使用Python批量进行数据分析 |
您所在的位置:网站首页 › sum汇总不出数据 › 使用Python批量进行数据分析 |
使用Python批量进行数据分析
|
案例01 批量升序排序一个工作簿中的所有工作表——产品销售统计表.xlsx
import xlwings as xw
import pandas as pd
app = xw.App(visible = False, add_book = False)
workbook = app.books.open('产品销售统计表.xlsx')
worksheet = workbook.sheets # 列出工作簿中的所有工作表
for i in worksheet: # 遍历工作簿中的工作表
values = i.range('A1').expand('table').options(pd.DataFrame).value # 读取当前工作表的数据并转换为DataFrame格式
result = values.sort_values(by = '销售利润') # 对“销售利润”列进行升序排序
i.range('A1').value = result # 将排序结果写入当前工作表,替换原有数据
workbook.save()
workbook.close()
app.quit()
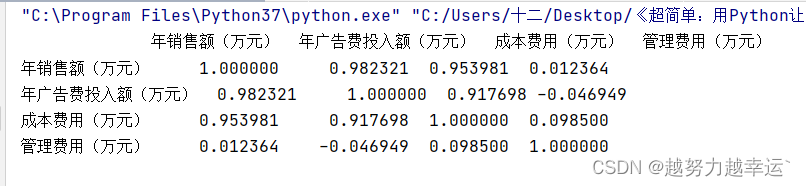
知识延伸 1、sort_value()是pandas模块中DataFrame对象的函数,用于将数据区域按照某个字段的数据进行排序,这个字段可以是行字段,也可以是列字段。 语法格式: sort_value(by='##',axis=0,ascending=True,inplace=False,na_position='last') 参数说明by要排序的列名或索引值axis如果省略或者为0或’index‘,则按照参数by指定的列中的数据排序;如果为1或’columns‘,则按照参数by指定的索引中的数据排序ascending排序方式。如果省略或为True,则做升序排序;如果为False,则做降序排序inplace如果省略或为false,则不用排序后的数据替换原来的数据;如果为True,则用排序后的数据替换原来的数据na_position空值的显示位置。如果为’first',表示将空值放在列的首位;如果位位‘last’,则表示将空值放在列的末尾批量降序排序一个工作簿中的所有工作表——产品销售统计表.xlsx import xlwings as xw import pandas as pd app = xw.App(visible = False, add_book = False) workbook = app.books.open('产品销售统计表.xlsx') worksheet= workbook.sheets for i in worksheet: values = i.range('A1').expand('table').options(pd.DataFrame).value result = values.sort_values(by = '销售利润', ascending = False) i.range('A1').value = result workbook.save() workbook.close() app.quit()批量排序多个工作簿中的数据——产品销售统计表(文件夹) import os import xlwings as xw import pandas as pd app = xw.App(visible = False, add_book = False) file_path = '产品销售统计表' file_list = os.listdir(file_path) for i in file_list: if os.path.splitext(i)[1] == '.xlsx': workbook = app.books.open(file_path + '\\' + i) worksheet = workbook.sheets for j in worksheet: values = j.range('A1').expand('table').options(pd.DataFrame).value result = values.sort_values(by = '销售利润') j.range('A1').value = result workbook.save() workbook.close() app.quit() 案例02 筛选一个工作簿中的所有工作表数据——采购表.xlsx import xlwings as xw import pandas as pd app = xw.App(visible = False, add_book = False) workbook = app.books.open('采购表.xlsx') worksheet = workbook.sheets # 列出工作簿中的所有工作表 table = pd.DataFrame() # 创建一个空DataFrame for j in worksheet: values = j.range('A1').options(pd.DataFrame, header=1, index=False, expand='table').value # 读取当前工作表 data = values.reindex(columns=['采购物品', '采购日期', '采购数量', '采购金额']) # 调整列的顺序,将‘采购物品’移至第1列 table = table.append(data, ignore_index = True) # 将调整列顺序后的数据合并到前面创建的DataFrame中 table = table.groupby('采购物品') # 根据”采购物品“列筛选数据 new_workbook = app.books.add() # 新建一个工作簿 for idx, group in table: # 遍历筛选好的数据,其中idx对应物品名称,group对应该物品的所有明细数据 new_worksheet = new_workbook.sheets.add(idx) # 在新工作簿中新增工作表,以物品名称作为工作表名 new_worksheet['A1'].options(index = False).value = group # 在新工作表中写入当前物品的所有明细数据 last_cell = new_worksheet['A1'].expand('table').last_cell # 获取当前工作表数据区域右下角的单元格 last_row = last_cell.row # 获取数据区域最后一行的行号 last_column = last_cell.column # 获取数据区域最后一列的列号 last_column_letter = chr(64 + last_column) # 将数据区域最后一列的列号(数字)转换为该列的列表(字母) sum_cell_name = '{}{}'.format(last_column_letter, last_row+1) # 获取数据区域右下角单元格下方的单元格的位置 sum_last_row_name = '{}{}'.format(last_column_letter, last_row) # 获取数据区域右下角单元格的位置 formula = '=SUM({}2:{})'.format(last_column_letter, sum_last_row_name) # 根据前面获取的单元格位置构造Excel公式,对采购金额进行求和 new_worksheet[sum_cell_name].formula = formula # 将求和公式写入数据区域右下角单元格下方的单元格中 new_worksheet.autofit() # 根据单元格中的数据内容自动调整工作表的行高和列宽 new_workbook.save('采购分类表.xlsx') workbook.close() app.quit()知识延伸 1、reindex()是pandas模块中的函数,用于改变行、列的顺序。 语法格式: reindex(index=**,columns=**,fill_value=0) 参数: index=**,要改变位置的行,**为列表 columns=**,要改变位置的列,**为列表 fill_value=0,选参数,当前面两个参数中指定的行或列不存在时,可用该参数定义如何填充缺失值 2、groupby()是pandas模块中的函数,用于对数据进行分组。 3、chr()是python的内置函数,用于将一个整数转换为对应的字符。常用的整数和字符的对应关系可以搜索”ASCII码表”。 在一个工作簿中筛选单一类别数据——采购表.xlsx import xlwings as xw import pandas as pd app = xw.App(visible = False, add_book = False) workbook = app.books.open('采购表.xlsx') worksheet = workbook.sheets table = pd.DataFrame() for j in worksheet: values = j.range('A1').options(pd.DataFrame, header = 1, index = False, expand = 'table').value data = values.reindex(columns = ['采购物品', '采购日期', '采购数量', '采购金额']) table = table.append(data, ignore_index = True) # 将多个工作表的数据合并到一个DataFrame中 product = table[table['采购物品'] == '保险箱'] # 筛选“采购物品”是“保险箱”的数据 new_workbook = app.books.add() new_worksheet = new_workbook.sheets.add('保险箱') new_worksheet['A1'].options(index = False).value = product # 将筛选出的数据写入工作表(index=False为删除索引列) new_worksheet.autofit() new_workbook.save('保险箱.xlsx') workbook.close() app.quit() 案例03 对多个工作簿中的工作表分别进行分类汇总——销售表(文件夹) import os import xlwings as xw import pandas as pd app = xw.App(visible = False, add_book = False) file_path = '销售表' file_list = os.listdir(file_path) for i in file_list: if os.path.splitext(i)[1] == '.xlsx': # 判断文件是否是工作簿 workbook = app.books.open(file_path + '\\' + i) # 打开文件夹中的工作簿 worksheet = workbook.sheets # 列出工作簿中的所有工作表 for j in worksheet: #遍历工作簿中的工作表 values = j.range('A1').expand('table').options(pd.DataFrame).value # 读取当前工作表的数据 values['销售利润'] = values['销售利润'].astype('float') # 转换“销售利润”列的数据类型 result = values.groupby('销售区域').sum() # 根据“销售区域”列对数据进行分类汇总,汇总运算方式为求和 j.range('J1').value = result['销售利润'] # 将各个销售区域的销售利润汇总结果写入当前工作表 workbook.save() workbook.close() app.quit()1、astype()是pandas模块中DataFrame对象的函数,用于转换指定列的数据类型。 语法格式: astype('int') 参数:int,要转换的数据类型,可以是‘int’、‘float’、‘str’等 2、groupby()函数后接sum()函数用于进行求和汇总,还可以使用其他函数完成其他类型的汇总运算。常用的有:用mean()函数求平均值,用count()函数统计个数,用max()函数求最大值,用min()函数求最小值。 