stata工具变量法:使用2SLS进行ivreg2估计及其检验 |
您所在的位置:网站首页 › stata相关分析显著性水平怎么看 › stata工具变量法:使用2SLS进行ivreg2估计及其检验 |
stata工具变量法:使用2SLS进行ivreg2估计及其检验
|
转自:https://my.oschina.net/u/4606941/blog/4477407 作为OLS回归不符合假定的问题,还包括解释变量与随机扰动项不相关。如果出现了违反该假设(即解释变量和随机扰动项相关了)的问题,就需要找一个和解释变量高度相关的、同时和随机扰动项不相关的变量,作为工具变量进行回归。 传统来讲,工具变量有两个要求:与内生变量高度相关、与误差项不相关,这两个要求缺一不可。前者的违背会导致弱工具,这其中一个更有意思的问题是有很多的弱工具(many weak instruments)的情况。而后者的违背会使得工具变的无效(Invalid)。 工具变量通常采用二阶段最小二乘法(2SLS)进行回归,当随机扰动项存在异方差或自相关的问题,2SLS就不是有效率的,就需要用GMM等方法进行估计,除此之外还需要对工具变量的弱工具性和内生性进行检验。 sysuse auto 构造工具变量结构方程初始回归方程:mpg = β0+β1turn+β2gear_ratio+μ 内生变量:turn=z0+z1weight+z2length+z3headroom+ε 回归方程中内生变量为turn,工具变量为weight、length、headroom。 2SLS估计 1.使用 ivreg2 进行2SLS估计ivreg2 mpg gear_ratio (turn=weight length headroom) 这里运行时出现错误提示:
Underidentification test,方程的不可识别检验详解,得到LM统计值为26.822,p值=0.000,小于0.05,强烈拒绝“不可识别”的原假设。 Weak identification test弱工具变量检验详解,得到得到Wald-F统计值为30.303,KP Wald-F统计值为42.063,大于所有临界值,说明拒绝“弱工具变量”的原假设,即方程不存在弱工具变量。 Hansen J statistic的过度识别检验详解,得到卡方统计值为0.548,p值为0.7601,大于0.05,说明接受“过度拟合”的原假设;【Hansen J统计量,加选项robust时汇报Hansen J统计量,不加robust选项时汇报Sargan统计量。也就是说iid时用Sargan统计量,非iid时用Hansen J统计量。】 如果是恰好识别,是不用做过度识别检验的。如果工具变量个数多于内生变量个数,且确定其中一个工具变量外生,就可以进行过度识别检验。过度识别检验p值大于0.1,则不拒绝 所有工具变量均外生 的原假设。 Sargan+Hansen:过度识别检验及Stata实现 在计量经济学方法研究以及应用中,一般需要恰好识别或者过度识别,虽然过度识别的情况比较多一些,另外这是进行工具变量法的必要条件;若是出现过度识别,则需要进行过度识别检验,也成为萨尔干巴斯曼检验,写作Sargan-Basman检验。 