分布式高可用架构一些理论 |
您所在的位置:网站首页 › tcc文件 › 分布式高可用架构一些理论 |
分布式高可用架构一些理论
|
SLA(Service-Level Agreement,服务等级协议、服务水平协议)通俗的定义:SLA =可用时长/(可用时长+不可用时长)。不通俗的定义:SLA =f(MTBF,MTTR)。MTBF:平均故障间隔,通俗一点就是一个东西多长时间坏一次。MTTR:平均修复时间,意思是一旦东西坏了,需要多长时间去修复或者恢复它。 提高SLA只有两个方法:一是提高系统的可用时长,二是降低系统的不可用时长。或者说,提高MTBF,降低MTTR。 高可用策略 高可用策略FMEA理论 高可用策略FMEA理论FMEA(Failure Mode and Effects Analysis,失效模式与影响分析,又称为失效模式与后果分析、失效模式与效应分析、故障模式与后果分析、故障模式与效应分析)。是一种操作规程,旨在对系统范围内潜在的失效模式加以分析,以便按照严重程度加以分类,或者确定失效对于该系统的影响。FEMA是排除架构高可用隐患的利器。  FMEA分析表-使用FMEA分析文章点赞功能 集群与分布式 FMEA分析表-使用FMEA分析文章点赞功能 集群与分布式分布式:主要是指将不同的业务分布到不同的地方;分布式是以缩短单个任务的执行时间来提升效率的,解决高并发问题;集群:主要是指将几台服务器集中在一起,实现同一个业务。集群主要是通过提高单位时间内执行的任务数来提升效率的,提高系统的可用性。 集群架构 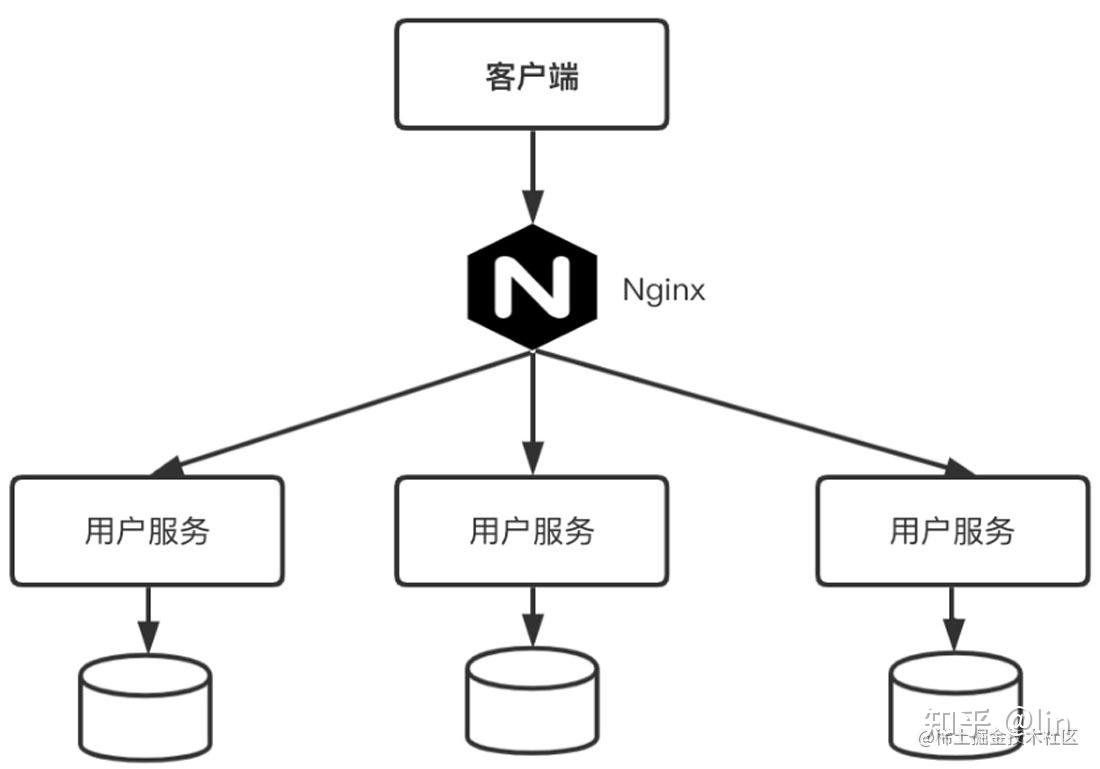 集群架构 集群架构 分布式架构CAP理论C(Consistency):一致性,分布式系统中的所有数据备份在同一时刻具有同样的值,所有节点在同一时刻读取的数据都是最新的数据副本。例如,对某个指定的客户端来说,读操作能返回最新的写操作。对于数据分布在不同节点上的数据来说,在某个节点更新了数据,如果在其他节点都能读取到这个最新的数据,就称为强一致,如果有某个节点没有读取到,就是不一致。A(Availability):可用性,非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。可用性的两个关键:一个是合理的时间,另一个是合理的响应。合理的时间指的是请求不能无限被阻塞,应该在合理的时间给出返回;合理的响应指的是系统应该明确返回结果并且结果是正确的。P(Partition Tolerance):分区容错性,当出现网络分区后,系统能够继续工作。在实际场景中,网络环境不可能百分之百不出现故障,比如网络拥塞、网卡故障等都会导致网络故障或不通,从而导致节点之间无法通信,或者集群中的节点被划分为多个分区,分区中的节点之间可通信,分区间不可通信。这种由网络故障导致的集群分区情况通常被称为“网络分区”。 分布式架构CAP理论C(Consistency):一致性,分布式系统中的所有数据备份在同一时刻具有同样的值,所有节点在同一时刻读取的数据都是最新的数据副本。例如,对某个指定的客户端来说,读操作能返回最新的写操作。对于数据分布在不同节点上的数据来说,在某个节点更新了数据,如果在其他节点都能读取到这个最新的数据,就称为强一致,如果有某个节点没有读取到,就是不一致。A(Availability):可用性,非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。可用性的两个关键:一个是合理的时间,另一个是合理的响应。