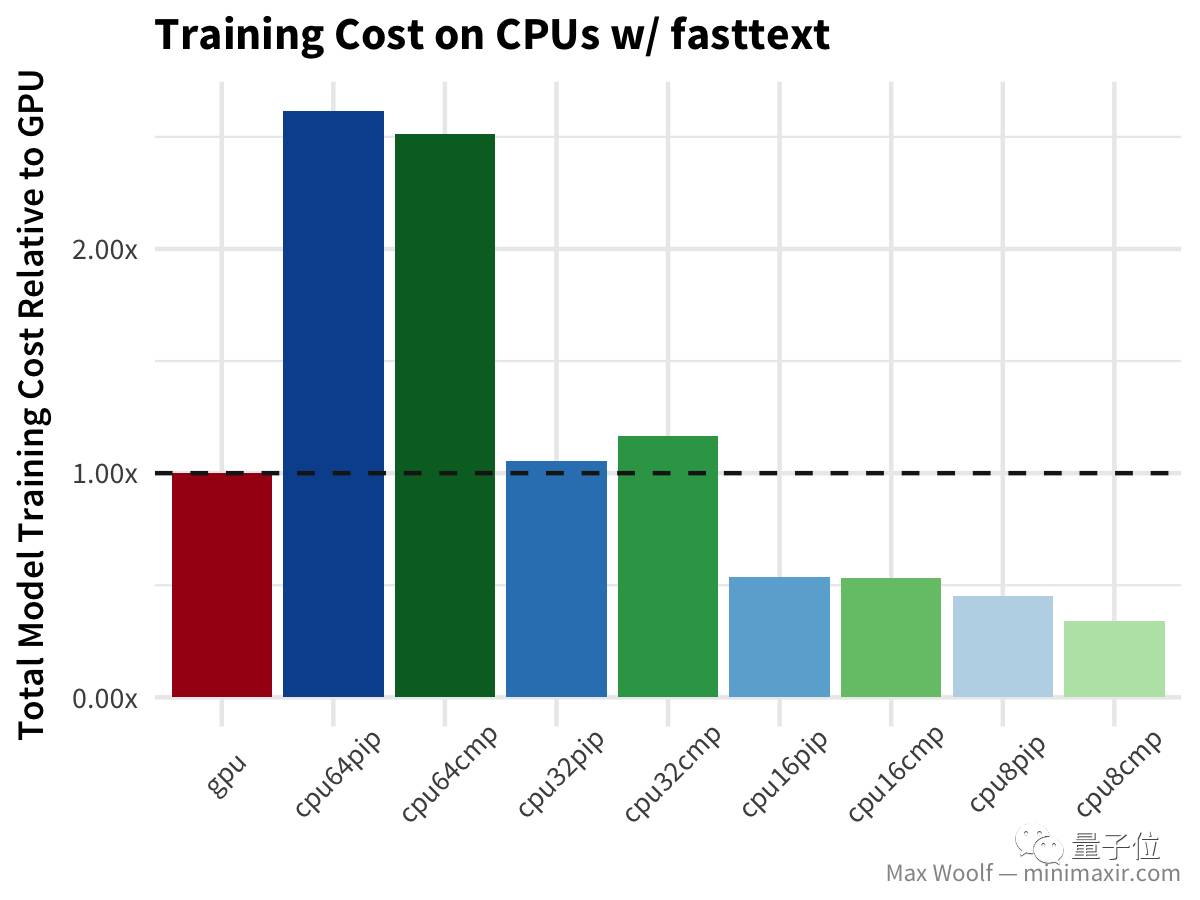
与简单CNN测试的情况类似,不过在这种情况下,所有使用已编译TensorFlow库的CPU都表现更好。 接下来是fasttext算法,用来在IMDb的评论数据库中分辨评论是正面还是负面,在文本分类领域比其他方法都快。
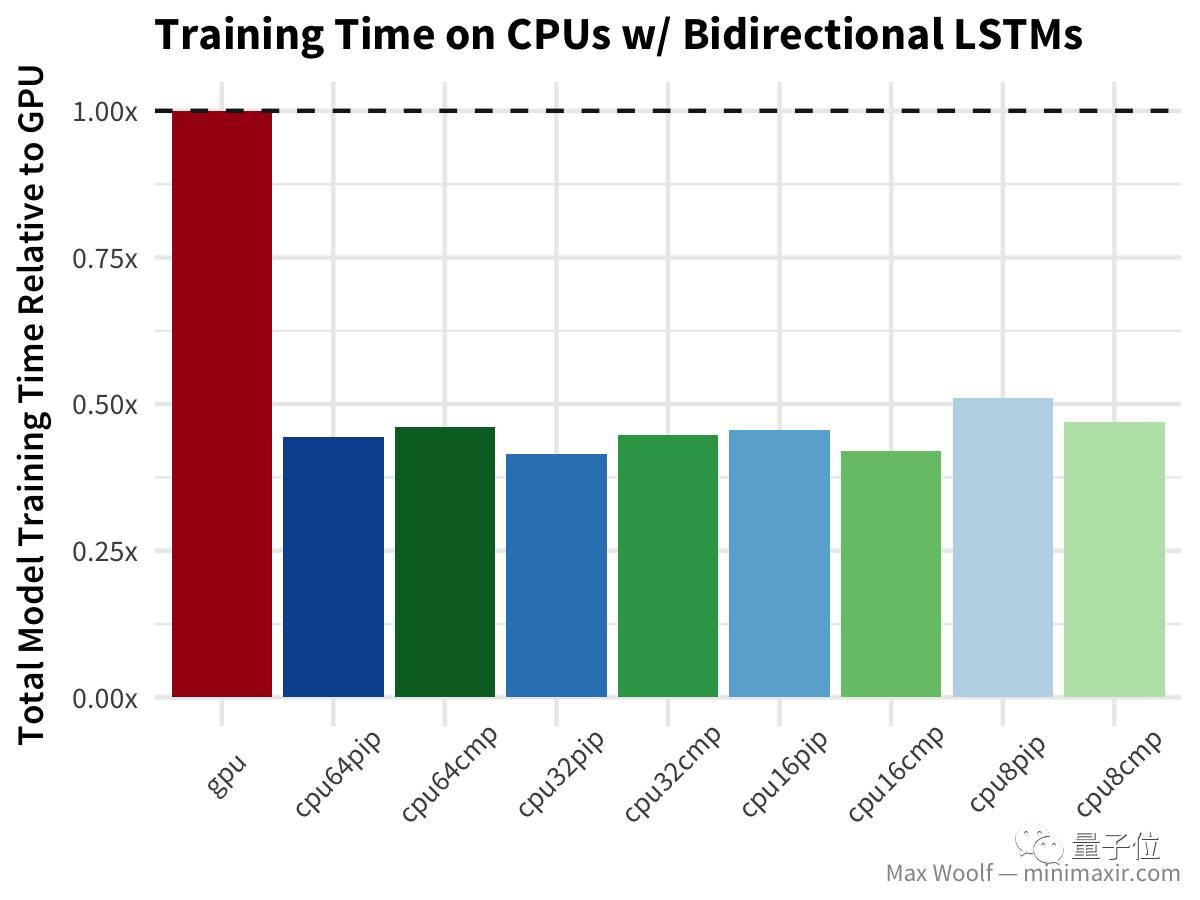
在这个环节中,GPU比CPU快得多。数量较少的CPU配置,没带来太大的优势,要知道正式的fasttext实现视为大量使用CPU设计的,并且能够很好的进行并行处理。 