批量分类汇总多个工作簿中的指定工作表——销售表1(文件夹) import os import xlwings as xw import pandas as pd app = xw.App(visible = False, add_book = False) file_path = '销售表1' file_list = os.listdir(file_path) for i in file_list: if os.path.splitext(i)[1] == '.xlsx': workbook = app.books.open(file_path + '\\' + i) worksheet = workbook.sheets['销售记录表'] # 指定要分类汇总的工作表 values = worksheet.range('A1').expand('table').options(pd.DataFrame).value values['销售利润'] = values['销售利润'].astype('float') result = values.groupby('销售区域').sum() worksheet.range('J1').value = result['销售利润'] workbook.save() workbook.close() app.quit()将多个工作簿数据分类汇总到一个工作簿——销售表(文件夹) import os import xlwings as xw import pandas as pd app = xw.App(visible = False, add_book = False) file_path = '销售表' file_list = os.listdir(file_path) collection = [] for i in file_list: if os.path.splitext(i)[1] == '.xlsx': workbook = app.books.open(file_path + '\\' + i) worksheet = workbook.sheets['销售记录表'] values = worksheet.range('A1').expand('table').options(pd.DataFrame).value filtered = values[['销售区域', '销售利润']] collection.append(filtered) workbook.close() new_values = pd.concat(collection, ignore_index = False).set_index('销售区域') new_values['销售利润'] = new_values['销售利润'].astype('float') result = new_values.groupby('销售区域').sum() new_workbook = app.books.add() sheet = new_workbook.sheets[0] sheet.range('A1').value = result new_workbook.save('汇总.xlsx') app.quit() 案例04 对一个工作簿中的所有工作表分别求和 import xlwings as xw import pandas as pd app = xw.App(visible = False, add_book = False) workbook = app.books.open('采购表.xlsx') worksheet = workbook.sheets # 列出工作簿中所有的工作表 for i in worksheet: # 遍历工作簿中的工作表 values = i.range('A1').expand('table') # 选中工作表中含有数据的单元格区域 data = values.options(pd.DataFrame).value # 使用选中的单元格区域中的数据创建一个DataFrame sums = data['采购金额'].sum() # 在创建的DATaFrame中对“采购金额”列进行求和 column = values.value[0].index('采购金额') + 1 # 获取“采购金额”列的列号 row = values.shape[0] # 获取数据区域最后一行的行号 i.range(row + 1, column).value = sums # 将求和结果写入“采购金额”列最后一个单元格下方的单元格中 workbook.save() workbook.close() app.quit()1、index()是python中列表对象的函数,常用于在列表中查找某个元素的索引位置。 语法格式: index(obj,start,end) 参数: obj,要查找的元素 start,可选,查找的起始位置 end,可选,查找的结束位置 2、shape是pandas模块中DataFrame对象的一个属性,它返回的是一个元组,其中有两个元素,分别代表DataFrame的行数和列数。 import xlwings as xw import pandas as pd app = xw.App(visible = False, add_book = False) workbook = app.books.open('采购表.xlsx') worksheet = workbook.sheets for i in worksheet: values = i.range('A1').expand('table').options(pd.DataFrame).value sums = values['采购金额'].sum() i.range('F1').value = sums # 将当前工作表中数据的求和结果写入当前工作表的单元格F1中 workbook.save() workbook.close() app.quit() 案例05 批量统计工作簿的最大值和最小值——产品销售统计表(文件夹) import os import xlwings as xw import pandas as pd app = xw.App(visible = False, add_book = False) file_path = '产品销售统计表' file_list = os.listdir(file_path) for j in file_list: if os.path.splitext(j)[1] == '.xlsx': workbook = app.books.open(file_path + '\\' + j) worksheet = workbook.sheets for i in worksheet: # 遍历工作簿中的工作表 values = i.range('A1').expand('table').options(pd.DataFrame).value # 读取当前工作表的数据 max = values['销售利润'].max() # 统计“销售利润”列的最大值 min = values['销售利润'].min() # 统计“销售利润”列的最小值 i.range('I1').value = '最大销售利润' # 在当前工作表的单元格I1中写入文本内容 i.range('J1').value = max # 在当前工作表的单元格J1中写入统计出的最大值 i.range('I2').value = '最小销售利润' # 在当前工作表的单元格I2中写入文本内容 i.range('J2').value = min # 在当前工作表的单元格J2中写入统计出的最小值 workbook.save() workbook.close() app.quit()知识延伸 1、除了sum()、mean()、count()、max()、min()等函数,还可以用value_counts()函数统计重复值的个数,用product()函数计算乘积,用std()函数计算标准差等等。 批量统计一个工作簿中所有工作表的最大值和最小值——产品销售统计表.xlsx import xlwings as xw import pandas as pd app = xw.App(visible = False, add_book = False) workbook = app.books.open('产品销售统计表.xlsx') worksheet = workbook.sheets for i in worksheet: values = i.range('A1').expand('table').options(pd.DataFrame).value max = values['销售利润'].max() min = values['销售利润'].min() i.range('I1').value = '最大销售利润' i.range('J1').value = max i.range('I2').value = '最小销售利润' i.range('J2').value = min workbook.save() workbook.close() app.quit() 案例06 批量制作数据透析表 import os import xlwings as xw import pandas as pd app = xw.App(visible = False, add_book = False) file_path = '商品销售表' # 给出要制作数据透视表的工作簿所在的文件夹路径 file_list = os.listdir(file_path) # 列出文件夹下所有文件和子文件夹的名称 for j in file_list: # 遍历文件夹下的文件 if os.path.splitext(j)[1] == '.xlsx': # 判断文件是否是工作簿 workbook = app.books.open(file_path + '\\' + j) # 打开文件夹中的工作簿 worksheet = workbook.sheets # 列出当前工作簿中的所有工作表 for i in worksheet: # 遍历当前工作簿中的工作表 values = i.range('A1').expand('table').options(pd.DataFrame).value # 读取当前工作表的数据 pivottable = pd.pivot_table(values, values = '销售金额', index = '销售地区', columns = '销售分部', aggfunc = 'sum', fill_value = 0, margins = True, margins_name = '总计') # 用读取的数据制作数据透视表 i.range('J1').value = pivottable # 将制作的数据透视表写入当前工作表 workbook.save() workbook.close() app.quit()知识延伸 1、pivot_table()是pandas模块中的函数,用于创建一个电子表格样式的数据透视表。 语法pivot_table(data,values=None,index=None,columns=None,aggfunc='mefill_value=None,margins=False,dropna=True,margins_name='AII') 参数说明data必选参数,用于指定要制作数据透视表的数据区域values可选参数,用于指定汇总计算的字段index必选参数,用于指定行字段columns必选参数,用于指定列字段aggfunc用于指定汇总计算的方式,如’sum'(求和)、‘mean’(计算平均值)fill_value用于指定填充缺失值的内容,默认不填充margins用于设置是否显示行列的总计数据,为False时不显示,为True时则显示dropna用于设置当汇总后的整行数据都为空值时是否丢弃该行,为True时丢弃,为False时则不丢弃margins_name当参数margins为True时,用于设置总计数据行的名称为一个工作簿的所有工作表制作数据透视表——商品销售表.xlsx import xlwings as xw import pandas as pd app = xw.App(visible=False,add_book=False) workbook = app.books.open('商品销售表.xlsx') worksheet= workbook.sheets for i in worksheet: values = i.range('A1').expand('table').options(pd.DataFrame).value pivottable = pd.pivot_table(values,values='销售金额',index='销售地区',columns='销售分部',aggfunc='sum',fill_value=0,margins=True,margins_name='总计') i.range('J1').value =pivottable workbook.save() workbook.close() app.quit() 案例07 使用相关系统判断数据的相关性——相关性分析.xlsx import pandas as pd # 导入pandas模块 df = pd.read_excel('相关性分析.xlsx', index_col = '代理商编号') # 从指定工作簿中读取要进行相关性分析的数据 result = df.corr() # 计算任意两个变量之间的相关系数 print(result) # 输出计算出的相关系数运行结果:
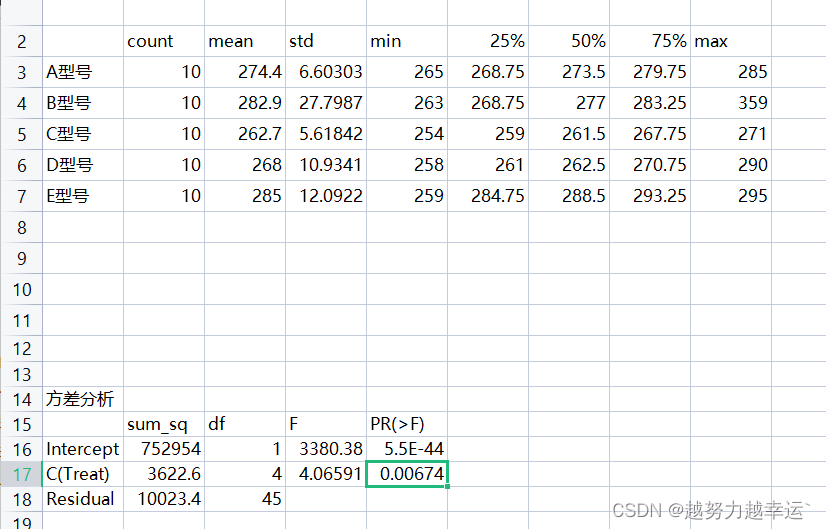
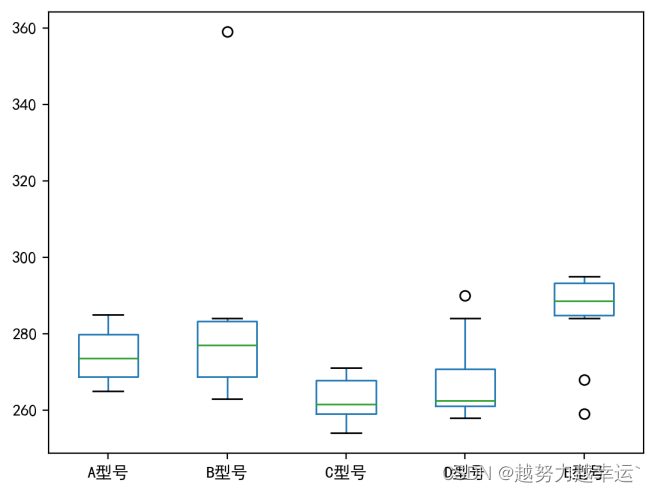
corr()函数默认计算的是两个变量之间的皮尔逊相关系数。该系数用于描述两个变量间线性相关性的强调,取值范围[-1,1]。系数为正值表示存在正相关性,为负值表示存在负相关性,为0表示不存在线性相关性。系数的绝对值越大,说明相关性越强。 从上图运行结果,可以看到,年销售额与年广告费投入额、成本费用之间 皮尔逊相关系数均接近1,而与管理费用之间的皮尔逊相关系数接近0,说明年销售额与年广告费投入额、成本费用之间均存在较强的线性正相关,而与管理费用之间基本不存在线性相关性。 知识延伸 1、read_excel()是pandas模块中的函数,用于读取工作簿数据。 语法格式: read_excel(io,sheet_name=0,header=0,names=None,index_col=None,usecols=None,squeeze=False,dtype=None) 参数说明io要读取的工作簿的文件路径sheet_name默认值为0.如果为字符串,则代表工作表名称;如果为整数,则代表工作表的序号(从0开始);如果为字符串列表或整数列表,表示读取多个工作表;如果为None,表示读取所有工作表header指定作为列名的行,默认为0,即读取第1行的内容作为列名,读取列名行以下的内容作为数据;如果工作表原有内容没有列名,则应设置header=Nonenames指定要使用的列名列表,默认为Noneindex_col指定作为索引的列,默认为None,表示用自动生成的整数序列作为索引usecols指定要读取的列。默认为None,表示读取所有列;如果为字符串,如‘A:E'或’A,C,E:F‘等,表示按列标读取指定列;如果为整数列表,表示按列号(从0开始)读取指定列;如果为字符串列表,表示按列名读取指定列squeeze默认为False,如果为True,则表示当前读取的数据只有一列时,返回一个Seriesdtype指定数据或列的数据类型,默认为None2、corr()是pandas模块中的DataFrame对象自带的一个函数,用于计算列与列之间的相关系数。 语法结构: corr(method='pearson',min_periods=1) 参数: method=’pearson',可选参数,可以为‘Pearson’(即皮尔逊相关系数)、‘Kendall’或‘spearman’ min_periods=1,可选参数,为样本的最少数据量,默认是1 求单个变量和其他变量间的相关性——相关性分析.xlsx import pandas as pd df = pd.read_excel('相关性分析.xlsx', index_col = '代理商编号') result = df.corr()['年销售额(万元)'] # 计算年销售额与其他变量之间的皮尔逊相关系数 print(result) 案例08 使用方差分析对比数据的差异——方差分析.xlsx import pandas as pd # 导入pandas模块 from statsmodels.formula.api import ols # 导入statsmodels.formula.api模块中的ols()函数 from statsmodels.stats.anova import anova_lm # 导入statsmodels.stats.anova模块中的anova_lm()函数 import xlwings as xw # 导入xlwings模块 df = pd.read_excel('方差分析.xlsx') # 读取指定工作簿中的数据 df = df[['A型号','B型号','C型号','D型号','E型号']] # 选取“A型号”“B型号”“C型号”“D型号”“E型号”列的数据用于分析 df_melt = df.melt() # 将列名转换为列数据,重构DataFrame df_melt.columns = ['Treat', 'Value'] # 重命名列 df_describe = pd.DataFrame() # 创建一个空DataFrame用于汇总数据 df_describe['A型号'] = df['A型号'].describe() # 计算‘A型号’论坛刹车距离的平均值、最大值、最小值等 df_describe['B型号'] = df['B型号'].describe() # 计算‘B型号’论坛刹车距离的平均值、最大值、最小值等 df_describe['C型号'] = df['C型号'].describe() # 计算‘C型号’论坛刹车距离的平均值、最大值、最小值等 df_describe['D型号'] = df['D型号'].describe() # 计算‘D型号’论坛刹车距离的平均值、最大值、最小值等 df_describe['E型号'] = df['E型号'].describe() # 计算‘E型号’论坛刹车距离的平均值、最大值、最小值等 model = ols('Value~C(Treat)', data = df_melt).fit() # 对样本数据进行最小二乘线性拟合计算 anova_table = anova_lm(model, typ = 3) # 对样本数据进行方差分析 app = xw.App(visible = False) # 启动Excel程序 