如何在 Stata 中进行数据形态转换?用10个示例掌握 reshape 命令 |
您所在的位置:网站首页 › stata中ttest怎么用 › 如何在 Stata 中进行数据形态转换?用10个示例掌握 reshape 命令 |
如何在 Stata 中进行数据形态转换?用10个示例掌握 reshape 命令
|
本文是对 reshape 命令的介绍,力图通过 10 个示例全面介绍该命令。本文所用数据主要来自 Stata 的数据管理手册([D] Stata Data Management Reference Manual)和 Mitchell 的教材(Data management using Stata: a practical handbook),前者为网络数据可直接载入,后者为作者提供的数据集,可从文末 “补充材料” 处获取。 在数据分析中, 我们所获取的数据集通常具有不同的形态(form),具体有长形(long form)和宽形(wide form)两种(见下方图1和图2)。出于数据分析的需要(尤其是面板数据分析和多层次回归分析),不同形态的数据集各有其用,能够得其一而转换为另一形态便具有很强的实用性。 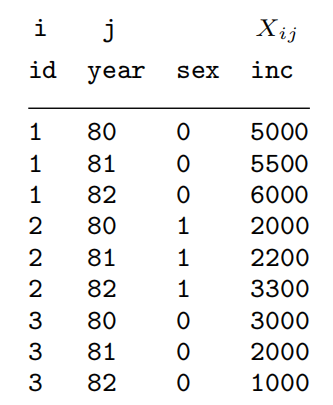 图1. 长形数据(long form) 图1. 长形数据(long form) 图2. 宽形数据(wide form) 图2. 宽形数据(wide form)使用 Stata 进行数据处理十分便捷,其中的reshape 命令就是用于实现数据形态之转换的,即 Convert data from wide to long form and vice versa。不论哪种数据形态,数据集中均包含两种形态下的全部信息,区别在于数据呈现的方式。 本文是对 reshape 命令的介绍,力图通过10个示例全面介绍该命令的使用方式以及需要注意的问题。 基本语法代码语言:txt复制/* 命令语法结构: reshape long stubnames, i(varlist) [options] reshape wide stubnames, i(varlist) [options] 说明: i(varlist) - use varlist as the ID variables i(varlist) is required j(varname [values]) long → wide: varname, existing variable wide → long: varname, new variable takes a variable name or a variable name and a list of values */ 示例 1:快速上手代码语言:javascript复制clear
set more off
capture log close
global root = "..." //设定一个存放数据的根目录
use "https://www.stata-press.com/data/r17/reshape1", clear
des
list
reshape long inc ue, i(id) j(year) //该数据集是一个 wide 形,将其转换成 long 形数据
list, sep(3)
reshape wide inc ue, i(id) j(year) //同理,把转换后的数据集转回 wide 形
list
generate id = _n //没有ID变量时可以创建一个示例 2:i 不唯一时由 wide 转 long (报错)代码语言:javascript复制use "https://www.stata-press.com/data/r17/reshape2", clear
list
/*
+----------------------------------+
| id sex inc80 inc81 inc82 |
|----------------------------------|
1. | 1 0 5000 5500 6000 |
2. | 2 1 2000 2200 3300 |
3. | 3 0 3000 2000 1000 |
4. | 2 0 2400 2500 2400 |
+----------------------------------+
*/
reshape long inc, i(id) j(year) //执行转换后结果如下,会用红色字体报错
/*
(j = 80 81 82)
variable id does not uniquely identify the observations
Your data are currently wide. You are performing a reshape long. You specified i(id) and j(year). In the current wide
form, variable id should uniquely identify the observations. Remember this picture:
long wide
+---------------+ +------------------+
| i j a b | | i a1 a2 b1 b2 |
|---------------| |------------------|
| 1 1 1 2 | | 1 1 3 2 4 |
| 1 2 3 4 | | 2 5 7 6 8 |
| 2 1 5 6 | +------------------+
| 2 2 7 8 |
+---------------+
Type reshape error for a list of the problem observations.