双向长短期记忆(LSTM)架构 对于处理诸如IMDb评论之类的文本数据非常有用,但是在我之前的测试文章里,有Hacker News的评论指出,TensorFlow在GPU上使用了LSTM的低效实现,所以也许差异将会更加显著。
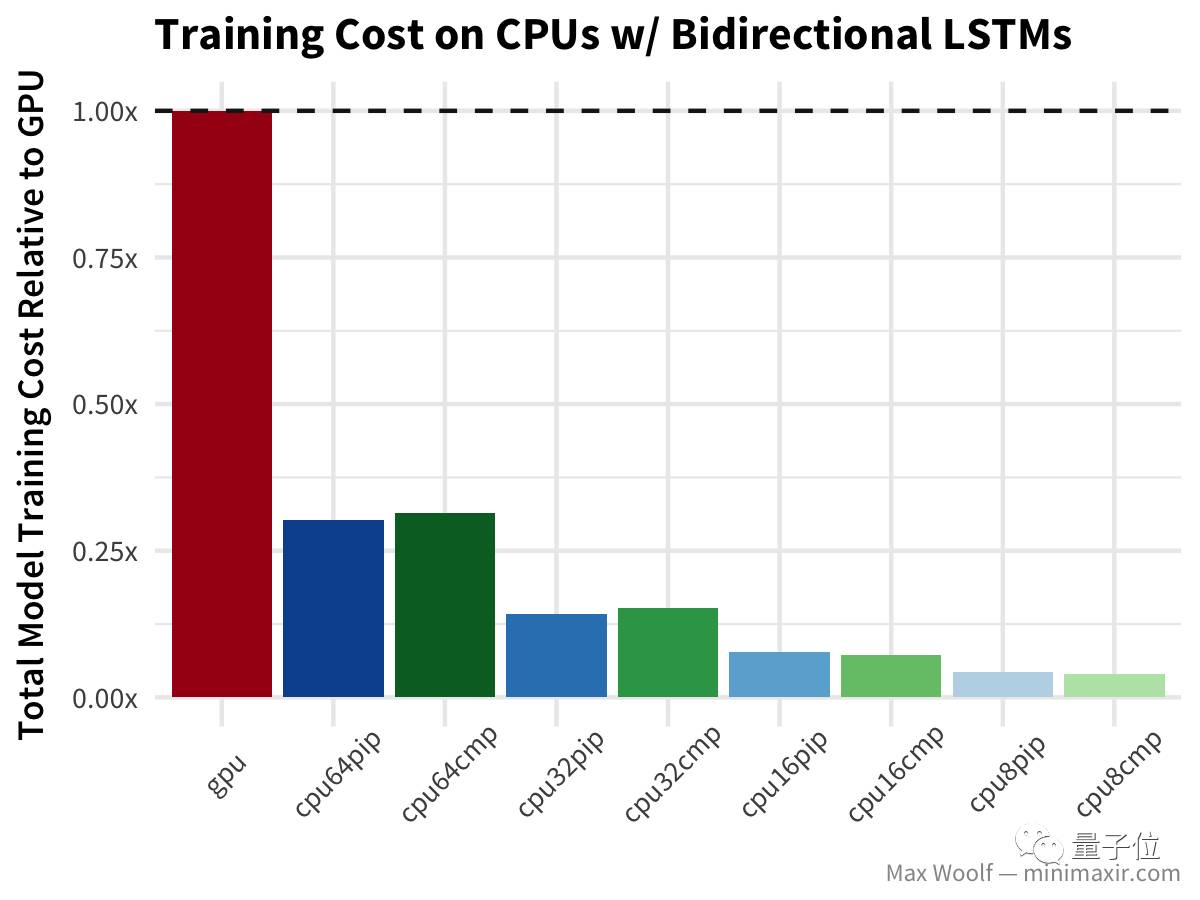
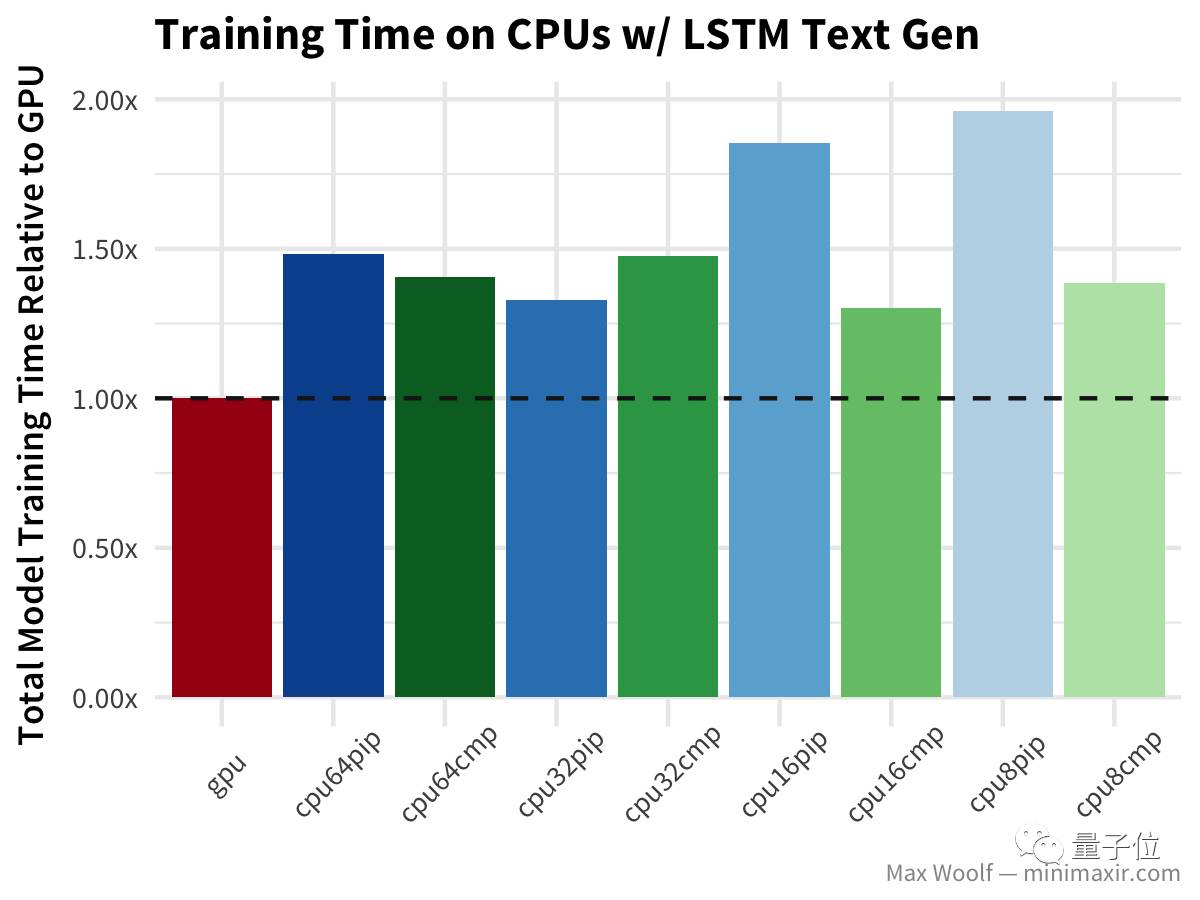
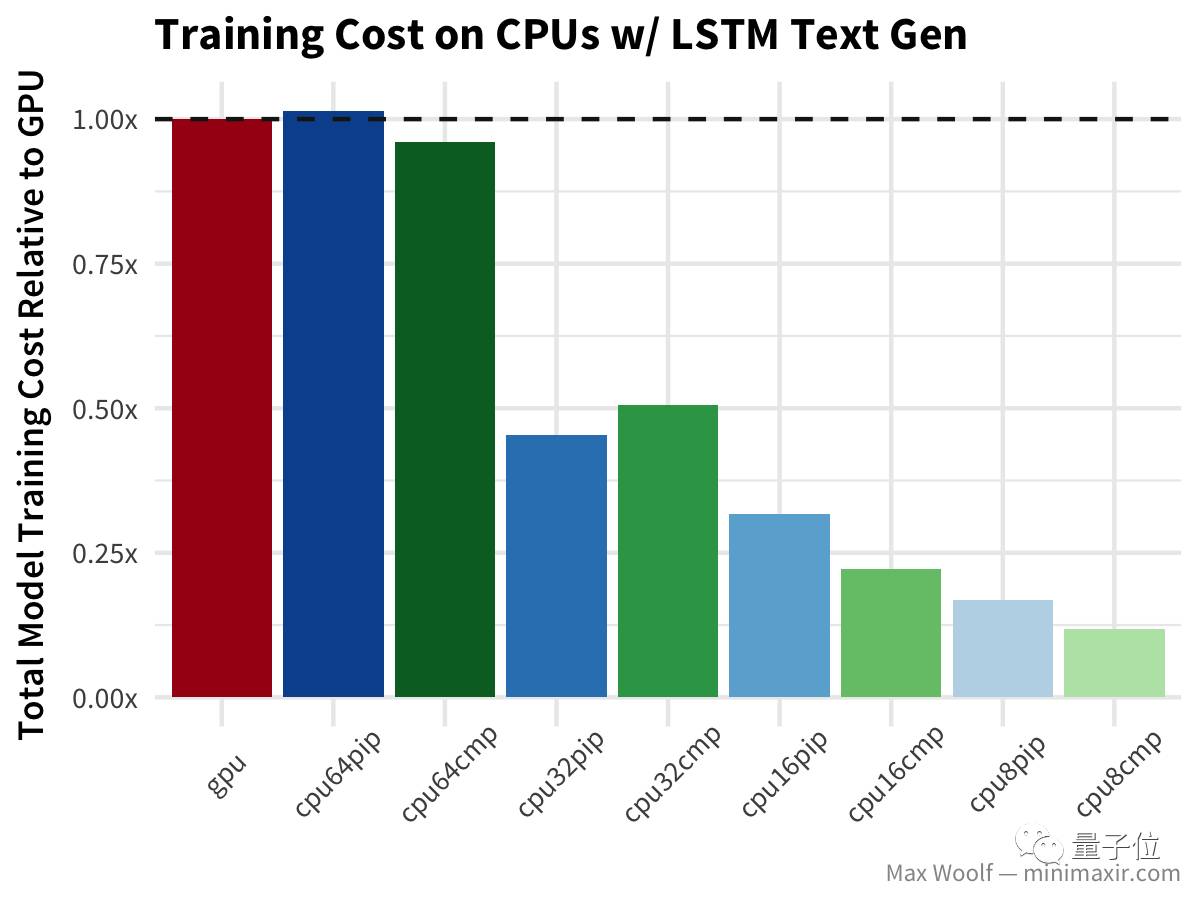
等等,什么?双向LSTM的GPU训练比任何CPU配置都慢两倍以上?哇哦(公平地说,基准测试使用Keras LSTM默认的implementation=0,这对CPU更好;而在GPU上使用implementation=2更好,但不应该导致这么大的差异) 