该假设的条件为所有有效的工具变量的个数与内生解释变量一样多,或者说是这个所有的工具变量都是外生的。 过度识别的命令为estat overid 若是Sargan-Basman检验的统计量对应的p值大于0.05,则认为所有的工具变量都是外生的,也就是有效的,反之则是无效的。(原假设是所有工具变量是外生的,若是p值小于0.05,则拒绝原假设) 总结:过度识别检验其实一部分是为了检验工具变量的外生性,主要体现在检验工具变量是否与扰动项的相关性,即与扰动项不相关。 过度内生性检验 ivreg2 mpg gear_ratio (turn=weight length headroom) estimates store iv regress mpg gear_ratio turn weight length headroom estimates store ols hausman iv ols, constant sigmamore
Hausman检验得到统计值为-0.97,无法拒绝“所有解释变量均为外生”的原假设,说明方程存在内生性。
注释: 用IV做2SLS回归时,需要对IV进行三个方面的检验: 1.不可识别检验,也就是 IV的个数是否少于内生解释变量的个数,使用的统计量是Anderson LM 统计量/Kleibergen-Paap rk LM统计量。这里 p值小于0.01说明在 1%水平上【说明错误拒绝的可能性小于1%】显著拒绝 “工具变量识别不足”的原假设,也就是要求p值不能大于0.1。 加robust是Kleibergen-Paap rk LM统计量,不加robust是Anderson LM 统计量。也就是说在iid(独立同分布)情况下看Anderson LM 统计量,在非iid情况下看Kleibergen-Paap rk LM统计量。 2.弱IV检验,弱IV是指IV与内生解释变量的相关性不强,微弱相关,**弱IV会导致用IV估计的结果与用OLS,FE估计的结果相差很大,甚至符号完全相反。** 如果有较多工具变量,可舍弃弱工具变量,因为 **多余的弱工具变量反而会降低第一阶段回归的F统计量**。 弱IV的判断有以下四个标准: (1)偏R2,也就是**Shea's partial R2**,不过xtivreg2不汇报这个统计量,得用命令estat firststage, all forcenonrobust ,汇报第一阶段的结果。 (2)最小特征统计量,minimum eigenvalue statistic,这是Stock and Yogo (2005)提出来的,stata会在ivreg2中给出临界值。Staiger and Stock (1997)建议只要该值大于10就认为不存在弱IV。这个值用于iid的情况。 (3)Cragg-Donald Wald F统计量,由Cragg and Donald (1993)提出,Stock and Yogo (2005)给出其临界值,Stata在回归时会给出临界值。CDW检验一般过15%,10%的临界值就可以,过了5%的临界值更好。 名义显著性水平为5%的检验,其真实显著性水平不超过15%。