*/
reshape error //定位错误的原因为:2 of 4 observations have duplicate i values
/*
+----+
| id |
|----|
2. | 2 |
3. | 2 |
+----+
*/示例 3:j 不唯一时由 long 转 wide (报错)代码语言:javascript复制use "https://www.stata-press.com/data/r17/reshapexp1", clear
list
/*
+------------------------+
| id year sex inc |
|------------------------|
1. | 1 80 0 5000 |
2. | 1 81 0 5500 |
3. | 1 81 0 5400 |
4. | 1 82 0 6000 |
+------------------------+
*/
reshape wide inc, i(id) j(year) //执行转换后结果如下,会用红色字体报错
/*
values of variable year not unique within id
Your data are currently long. You are performing a reshape wide. You specified i(id) and j(year). There are observations
within i(id) with the same value of j(year). In the long data, variables i() and j() together must uniquely identify the
observations.
long wide
+---------------+ +------------------+
| i j a b | | i a1 a2 b1 b2 |
|---------------| |------------------|
| 1 1 1 2 | | 1 1 3 2 4 |
| 1 2 3 4 | | 2 5 7 6 8 |
| 2 1 5 6 | +------------------+
| 2 2 7 8 |
+---------------+
Type reshape error for a list of the problem variables.
*/
reshape error //2 of 4 observations have repeated year values
/*
+-----------+
| id year |
|-----------|
2. | 1 81 |
3. | 1 81 |
+-----------+
*/示例 4:long 转 wide 时未设定变量(报错)代码语言:javascript复制use "https://www.stata-press.com/data/r17/reshape6", clear
list, sepby(id)
/*
+-----------------------------+
| id year sex inc ue |
|-----------------------------|
1. | 1 80 0 5000 0 |
2. | 1 81 0 5500 1 |
3. | 1 82 0 6000 0 |
|-----------------------------|
4. | 2 80 1 2000 1 |
5. | 2 81 1 2200 0 |
6. | 2 82 1 3300 0 |
|-----------------------------|
7. | 3 80 0 3000 0 |
8. | 3 81 0 2000 0 |
9. | 3 82 0 1000 1 |
+-----------------------------+
*/
reshape wide inc, i(id) j(year) //ue 变量未设定
/*
variable ue not constant within id
Your data are currently long. You are performing a reshape wide. You typed something like
. reshape wide a b, i(id) j(year)
There are variables other than a, b, id, year in your data. They must be constant within id because that is the only way
they can fit into wide data without loss of information.
The variable or variables listed above are not constant within id. Perhaps the values are in error. Type reshape error
for a list of the problem observations.
Either that, or the values vary because they should vary, in which case you must either add the variables to the list of
xij variables to be reshaped, or drop them.
*/
reshape wide inc ue, i(id) j(year) //正确的设定
list
/*
+-------------------------------------------------------+
| id inc80 ue80 inc81 ue81 inc82 ue82 sex |
|-------------------------------------------------------|
1. | 1 5000 0 5500 1 6000 0 0 |
2. | 2 2000 1 2200 0 3300 0 1 |
3. | 3 3000 0 2000 0 1000 1 0 |
+-------------------------------------------------------+
*/示例 5:wide 转 long 时变量未设定代码语言:javascript复制use "https://www.stata-press.com/data/r17/reshape1", clear
list
/*
+-------------------------------------------------------+
| id sex inc80 inc81 inc82 ue80 ue81 ue82 |
|-------------------------------------------------------|
1. | 1 0 5000 5500 6000 0 1 0 |
2. | 2 1 2000 2200 3300 1 0 0 |
3. | 3 0 3000 2000 1000 0 0 1 |
+-------------------------------------------------------+
*/
reshape long inc, i(id) j(year) //注意!结果是错误的,但是未报错
list, sepby(id)
/*
+---------------------------------------------+
| id year sex inc ue80 ue81 ue82 |
|---------------------------------------------|
1. | 1 80 0 5000 0 1 0 |
2. | 1 81 0 5500 0 1 0 |
3. | 1 82 0 6000 0 1 0 |
|---------------------------------------------|