最后,LSTM文本生成 尼采的著作与其他测试类似,但没有对GPU造成严重打击。
结论 事实证明,使用64个vCPU不利于深度学习,因为当前的软/硬件架构无法充分利用这么多处理器,通常效果与32个vCPU性能相同(甚至更差)。 综合训练速度和成本两方面考虑,用16个vCPU+编译的TensorFlow训练模型似乎是赢家。编译过的TensorFlow库能带来30%-40%的性能提升。考虑到这种差异,谷歌不提供具有这些CPU加速功能的预编译版本TensorFlow还是令人吃惊的。 这里所说成本优势,只有在使用谷歌云Preemptible实例的情况下才有意义,Google Compute Engine上的高CPU实例要贵5倍,完全可以消弭成本优势。规模经济万岁! 使用云CPU训练的一个主要前提是,你没那么迫切的需要一个训练好的模型。在专业案例中,时间可能是最昂贵的成本;而对于个人用户而言,让模型兀自训练一整晚也没什么,而且是一个从成本效益方面非常非常好的选择。 这次测试的所有脚本,都可以在GitHub里找到,地址: https://github.com/minimaxir/deep-learning-cpu-gpu-benchmark 另外还可以查看用于处理日志的R/ggplot2代码,以及在R Notebook中的可视化展现,其中有关于这次测试的更详细数据信息。地址: http://minimaxir.com/notebooks/deep-learning-cpu-gpu/ 【完】 一则通知 量子位读者5群开放申请,对人工智能感兴趣的朋友,可以添加量子位小助手的微信qbitbot2,申请入群,一起研讨人工智能。 另外,量子位大咖云集的自动驾驶技术群,仅接纳研究自动驾驶相关领域的在校学生或一线工程师。申请方式:添加qbitbot2为好友,备注“自动驾驶”申请加入~ 招聘 量子位正在招募编辑/记者等岗位,工作地点在北京中关村。相关细节,请在公众号对话界面,回复:“招聘”。 追踪人工智能领域最劲内容返回搜狐,查看更多 |
【本文地址】
今日新闻 |
推荐新闻 |