Stata:如何为区县名称添加行政区划代码 |
您所在的位置:网站首页 › stata怎么编码 › Stata:如何为区县名称添加行政区划代码 |
Stata:如何为区县名称添加行政区划代码
|
在之前的课程「如何整理 2022 年县域统计年鉴:caj 文件转 pdf、文本识别与数据清洗」中我们讲解了如何从 caj 文件中提取表格数据的方法,今天我们再来学习下如何根据区县名称匹配行政区划代码,另外在该过程中还可以检查区县名称的识别错误。最后我们再使用整理得到的数据绘制一幅区县地图。 首先我们使用上次课的代码处理“整理结果3.xlsx”: cd "~/Desktop/Stata:如何为区县名称添加行政区划代码" *- 处理 “整理结果3.xlsx”import excel using "整理结果3.xlsx", clear carryforward A, replace drop if missing(D) & missing(E) & missing(F) /// & missing(G) & missing(H) & missing(I) /// & missing(J) & missing(K) & missing(L)replace B = subinstr(B, " ", "", .)replace B = subinstr(B, ",", "", .)replace B = subinstr(B, "-", "", .)replace B = subinstr(B, ".", "", .)replace B = subinstr(B, "~", "", .)replace B = subinstr(B, "・", "", .)replace B = subinstr(B, ",", "", .)replace B = subinstr(B, "、", "", .)drop if B == "" | B == "一、基本情况行政区域面积" | B == "一基本情况行政区域面积"replace B = "提供住宿的民政服务机构床位数" if /// inlist(B, "提供住宿的民政0艮务机构床位数", /// "提供住宿的民政服务机构床位数", /// "提供住宿的民谢艮务机构床位数")replace B = "提供住宿的民政服务机构" if /// inlist(B, "提供住宿的民呦艮务机构", /// "提供住宿的民政^务机构", /// "提供住宿的民斑艮务机构", /// "提供住宿的民班艮务机构")drop C gen z = _n if B == "指标"order z carryforward z, replacegather D - L spread B value order z A 指标 drop if missing(指标) drop var destring, replace *- 删除辅助变量 zdrop z ren A 省ren 指标 县order 省 县 行政区域面积 乡 镇 街道办事处 户籍人口 /// 地区生产总值 第一产业增加值 第二产业增加值 第三产业增加值 /// 地方一般公共预算收入 地方一般公共预算支出 住户存款余额 /// 年末金融机构各项贷款余额 设施农业种植占地面积 油料产量 /// 棉花产量 规模以上工业企业 固定电话用户 普通中学在校学生 /// 小学在校学生 医疗卫生机构床位 提供住宿的民政服务机构 /// 提供住宿的民政服务机构床位数*- 紧凑数据foreach i of varlist _all { cap format `i' %10s}save data4, replace由于之前我分享的县域统计年鉴数据都是使用的 2020 年行政区划代码,所以这次我们也同样。 