合理的时间指的是请求不能无限被阻塞,应该在合理的时间给出返回;合理的响应指的是系统应该明确返回结果并且结果是正确的。P(Partition Tolerance):分区容错性,当出现网络分区后,系统能够继续工作。在实际场景中,网络环境不可能百分之百不出现故障,比如网络拥塞、网卡故障等都会导致网络故障或不通,从而导致节点之间无法通信,或者集群中的节点被划分为多个分区,分区中的节点之间可通信,分区间不可通信。这种由网络故障导致的集群分区情况通常被称为“网络分区”。CAP原理证明,任何分布式系统只可以同时满足以上两点,无法三者兼顾。在分布式系统中,网络无法100%可靠,分区其实是一个必然现象。也就是说,分区容错性(P)是前提,是必须要保证的。  ACID理论原子性(Atomicity):组成事务的一组操作,要么全部成功,要么全部失败,不会在中间的某个环节结束。一致性(Consistency):事务执行前后,数据库的完整性没有被破坏,事务执行前后都是合法的数据状态。隔离性(Isolation):数据库允许多个事务并发地对数据进行读写。持久性(Durability):事务提交后,对数据的修改是持久的,不会因为外部原因丢失。 ACID理论原子性(Atomicity):组成事务的一组操作,要么全部成功,要么全部失败,不会在中间的某个环节结束。一致性(Consistency):事务执行前后,数据库的完整性没有被破坏,事务执行前后都是合法的数据状态。隔离性(Isolation):数据库允许多个事务并发地对数据进行读写。持久性(Durability):事务提交后,对数据的修改是持久的,不会因为外部原因丢失。ACID理论是对事务特性的抽象和总结,方便我们实现事务。ACID理论是传统数据库常用的设计理念,追求强一致性模型。在单机上实现ACID也不难,但是一旦涉及分布式系统的ACID特性,就需要用到分布式事务协议,比如两阶段提交(Two Phase Commit,2PC)。 两阶段提交两阶段提交是一种在分布式环境下,所有节点进行事务提交,保持一致性的算法。它通过引入一个协调者(Coordinator)来统一掌控所有参与者(Participant)的操作结果,并指示它们是否要把操作结果进行真正的提交(Commit)或者回滚(Rollback)。两阶段提交分为两个阶段:(1)投票阶段(Voting Phase):协调者通知参与者,参与者反馈结果。(2)提交阶段(Commit Phase):收到参与者的反馈后,协调者再向参与者发出通知,根据反馈情况决定各参与者是提交还是回滚。两阶段提交在执行过程中,所有节点都处于阻塞状态,所有节点所持有的资源(例如数据库数据、本地文件等)都处于封锁状态。如果有协调者或者某个参与者出现了崩溃,为了避免整个算法处于完全阻塞状态,往往需要借助超时机制来将算法继续向前推进。两阶段提交这种解决方案属于牺牲了一部分可用性来换取一致性,对性能的影响较大,不适合高并发、高性能的场景。 补偿事务TCCTCC采用的补偿机制,其核心思想是:针对每个操作都要注册一个与其对应的确认和补偿(撤销)操作。TCC分为3个阶段: Try阶段:主要是对业务系统进行检测及资源预留。Confirm阶段:主要是对业务系统进行确认提交,Try阶段执行成功并开始执行Confirm阶段时,默认Confirm阶段是不会出错的,即只要Try阶段成功,Confirm阶段一定成功。Cancel阶段:主要是在业务执行错误,需要回滚的状态下将执行的业务取消,将预留资源释放。TCC的核心思想:针对每个操作都要注册与其对应的确认操作和补偿操作(也就是撤销操作)。