4. | 2 80 1 2000 1 0 0 |
5. | 2 81 1 2200 1 0 0 |
6. | 2 82 1 3300 1 0 0 |
|---------------------------------------------|
7. | 3 80 0 3000 0 0 1 |
8. | 3 81 0 2000 0 0 1 |
9. | 3 82 0 1000 0 0 1 |
+---------------------------------------------+
*/
reshape wide //to undo the unwanted change and then try again
reshape long inc ue, i(id) j(year)
list, sepby(id)
/*
+-----------------------------+
| id year inc sex ue |
|-----------------------------|
1. | 1 80 5000 0 0 |
2. | 1 81 5500 0 1 |
3. | 1 82 6000 0 0 |
|-----------------------------|
4. | 2 80 2000 1 1 |
5. | 2 81 2200 1 0 |
6. | 2 82 3300 1 0 |
|-----------------------------|
7. | 3 80 3000 0 0 |
8. | 3 81 2000 0 0 |
9. | 3 82 1000 0 1 |
+-----------------------------+
*/示例 6:wide 转 long 时变量缺失下的转换代码语言:javascript复制use "https://www.stata-press.com/data/r17/reshape1", clear
drop ue81
list
/*
+------------------------------------------------+
| id sex inc80 inc81 inc82 ue80 ue82 |
|------------------------------------------------|
1. | 1 0 5000 5500 6000 0 0 |
2. | 2 1 2000 2200 3300 1 0 |
3. | 3 0 3000 2000 1000 0 1 |
+------------------------------------------------+
*/
reshape long inc ue, i(id) j(year) //reshape placed missing values where ue81 values were unavailable
list, sepby(id)
/*
+-----------------------------+
| id year sex inc ue |
|-----------------------------|
1. | 1 80 0 5000 0 |
2. | 1 81 0 5500 . |
3. | 1 82 0 6000 0 |
|-----------------------------|
4. | 2 80 1 2000 1 |
5. | 2 81 1 2200 . |
6. | 2 82 1 3300 0 |
|-----------------------------|
7. | 3 80 0 3000 0 |
8. | 3 81 0 2000 . |
9. | 3 82 0 1000 1 |
+-----------------------------+
*/
reshape wide inc ue, i(id) j(year) //the ue81 variable would be created and would contain all missing values
list
/*
+-------------------------------------------------------+
| id inc80 ue80 inc81 ue81 inc82 ue82 sex |
|-------------------------------------------------------|
1. | 1 5000 0 5500 . 6000 0 0 |
2. | 2 2000 1 2200 . 3300 0 1 |
3. | 3 3000 0 2000 . 1000 1 0 |
+-------------------------------------------------------+
*/示例 7:wide 转 long 时变量的命名代码语言:javascript复制use "https://www.stata-press.com/data/r17/reshape3", clear
list
/*
+----------------------------------------------------------+
| id sex inc80r inc81r inc82r ue80 ue81 ue82 |
|----------------------------------------------------------|
1. | 1 0 5000 5500 6000 0 1 0 |
2. | 2 1 2000 2200 3300 1 0 0 |
3. | 3 0 3000 2000 1000 0 0 1 |
+----------------------------------------------------------+
*/
reshape long inc@r ue, i(id) j(year) //@ characters to indicate where the numbers go
list, sepby(id)
/*
+-----------------------------+
| id year sex incr ue |
|-----------------------------|
1. | 1 80 0 5000 0 |
2. | 1 81 0 5500 1 |
3. | 1 82 0 6000 0 |
|-----------------------------|
4. | 2 80 1 2000 1 |
5. | 2 81 1 2200 0 |
6. | 2 82 1 3300 0 |
|-----------------------------|
7. | 3 80 0 3000 0 |
8. | 3 81 0 2000 0 |
9. | 3 82 0 1000 1 |
+-----------------------------+
*/
use "https://www.stata-press.com/data/r17/reshape3", clear
reshape long inc@r ue@, i(id) j(year) //与上面的转换命令等价,充分掌握 @ 字符的作用
list //结果与上面一致
reshape wide inc@r ue, i(id) j(year) //may similarly be used for converting data from long to wide format
list //注意转换后与原始数据集中变量的顺序是不一致的
/*
+----------------------------------------------------------+
| id inc80r ue80 inc81r ue81 inc82r ue82 sex |
|----------------------------------------------------------|
1. | 1 5000 0 5500 1 6000 0 0 |
2. | 2 2000 1 2200 0 3300 0 1 |