2020 年行政区划代码可以从地理矢量数据得到(为了方便绘制地图): *- 由于之前的县域数据都是使用的 2020 年行政区划代码,所以这次我们依然使用 2020 的:shp2dta using "2020行政区划/县.shp", database(countydb) coordinates(countycoord) replace use countydb, clear keep 省 省代码 市 市代码 县 县代码 order 省 省代码 市 市代码 县 县代码 *- 查看 省-县 的组合有无重复的duplicates tag 省 县, gen(tags) gsort -tags *- 这些重复的可能会影响下一步的匹配,所以先删除了drop if tags > 0 drop tagssave countycode1, replace首先匹配下看看能成功多少: use data4, clear merge 1:1 省 县 using countycode1 *> Result Number of obs*> -----------------------------------------*> Not matched 1,116*> from master 171 (_merge==1)*> from using 945 (_merge==2)*> *> Matched 1,917 (_merge==3)*> -----------------------------------------*- 检查没有匹配成功的keep if _m == 1可以看到很多是由于空格和杂乱字符导致的匹配失败,所以我们先去除: use data4, clear replace 县 = subinstr(县, " ", "", .)replace 县 = subinstr(县, ";", "", .)replace 县 = subinstr(县, ":", "", .)merge 1:1 省 县 using countycode1 keep if _m == 1*> Result Number of obs*> -----------------------------------------*> Not matched 946*> from master 86 (_merge==1)*> from using 860 (_merge==2)*> *> Matched 2,002 (_merge==3)*> -----------------------------------------可以看到这个时候匹配不成功的(_merge==1)就不是很多了,下面我们需要结合百度和 countycode1.dta 来逐个检查修正:
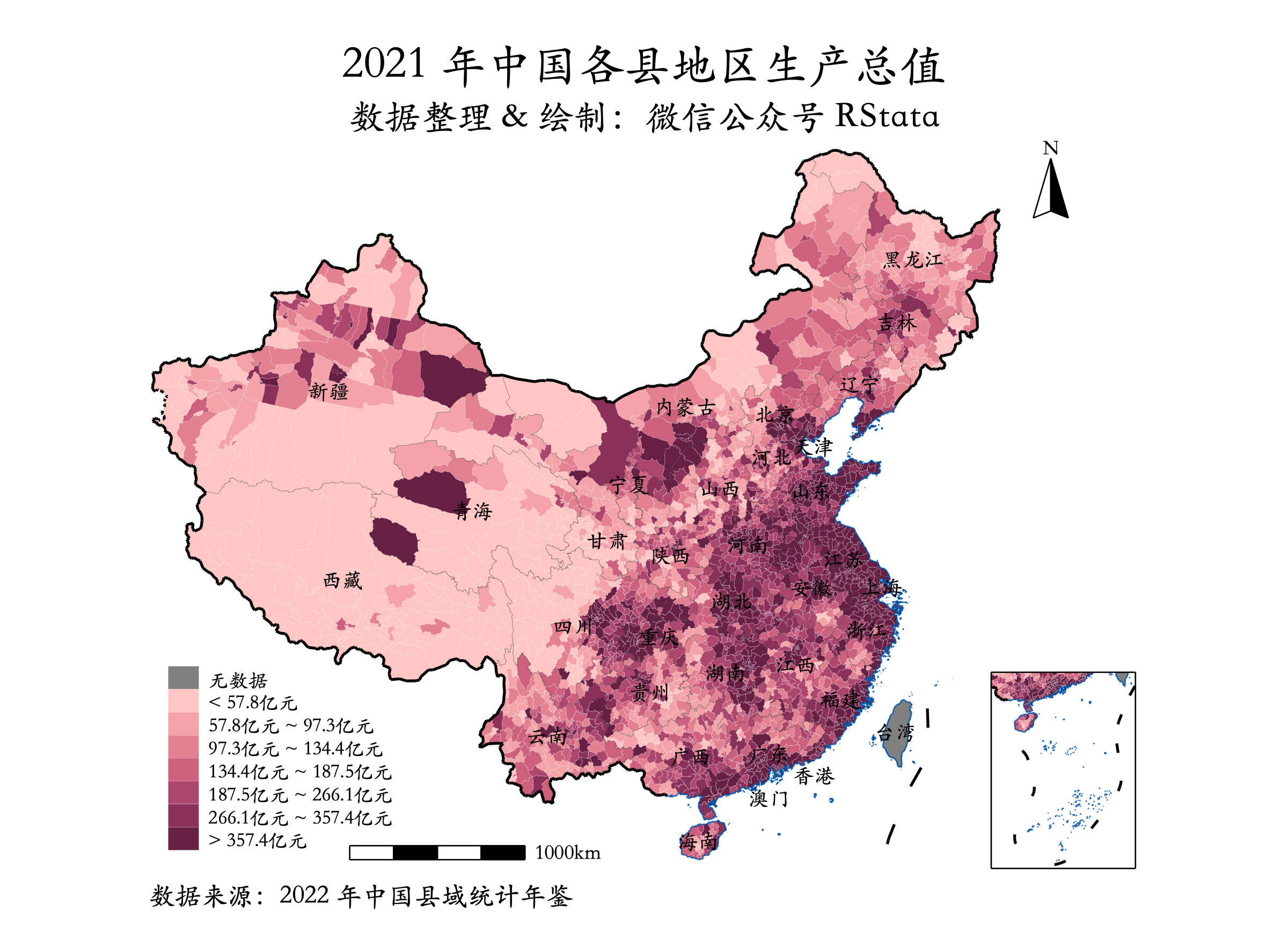
然后重新匹配试试: *- 重新匹配试试use data4, clear replace 县 = subinstr(县, " ", "", .)replace 县 = subinstr(县, ";", "", .)replace 县 = subinstr(县, ":", "", .)replace 省 = "江苏省" if 县 == "浦口区"replace 县 = "勐腊县" if 县 == "^腊县"replace 县 = "勐海县" if 县 == "劭海县"replace 县 = "双江拉祜族佤族布朗族傣族自治县" if 县 == "双江拉祜族值族布朗族傣族自治县"*- 此处省略部分代码,详情可以参考附件中的 main.do replace 县 = "大箐山县" if 县 == "大箸山县"merge 1:1 省 县 using countycode1 order 省 省代码 市 市代码 县 县代码 keep if _m == 3drop _m destring 县代码, replace save data5, replace然后我们再对变量进行重命名(和之前年份的保持一致): use data5, clear gen 年份 = 2021 replace 乡 = 0 if missing(乡)replace 镇 = 0 if missing(镇)gen 乡镇个数_个 = 乡 + 镇ren 乡 乡_个ren 镇 镇_个ren 行政区域面积 行政区域土地面积_平方公里ren 街道办事处 街道办事处个数_个ren 户籍人口 户籍人口_人ren 地区生产总值 国内生产总值_万元ren 第一产业增加值 第一产业增加值_万元ren 第二产业增加值 第二产业增加值_万元ren 第三产业增加值 第三产业增加值_万元ren 地方一般公共预算收入 一般公共预算收入_万元ren 地方一般公共预算支出 一般公共预算支出_万元ren 住户存款余额 住户储蓄存款余额_万元ren 年末金融机构各项贷款余额 年末各项贷款余额_万元ren 设施农业种植占地面积 