workbook = app.books.open('方差分析.xlsx') # 打开要写入分析结果的工作簿 worksheet = workbook.sheets['单因素方差分析'] # 选中工作表“单因素方差分析” worksheet.range('H2').value = df_describe.T # 将计算出的平均值、最大值和最小值等数据转置行列并写入工作表 worksheet.range('H14').value = '方差分析' # 在工作表中写入文本“方差分析” worksheet.range('H15').value = anova_table # 将方差分析的结果写入工作表 workbook.save() workbook.close() app.quit() 运行结果: 从运行结果中,我们需要关心单元格L17中的数值,它相当于用Excel的单因素方差分析功能计算出的P-value,代表观测到的显著性水平。通常情况下,该值 知识延伸 1、metl()是pandas模块中的DataFrame对象的函数,用于将列名转换为列数据。 语法结构: melt(id_vars=None,value_vars=None,var_name=None,value_name='value',col_level=None) 参数说明id_vars不需要转换的列的列名value_vars需要转换的列的列名,如果未指明,则除id_vars之外的列都将被转换var_name参数value_vars的值转换后的列名value_name数值列的列名col_level可选参数,如果不止一个索引列,则使用该参数2、describe()是pandas模块中DataFrame对象的函数,用于总结数据集分布的集中趋势,生成描述性统计数据。 语法结构: DataFrame.describe(percentiles=None,include=None,exclude=None) 参数说明percentiles可选参数,数据类型为列表,用于设定数值型特征的统计量。默认值为None,表示返回25%、50%、75%数据量时的数字include可选参数,用于设定运行结果要包含哪些数据类型的列。默认值为None,表示运行结果将包含所有数据类型为数字的列exclude可选参数,用于设定运行结果要忽略哪些数据类型的列。默认值为None,表示运行结果将不忽略任何列3、ols()是statsmodels.formula.api模块中的函数,用于对数据进行最小二乘线性拟合计算。 语法格式: ols(formula,data) 参数说明formula用于指定模型的公式的字符串data用于搭建模型的数据4、anova_lm()是statsmodels.stats.anova模块中的函数,用于对数据进行方差分析并输出结果。 语法结构: anova_lm(args,scale,test,typ,robust) 参数说明args一个或多个拟合线性模型scale方差估计,如果为None,将从最大的模型估计test提供测试统计数据typ要进行的方差分析的类型robust使用异方差校正系数协方差矩阵绘制箱型图识别异常值——方差分析.xlsx import pandas as pd import matplotlib.pyplot as plt import xlwings as xw df = pd.read_excel('方差分析.xlsx') df = df[['A型号', 'B型号', 'C型号', 'D型号', 'E型号']] figure = plt.figure() # 创建绘图窗口 plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码问题 df.boxplot(grid = False) # 绘制箱形图并删除网格线 app = xw.App(visible = False) workbook = app.books.open('方差分析.xlsx') worksheet = workbook.sheets['单因素方差分析'] worksheet.pictures.add(figure, name = '图片1', update = True, left = 500, top = 10) # 将绘制的箱形图插入工作表 workbook.save('箱形图.xlsx') workbook.close() app.quit()运行结果:
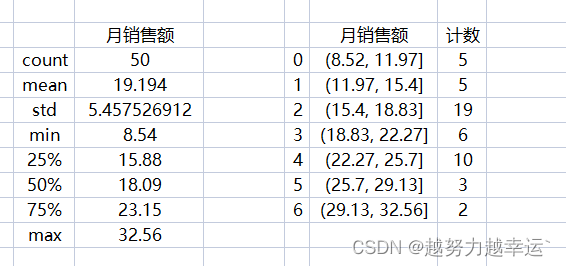
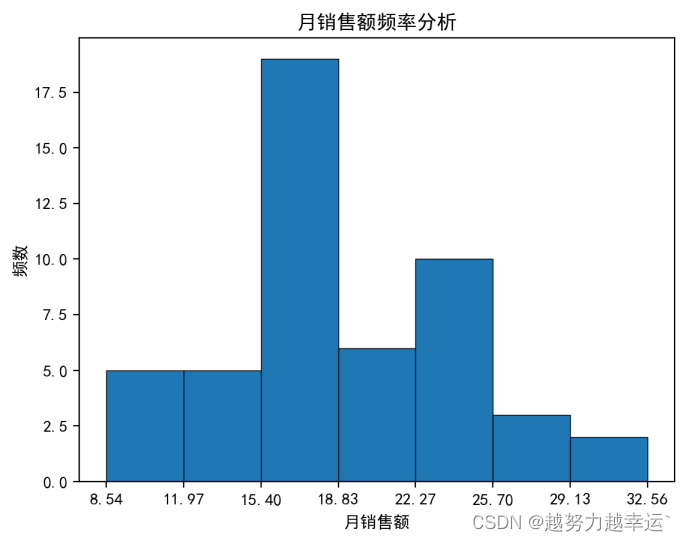
图中用圆圈标识的数据点就是异常值。 案例09 使用描述统计和直方图指定目标——描述统计.xlsx import pandas as pd # 导入pandas模块 import matplotlib.pyplot as plt # 导入Matplotlib模块 import xlwings as xw # 导入xlwings模块 df = pd.read_excel('描述统计.xlsx') # 读取指定工作簿中的数据 df.columns = ['序号','员工姓名','月销售额'] # 重命名数据列 df = df.drop(columns=['序号','员工姓名']) # 删除“序号”列和“员工姓名“列 df_describe = df.astype(float).describe() # 计算数据的个数、平均值、最大值和最小值等描述统计数据 df_cut = pd.cut(df['月销售额'], bins = 7, precision = 2) # 将”月销售额“列的数据分成7个均等的区间 cut_count = df['月销售额'].groupby(df_cut).count() # 统计各个区间的人数 df_all = pd.DataFrame() # 创建一个空的DataFrame用于汇总数据 df_all['计数'] = cut_count # 将月销售额的区间及区间的人数写入前面创建的DataFrame中 df_all_new = df_all.reset_index() # 将索引重置为数字序号 df_all_new['月销售额'] = df_all_new['月销售额'].apply(lambda x:str(x)) # 将”月销售额“列的数据转换为字符串类型 fig = plt.figure() # 创建绘图窗口 plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码问题 n, bins, patches = plt.hist(df['月销售额'], bins = 7, edgecolor = 'black', linewidth = 0.5) #使用”月销售额“列的数据绘制直方图 plt.xticks(bins) # 将直方图x轴的刻度标签设置为各区间的端点值 plt.title('月销售额频率分析') # 设置直方图的图表标题 plt.xlabel('月销售额') # 设置直方图x轴的标题 plt.ylabel('频数') # 设置直方图y轴的标题 app = xw.App(visible = False) # 启动Excel程序 workbook = app.books.open('描述统计.xlsx') # 打开要写入分析结果的工作簿 worksheet = workbook.sheets['业务员销售额统计表'] # 选中工作簿中的工作表 worksheet.range('E2').value = df_describe # 将计算出的个数、平均值、最大值和最小值等数据写入工作表 worksheet.range('H2').value = df_all_new # 将月销售额的区间及区间的人数写入工作表 worksheet.pictures.add(fig, name = '图片1', update = True, left = 400, top = 200) # 绘制的直方图转换为图片并写入工作表 worksheet.autofit() # 根据数据内容自动调整工作表的行高和列宽 workbook.save('描述统计1.xlsx') workbook.close() app.quit()运行结果:
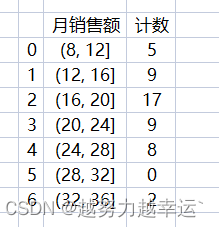
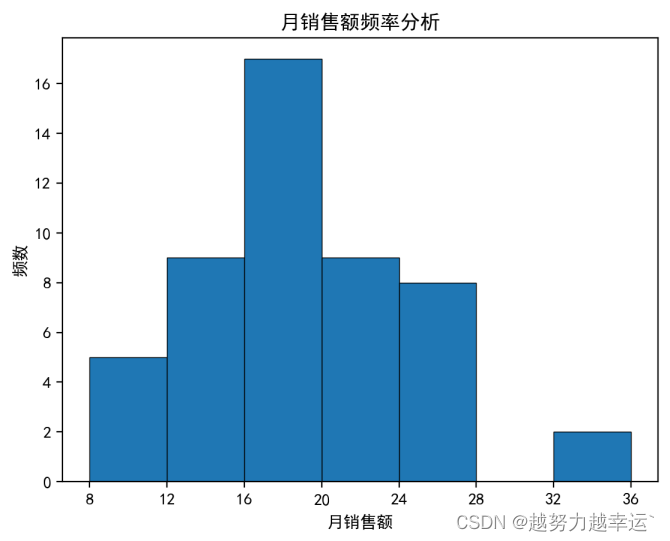
可以看到上图描述统计数据和分组统计数据。 描述统计数据中几个比较重要的值分别为平均值(mean)19.194、标准差(std)5.46、中位数(50%)18.09、最小值8.54、最大值32.56. 直方图如下,根据直方图可以看出,月销售额基本上以18为基础向两边递减,即18最普遍。 综合考虑上面的描述统计数据及直方图的分布情况,并适当增加目标的挑战性,将月销售额的目标(万元)定在18~20之间是比较合理的,大多数人应该能够完成。 知识延伸 1、cut()是pandas模块中的函数,用于对数据进行离散化处理,也就是将数据从最大值到最小值进行等距划分。 语法格式: cut(x,bins,right=True,labels=None,retbins=False,precision=3,include_lowest=False) 参数说明x要进行离散化的一维数组bins如果为整数,表示将x划分为多少个等间距的区间;如果为序列,表示将x划分在指定的序列中right设置区间是否包含右端点labels为划分出的区间指定名称标签retbins设置是否返回每个区间的端点值precision设置区间端点值的精度include_lowest设置区间是否包含左端点2、reset_index()是pandas模块中DataFrame对象的函数,用于重置DataFrame对象的索引。 语法格式: DataFrame.reset_index(level=None,drop=False,inplace=False,col_level=0,col_fill='') 参数说明level控制要重置哪个等级的索引drop默认值为False,表示索引列会被还原为普通列,否则会丢失inplace默认值为False,表示不修改原有的DataFrame,而是创建新的DataFramecol_level当列有多个级别时,用于确定将标签插入哪个级别。默认值为0,表示插入第一个层级col_fill当列有多个级别时,用于确定如何命名其他级别。默认值为‘’,如果为None,则重复使用索引名3、figure()是matplotlib.pyplot模块中的函数,用于创建一个绘图窗口。 语法格式: figure(num=None,figsize=None,dpi=None,facecolor=None,edgecolor=None,frameon=True,clear=False) 参数说明num可选参数,用于设置窗口的名称,默认值为Nonefigsize可选参数,用于设置窗口的大小,默认值为Nonedpi可选参数,用于设置窗口的分辨率,默认值为Nonefacecolor可选参数,用于设置窗口的背景颜色edgecolor可选参数,用于设置窗口的边框颜色frameon可选参数,表示是否绘制窗口的图框,如果为False,则绘制窗口的图框clear可选参数,如果为True并且窗口中已经有图形,则清除该窗口中的图形4、hist()是Matplotlib模块中的函数,用于绘制直方图。 语法格式: hist(x,bins=None,range=None,density=False,color=None,edgecolor=None,linewidth=None) 参数说明x指定用于绘制直方图的数据bins如果为整数,表示将数据等分为相应数量的区间,默认值为10;如果为序列,表示用序列的元素作为区间的端点值range指定参与分组统计的数据的范围,不在此范围的数据将被忽略。