3. | 3 3000 0 2000 0 1000 1 0 |
+----------------------------------------------------------+
*/ 示例 1:快速上手代码语言:javascript复制clear
set more off
capture log close
global root = "..." //设定一个存放数据的根目录
use "https://www.stata-press.com/data/r17/reshape1", clear
des
list
reshape long inc ue, i(id) j(year) //该数据集是一个 wide 形,将其转换成 long 形数据
list, sep(3)
reshape wide inc ue, i(id) j(year) //同理,把转换后的数据集转回 wide 形
list
generate id = _n //没有ID变量时可以创建一个示例 2:i 不唯一时由 wide 转 long (报错)代码语言:javascript复制use "https://www.stata-press.com/data/r17/reshape2", clear
list
/*
+----------------------------------+
| id sex inc80 inc81 inc82 |
|----------------------------------|
1. | 1 0 5000 5500 6000 |
2. | 2 1 2000 2200 3300 |
3. | 3 0 3000 2000 1000 |
4. | 2 0 2400 2500 2400 |
+----------------------------------+
*/
reshape long inc, i(id) j(year) //执行转换后结果如下,会用红色字体报错
/*
(j = 80 81 82)
variable id does not uniquely identify the observations
Your data are currently wide. You are performing a reshape long. You specified i(id) and j(year). In the current wide
form, variable id should uniquely identify the observations. Remember this picture:
long wide
+---------------+ +------------------+
| i j a b | | i a1 a2 b1 b2 |
|---------------| |------------------|
| 1 1 1 2 | | 1 1 3 2 4 |
| 1 2 3 4 | | 2 5 7 6 8 |
| 2 1 5 6 | +------------------+
| 2 2 7 8 |
+---------------+
Type reshape error for a list of the problem observations.
*/
reshape error //定位错误的原因为:2 of 4 observations have duplicate i values
/*
+----+
| id |
|----|
2. | 2 |
3. | 2 |
+----+
*/示例 3:j 不唯一时由 long 转 wide (报错)代码语言:javascript复制use "https://www.stata-press.com/data/r17/reshapexp1", clear
list
/*
+------------------------+
| id year sex inc |
|------------------------|
1. | 1 80 0 5000 |
2. | 1 81 0 5500 |
3. | 1 81 0 5400 |
4. | 1 82 0 6000 |
+------------------------+
*/
reshape wide inc, i(id) j(year) //执行转换后结果如下,会用红色字体报错
/*
values of variable year not unique within id
Your data are currently long. You are performing a reshape wide. You specified i(id) and j(year). There are observations
within i(id) with the same value of j(year). In the long data, variables i() and j() together must uniquely identify the
observations.
long wide
+---------------+ +------------------+
| i j a b | | i a1 a2 b1 b2 |
|---------------| |------------------|
| 1 1 1 2 | | 1 1 3 2 4 |
| 1 2 3 4 | | 2 5 7 6 8 |
| 2 1 5 6 | +------------------+
| 2 2 7 8 |
+---------------+
Type reshape error for a list of the problem variables.
*/
reshape error //2 of 4 observations have repeated year values
/*
+-----------+
| id year |
|-----------|
2. | 1 81 |
3. | 1 81 |
+-----------+
*/示例 4:long 转 wide 时未设定变量(报错)代码语言:javascript复制use "https://www.stata-press.com/data/r17/reshape6", clear
list, sepby(id)
/*
+-----------------------------+
| id year sex inc ue |
|-----------------------------|
1. | 1 80 0 5000 0 |
2. | 1 81 0 5500 1 |
3. | 1 82 0 6000 0 |
|-----------------------------|
4. | 2 80 1 2000 1 |
5. | 2 81 1 2200 0 |
6. | 2 82 1 3300 0 |
|-----------------------------|
7. | 3 80 0 3000 0 |
8. | 3 81 0 2000 0 |
9. | 3 82 0 1000 1 |
+-----------------------------+
*/
reshape wide inc, i(id) j(year) //ue 变量未设定
/*
variable ue not constant within id
Your data are currently long. You are performing a reshape wide. You typed something like
. reshape wide a b, i(id) j(year)
There are variables other than a, b, id, year in your data. They must be constant within id because that is the only way
they can fit into wide data without loss of information.