也就是Stock-Yogo weak ID test critical values的15%相当于5%,也就是说要求CDW统计量大于15%的临界值就行。 如果IV数量小于3则不会给出Stock-Yogo weak ID test critical values: 5%/10%/15%/20% maximal IV relative bias 。如果假设扰动项为iid,则看CDW检验统计量。如果不对扰动项作iid的假设,则看KP W rk F统计量。所以加r选项时才有KP W rk F统计量,不加则没有。不管加不加r选项,CDW统计量总有。通常建议加上r选项。 (4)Kleibergen-Paap Wald rk F统计量,Stock and Yogo (2005)给出其临界值,Stata在回归时会给出临界值。注意与不可识别检验的统计量的区别。对于CDW统计量和KP W rk F统计量要从估计偏误和检验水平扭曲两个方面进行判断是否存在弱IV问题。 一般情况下这四个值都会看,基本上几个值都是同向变化的。 3.过度识别检验,过度识别的前提是该模型至少是恰好识别的,也就是有效IV至少与内生解释变量一样多,**原假设是H0:所有IV都是外生的,拒绝原假设意味着至少有一个IV不是外生的,与扰动项相关**。三个统计量: (1)Sargan统计量。Stata默认给出Sargan统计量。如果内生变量的数目和工具变量的数目完全相同。此时无需执行过度识别检验,因为模型是恰足确认的(equation exactly identified)。这里要求p大于0.1。(2)Hansen J统计量,加选项robust时汇报Hansen J统计量,不加robust选项时汇报Sargan统计量。也就是说iid时用Sargan统计量,非iid时用Hansen J统计量。 (3)C统计量,加orthog(varlist),varlist为需要检验外生性的变量。与过度识别约束检验有关的另一个检验是对工具变量子集是否符合外生性假定的检验,可通过 difference-in-Sargan 统计量进行; 该统计量由两个 Sargan( 或 Hansen-J) 之差构成,也称为 C 统计量。 在xtivreg和xtivreg2后面还可加first和ffirst选项,如果选择first,窗口中就会直接显示first-stage的regression output;如果选择ffirst,则会显示first-stage中检测IV的相关性等的test statistics。 |
 原因:括号前面要有个空格。
原因:括号前面要有个空格。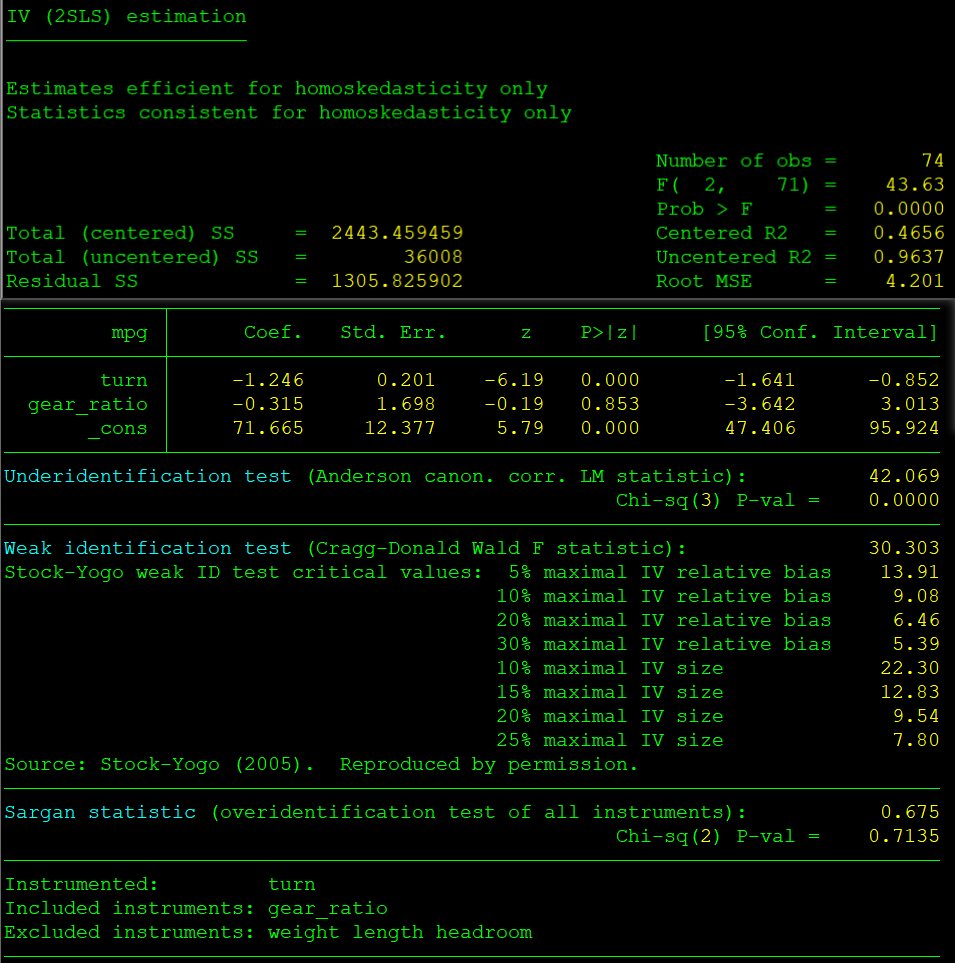 结果显示:
turn变量的估计系数是-1.246,z检验值为-6.33,p值0.000,小于0.05,说明turn系数显著,且与mpg呈现负相关。
结果显示:
turn变量的估计系数是-1.246,z检验值为-6.33,p值0.000,小于0.05,说明turn系数显著,且与mpg呈现负相关。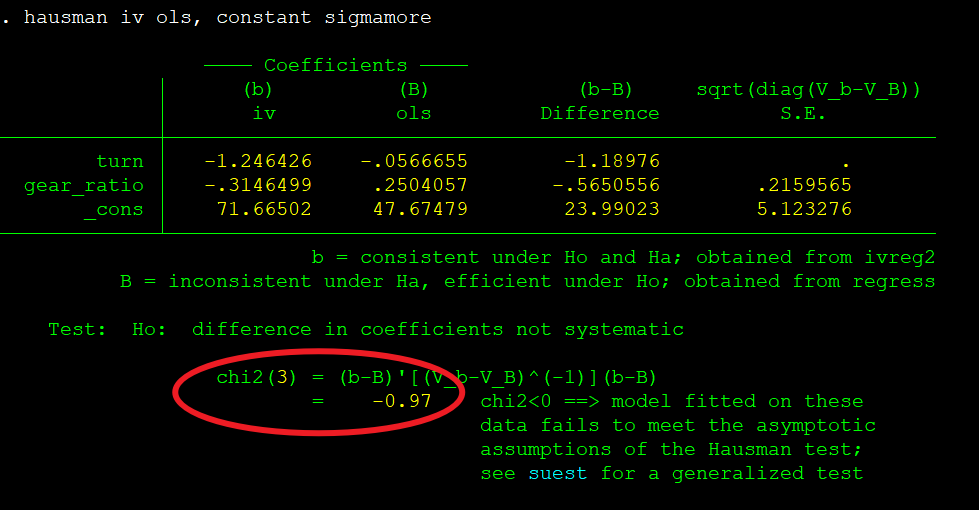
【本文地址】
今日新闻 |
推荐新闻 |