如果参数bins取值为序列形式,则此参数无效density如果为True,表示绘制频率直方图;如果为False,表示绘制频数直方图color/edgecolor /linewidth 分别用于设置柱子的填充颜色、边框颜色、边框粗细使用自定义区间绘制直方图——描述统计.xlsx import pandas as pd import matplotlib.pyplot as plt import xlwings as xw df = pd.read_excel('描述统计.xlsx') df.columns = ['序号','员工姓名','月销售额'] df = df.drop(columns=['序号','员工姓名']) df_describe = df.astype(float).describe() df_cut = pd.cut(df['月销售额'], bins = range(8, 37, 4)) # 按指定的端点值划分区间 cut_count = df['月销售额'].groupby(df_cut).count() df_all = pd.DataFrame() df_all['计数'] = cut_count df_all_new = df_all.reset_index() df_all_new['月销售额'] = df_all_new['月销售额'].apply(lambda x:str(x)) fig = plt.figure() plt.rcParams['font.sans-serif'] = ['SimHei'] n, bins, patches = plt.hist(df['月销售额'], bins = range(8, 37, 4), edgecolor = 'black', linewidth = 0.5) # 按指定的端点值划分区间 plt.xticks(bins) plt.title('月销售额频率分析') plt.xlabel('月销售额') plt.ylabel('频数') app = xw.App(visible = False) workbook = app.books.open('描述统计.xlsx') worksheet = workbook.sheets['业务员销售额统计表'] worksheet.range('E2').value = df_describe worksheet.range('H2').value = df_all_new worksheet.pictures.add(fig, name = '图片1', update = True, left = 400, top = 200) worksheet.autofit() workbook.save('描述统计2.xlsx') workbook.close() app.quit()运行结果:
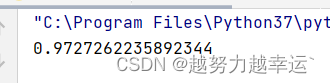
注意:因为range()函数具有”左闭右开“的特性,所以这里将终止值(第2个参数)设置得比36大一些,否则生成的序列只到32为止,这样会导致无法将最大值32.56统计在内。 案例10 使用回归分析预测未来值——回归分析.xlsx import pandas as pd from sklearn import linear_model # 导入sklearn模块 df = pd.read_excel('回归分析.xlsx', header = None) # 读取指定工作簿中的数据 df = df[2:] # 删除前两行数据 df.columns = ['月份', '电视台广告费', '视频门户广告费', '汽车当月销售额'] # 重命名数据列 x = df[['视频门户广告费', '电视台广告费']] # 获取'视频门户广告费', '电视台广告费'列的数据作为自变量 y = df['汽车当月销售额'] # 获取“汽车当月销售额”列的数据作为因变量 model = linear_model.LinearRegression() # 创建一个线性回归模型 model.fit(x, y) # 用自变量和因变量数据对线性回归模型进行训练,拟合出线性回归方程 R2 = model.score(x, y) # 计算R^2值 print(R2)运行结果,R^2的值
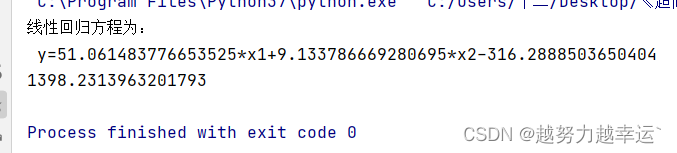
R^2的取值范围0~1,越接近1,说明方程的拟合程度越高。这里计算出的R^2值比较接近1,说明方程的拟合程度较高,可以用此方程来预测。 知识延伸 1、LinearRegression()是sklearn模块中的函数,用于创建一个线性回归模型。 语法格式: LinearRegression(fit_intercept=True,normalize=False,copy_X=True,n_jobs=1) 参数说明fit_intercept可选参数,表示是否需要计算截距,默认值为Truenormalize可选参数,表示是否对数据进行标准化处理,默认值为Falsecopy_X可选参数,默认值为True,表示复制X值。如果为False,表示该值可能被覆盖n_jobs可选参数,表示计算时使用 的CPU数量,默认值为12、score()是sklearn模块中的函数,用于计算回归模型的R^2值。 语法格式: score(x,y,sample_weight=None) 使用回归方程计算预测值——回归分析.xlsx 假设某月在电视台和视频用户分别投入了20万元和30万元广告费,要预测该月的汽车销售额。 import pandas as pd from sklearn import linear_model df = pd.read_excel('回归分析.xlsx', header = None) df = df[2:] df.columns = ['月份', '电视台广告费', '视频门户广告费', '汽车当月销售额'] x = df[['视频门户广告费', '电视台广告费']] y = df['汽车当月销售额'] model = linear_model.LinearRegression() model.fit(x,y) coef = model.coef_ # 获取自变量的系数 model_intercept = model.intercept_ # 获取截距 result = 'y={}*x1+{}*x2{}'.format(coef[0], coef[1], model_intercept) # 获取线性回归方程 print('线性回归方程为:', '\n', result) # 输出线性回归方程 a = 30 # 设置视频门户广告费 b = 20 # 设置电视台广告费 y = coef[0] * a + coef[1] * b + model_intercept # 根据线性回归方程计算汽车销售额 print(y) # 输出计算的汽车销售额运行结果如下。说明在视频用户和电视台分别投入30万和20万元的广告费时,汽车销售额预测值为1398.2万元。
使用Python批量进行数据分析,这些案例中使用到的数据文件请点击这里【免费】使用Python批量进行数据分析使用到的数据.zip资源-CSDN文库 |
【本文地址】
今日新闻 |
推荐新闻 |