The variable or variables listed above are not constant within id. Perhaps the values are in error. Type reshape error
for a list of the problem observations.
Either that, or the values vary because they should vary, in which case you must either add the variables to the list of
xij variables to be reshaped, or drop them.
*/
reshape wide inc ue, i(id) j(year) //正确的设定
list
/*
+-------------------------------------------------------+
| id inc80 ue80 inc81 ue81 inc82 ue82 sex |
|-------------------------------------------------------|
1. | 1 5000 0 5500 1 6000 0 0 |
2. | 2 2000 1 2200 0 3300 0 1 |
3. | 3 3000 0 2000 0 1000 1 0 |
+-------------------------------------------------------+
*/示例 5:wide 转 long 时变量未设定代码语言:javascript复制use "https://www.stata-press.com/data/r17/reshape1", clear
list
/*
+-------------------------------------------------------+
| id sex inc80 inc81 inc82 ue80 ue81 ue82 |
|-------------------------------------------------------|
1. | 1 0 5000 5500 6000 0 1 0 |
2. | 2 1 2000 2200 3300 1 0 0 |
3. | 3 0 3000 2000 1000 0 0 1 |
+-------------------------------------------------------+
*/
reshape long inc, i(id) j(year) //注意!结果是错误的,但是未报错
list, sepby(id)
/*
+---------------------------------------------+
| id year sex inc ue80 ue81 ue82 |
|---------------------------------------------|
1. | 1 80 0 5000 0 1 0 |
2. | 1 81 0 5500 0 1 0 |
3. | 1 82 0 6000 0 1 0 |
|---------------------------------------------|
4. | 2 80 1 2000 1 0 0 |
5. | 2 81 1 2200 1 0 0 |
6. | 2 82 1 3300 1 0 0 |
|---------------------------------------------|
7. | 3 80 0 3000 0 0 1 |
8. | 3 81 0 2000 0 0 1 |
9. | 3 82 0 1000 0 0 1 |
+---------------------------------------------+
*/
reshape wide //to undo the unwanted change and then try again
reshape long inc ue, i(id) j(year)
list, sepby(id)
/*
+-----------------------------+
| id year inc sex ue |
|-----------------------------|
1. | 1 80 5000 0 0 |
2. | 1 81 5500 0 1 |
3. | 1 82 6000 0 0 |
|-----------------------------|
4. | 2 80 2000 1 1 |
5. | 2 81 2200 1 0 |
6. | 2 82 3300 1 0 |
|-----------------------------|
7. | 3 80 3000 0 0 |
8. | 3 81 2000 0 0 |
9. | 3 82 1000 0 1 |
+-----------------------------+
*/示例 6:wide 转 long 时变量缺失下的转换代码语言:javascript复制use "https://www.stata-press.com/data/r17/reshape1", clear
drop ue81
list
/*
+------------------------------------------------+
| id sex inc80 inc81 inc82 ue80 ue82 |
|------------------------------------------------|
1. | 1 0 5000 5500 6000 0 0 |
2. | 2 1 2000 2200 3300 1 0 |
3. | 3 0 3000 2000 1000 0 1 |
+------------------------------------------------+
*/
reshape long inc ue, i(id) j(year) //reshape placed missing values where ue81 values were unavailable
list, sepby(id)
/*
+-----------------------------+
| id year sex inc ue |
|-----------------------------|
1. | 1 80 0 5000 0 |
2. | 1 81 0 5500 . |
3. | 1 82 0 6000 0 |
|-----------------------------|
4. | 2 80 1 2000 1 |
5. | 2 81 1 2200 . |
6. | 2 82 1 3300 0 |
|-----------------------------|
7. | 3 80 0 3000 0 |
8. | 3 81 0 2000 . |
9. | 3 82 0 1000 1 |
+-----------------------------+
*/
reshape wide inc ue, i(id) j(year) //the ue81 variable would be created and would contain all missing values
list
/*
+-------------------------------------------------------+