它是一个业务层面的协议.BASE理论BASE理论是CAP理论中AP的延伸。 Basically Available(基本可用)。Soft State(软状态)。Eventually Consistent(最终一致性)。BASE理论是对CAP中的一致性和可用性进行权衡的结果,理论的核心思想是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。主要办法有流量削峰、延迟响应、降级、过载保护。高可用之选举算法一个高可用的集群中,一般都会存在主节点的选举机制,主节点用来协调和管理其他节点,以保证集群有序运行和节点间数据的一致性。 霸道选举算法一种分布式选举算法,每次都会选出存活的进程中ID最大的候选者。在霸道选举算法中,节点的角色只有两种:普通节点和主节点。 Raft选举算法Raft这一名字来源于Reliable, Replicated, Redundant, And Fault-Tolerant(可靠、可复制、可冗余、可容错)的首字母缩写,是一种用于替代Paxos的共识算法。 ZAB选举算法ZAB(ZooKeeper Atomic Broadcast)选举算法是为ZooKeeper实现分布式协调功能而设计的。相较于Raft算法的投票机制,ZAB算法增加了通过节点ID和数据ID作为参考进行选主,节点ID和数据ID越大,表示数据越新,优先成为主。相比较于Raft算法,ZAB算法尽可能保证数据的最新性。所以,ZAB算法可以说是对Raft算法的改进。 高可用之共识算法Basic Paxos算法Multi-Paxos算法Raft算法高可用之一致性算法一致性分类强一致性(Strong):数据A一旦写入成功,在任意副本、任意时刻都能读到A的最新值。强一致性的案例很多,例如MySQL全同步复制(Fully Synchronous Replication),现在有一个MySQL集群,由一主两备3个节点构成,那么在全同步复制模式下,主库与备库同步binlog时,主库只有在收到两个备库的成功响应后,才能够向客户端反馈提交成功。用户获得响应时,主库和备库的数据副本已经达成一致,所以后续的读操作肯定是一致的。弱一致性(Weak):写入数据A成功后,在数据副本上可能读出来,也可能读不出来,不能保证多长时间之后每个副本的数据一定是一致的。弱一致性在生产环境中基本没什么应用场景。最终一致性(Eventually):最终一致性是弱一致性的一个特例。写入数据A成功后,在其他副本有可能读不到A的最新值,但在某个时间窗口之后保证最终能读到。这里的重点是“时间窗口”。弱一致性的典型代表是NoSQL产品,在主副本执行写操作并反馈成功时,不要求其他副本与主副本保持一致,但在经过一段时间后,这些副本最终会追上主副本的进度,重新达到数据状态的一致。Gossip协议(最终一致性)Gossip协议也叫Epidemic协议(流行病协议),或者流言协议,是基于流行病传播方式的节点或者进程之间信息交换的协议。Gossip协议是基于六度分隔理论(Six Degrees of Separation)哲学的体现,简单来说,就是一个人通过6个中间人可以认识世界上的任何人。 Quorum NWR算法如果我们想从最终一致性临时改成强一致性,可以通过Quorum NWR算法,自定义一致性级别。 Raft日志一致性日志复制可以说是Raft集群的核心之一,保证了Raft数据的一致性。在Raft算法中,副本数据是以日志的形式存在的,每条日志由很多日志项组成。 |
【本文地址】