设施农业占地面积_公顷ren 油料产量 油料产量_吨ren 棉花产量 棉花产量_吨ren 规模以上工业企业 规模以上工业企业个数_个ren 固定电话用户 固定电话用户_户ren 普通中学在校学生 普通中学在校学生_人ren 小学在校学生 小学在校学生数_人ren 医疗卫生机构床位 医疗卫生机构床位_床ren 提供住宿的民政服务机构 提供住宿的社会工作机构_个ren 提供住宿的民政服务机构床位数 提供住宿的社会工作机构床位_床label data "整理:微信公众号 RStata"save "2021年县市社会经济指标.dta", replace最后如果你想把该数据和之前年份的合并起来,只需要 use 之前年份的数据,然后 append using "2021年县市社会经济指标.dta" 即可。 最后我们再使用该数据绘制一幅区县地图: *- 把 “2021年县市社会经济指标.dta” 文件放到 “使用Stata绘制中国县级地图(版本2020mini)” 文件夹里面:cd "使用Stata绘制中国县级地图(版本2020mini)"use chinacounty2020mini_db.dta, clear destring 县代码, replace merge 1:1 省 省代码 市 市代码 县 县代码 using 2021年县市社会经济指标.dtareplace 国内生产总值_万元 = 国内生产总值_万元/10000*- 市辖区的值使用该城市的平均值代替bysort 省 省代码 市 市代码: egen mean = mean(国内生产总值_万元)replace 国内生产总值_万元 = mean if missing(国内生产总值_万元) *- 仍然缺失的使用该省的均值代替bysort 省 省代码 : egen mean2 = mean(国内生产总值_万元)replace 国内生产总值_万元 = mean2 if missing(国内生产总值_万元) *- 仍然缺失的替换成 -1 replace 国内生产总值_万元 = -1 if missing(国内生产总值_万元) *- 绘图*- 农林牧渔业人口占比 nicecut 国内生产总值_万元, n(8) unit(亿元) grmap 国内生产总值_万元 using chinacounty2020mini_coord.dta, /// id(ID) osize(vvthin ...) ocolor(white ...) /// clmethod(custom) clbreaks(`r(cutpoints)') /// fcolor(gray "255 198 196" "244 163 168" "227 129 145" /// "204 96 125" "173 70 108" "139 48 88" "103 32 68") /// graphr(margin(medium)) /// leg(order(`r(legorder)')) /// line(data(chinaprov2020mini_line_coord2.dta) by(group) /// size(vvthin *1 *0.5 *0.5 *0.5) pattern(solid ...) /// select(drop if inlist(group, 4, 7)) /// color(gs20 /// 省界颜色 black /// 国界线颜色 "0 85 170" /// 海岸线颜色 black /// 小地图框格颜色 black /// 比例尺和指北针颜色 )) /// polygon(data(polygon2) fcolor(black) /// osize(vvthin)) /// label(data(chinacounty2020mini_label2) x(X) y(Y) label(cname) length(20) size(*0.8)) /// ti("2021 年中国各县地区生产总值") /// subti("数据整理 & 绘制:微信公众号 RStata") /// caption("数据来源:2022 年中国县域统计年鉴", size(*0.8))gr export "2021年中国各县地区生产总值.png", replace width(2400)
|
【本文地址】
今日新闻 |
推荐新闻 |