| id inc80 ue80 inc81 ue81 inc82 ue82 sex |
|-------------------------------------------------------|
1. | 1 5000 0 5500 . 6000 0 0 |
2. | 2 2000 1 2200 . 3300 0 1 |
3. | 3 3000 0 2000 . 1000 1 0 |
+-------------------------------------------------------+
*/示例 7:wide 转 long 时变量的命名代码语言:javascript复制use "https://www.stata-press.com/data/r17/reshape3", clear
list
/*
+----------------------------------------------------------+
| id sex inc80r inc81r inc82r ue80 ue81 ue82 |
|----------------------------------------------------------|
1. | 1 0 5000 5500 6000 0 1 0 |
2. | 2 1 2000 2200 3300 1 0 0 |
3. | 3 0 3000 2000 1000 0 0 1 |
+----------------------------------------------------------+
*/
reshape long inc@r ue, i(id) j(year) //@ characters to indicate where the numbers go
list, sepby(id)
/*
+-----------------------------+
| id year sex incr ue |
|-----------------------------|
1. | 1 80 0 5000 0 |
2. | 1 81 0 5500 1 |
3. | 1 82 0 6000 0 |
|-----------------------------|
4. | 2 80 1 2000 1 |
5. | 2 81 1 2200 0 |
6. | 2 82 1 3300 0 |
|-----------------------------|
7. | 3 80 0 3000 0 |
8. | 3 81 0 2000 0 |
9. | 3 82 0 1000 1 |
+-----------------------------+
*/
use "https://www.stata-press.com/data/r17/reshape3", clear
reshape long inc@r ue@, i(id) j(year) //与上面的转换命令等价,充分掌握 @ 字符的作用
list //结果与上面一致
reshape wide inc@r ue, i(id) j(year) //may similarly be used for converting data from long to wide format
list //注意转换后与原始数据集中变量的顺序是不一致的
/*
+----------------------------------------------------------+
| id inc80r ue80 inc81r ue81 inc82r ue82 sex |
|----------------------------------------------------------|
1. | 1 5000 0 5500 1 6000 0 0 |
2. | 2 2000 1 2200 0 3300 0 1 |
3. | 3 3000 0 2000 0 1000 1 0 |
+----------------------------------------------------------+
*/除了用 @ 符号指代数字,wide 转 long 时,还可以在对 j 的设定中为新生成的变量指定数字。 代码语言:javascript复制use "$root\cardio_wide3.dta", clear clist bp* pl*, noobs /* bp1 bp2 bp3 bp4 bp5 bp2005 pl1 pl2 pl3 pl4 pl5 pl2005 115 86 129 105 127 112 54 87 93 81 92 81 123 136 107 111 120 119 92 88 125 87 58 90 124 122 101 109 112 113 105 97 128 57 68 91 105 115 121 129 137 121 52 79 71 106 39 69 116 128 112 125 111 118 70 64 52 68 59 62 108 126 124 131 107 119 74 78 92 99 80 84 */ reshape long bp pl, i(id) j(trial_num) list, sepby(id) /* +---------------------------------+ | id trial_~m age bp pl | |---------------------------------| 1. | 1 1 40 115 54 | 2. | 1 2 40 86 87 | 3. | 1 3 40 129 93 | 4. | 1 4 40 105 81 | 5. | 1 5 40 127 92 | 6. | 1 2005 40 112 81 | |---------------------------------| 7. | 2 1 30 123 92 | 8. | 2 2 30 136 88 | 9. | 2 3 30 107 125 | 10. | 2 4 30 111 87 | 11. | 2 5 30 120 58 | 12. | 2 2005 30 119 90 | |---------------------------------| 13. | 3 1 16 124 105 | 14. | 3 2 16 122 97 | 15. | 3 3 16 101 128 | 16. | 3 4 16 109 57 | 17. | 3 5 16 112 68 | 18. | 3 2005 16 113 91 | |---------------------------------| 19. | 4 1 23 105 52 | 20. | 4 2 23 115 79 | 21. | 4 3 23 121 71 | 22. | 4 4 23 129 106 | 23. | 4 5 23 137 39 | 24. | 4 2005 23 121 69 | |---------------------------------| 25. | 5 1 18 116 70 | 26. | 5 2 18 128 64 | 27. | 5 3 18 112 52 | 28. | 5 4 18 125 68 | 29. | 5 5 18 111 59 | 30. | 5 2005 18 118 62 | |---------------------------------| 31. | 6 1 27 108 74 | 32. | 6 2 27 126 78 | 33. | 6 3 27 124 92 | 34. | 6 4 27 131 99 | 35. | 6 5 27 107 80 | 36. | 6 2005 27 119 84 | +---------------------------------+ */若数据集中 bp2005 和 pl2005 是一个同 age 一样的固定变量,此时除了用 rename 命令改名之外,还可以于转换时在 j 中设定转换后的具体数值。 代码语言:javascript复制use "$root\cardio_wide3.dta", clear reshape long bp pl, i(id) j(trial_num 1-5) list, sepby(id) /* +---------------------------------------------------+ | id trial_~m age bp bp2005 pl pl2005 | |---------------------------------------------------| 1. | 1 1 40 115 112 54 81 | 2. | 1 2 40 86 112 87 81 | 3. | 1 3 40 129 112 93 81 | 4. | 1 4 40 105 112 81 81 | 5. | 1 5 40 127 112 92 81 | |---------------------------------------------------| 6. | 2 1 30 123 119 92 90 | 7. | 2 2 30 136 119 88 90 | 8. | 2 3 30 107 119 125 90 | 9. | 2 4 30 111 119 87 90 | 10. | 2 5 30 120 119 58 90 | |---------------------------------------------------| 11. | 3 1 16 124 113 105 91 | 12. | 3 2 16 122 113 97 91 | 13. | 3 3 16 101 113 128 91 | 14. | 3 4 16 109 113 57 91 | 15. | 3 5 16 112 113 68 91 | |---------------------------------------------------| 16. | 4 1 23 105 121 52 69 | 17. | 4 2 23 115 121 79 69 | 18. | 4 3 23 121 121 71 69 | 19. | 4 4 23 129 121 106 69 | 20. | 4 5 23 137 121 39 69 | |---------------------------------------------------| 21. | 5 1 18 116 118 70 62 | 22. | 5 2 18 128 118 64 62 | 23. | 5 3 18 112 118 52 62 | 24. | 5 4 18 125 118 68 62 | 25. | 5 5 18 111 118 59 62 | |---------------------------------------------------| 26. | 6 1 27 108 119 74 84 | 27. | 6 2 27 126 119 78 84 | 28. | 6 3 27 124 119 92 84 | 29. | 6 4 27 131 119 99 84 | 30. | 6 5 27 107 119 80 84 | +---------------------------------------------------+ */示例 8:j 为非数值时的转换代码语言:javascript复制use "https://www.stata-press.com/data/r17/reshape4", clear list /* +-------------------------+ | id kids incm incf | |-------------------------| 1. | 1 0 5000 5500 | 2. | 2 1 2000 2200 | 3. | 3 2 3000 2000 | +-------------------------+ */ reshape long inc, i(id) j(gender) string //string option specifies that j take on non-numeric values list, sepby(id) //gender 为字符型变量 /* +------------------------+ | id gender kids inc | |------------------------| 1. | 1 f 0 5500 | 2. | 1 m 0 5000 | |------------------------| 3. | 2 f 1 2200 | 4. | 2 m 1 2000 | |------------------------| 5. | 3 f 2 2000 | 6. | 3 m 2 3000 | +------------------------+ */ reshape wide inc, i(id) j(gender) string list /* +-------------------------+ | id incf incm kids | |-------------------------| 1. | 1 5500 5000 0 | 2. | 2 2200 2000 1 | 3. | 3 2000 3000 2 | +-------------------------+ */当j为字符时,转换并不要求如incm和incf这样有特定的字符长度,可以用@ 符号进行指代。 代码语言:javascript复制use "https://www.stata-press.com/data/r17/reshapexp2", clear list /* +------------------------------+ | id kids incmale incfem | |------------------------------| 1. | 1 0 5000 5500 | 2. | 2 1 2000 2200 | 3. | 3 2 3000 2000 | +------------------------------+ */ reshape long inc@, i(id) j(gender) string list, sepby(id) /* +---------------------------+ | id gender kids inc | |---------------------------| 1. | 1 fem 0 5500 | 2. | 1 male 0 5000 | |---------------------------| 3. | 2 fem 1 2200 | 4. | 2 male 1 2000 | |---------------------------| 5. | 3 fem 2 2000 | 6. | 3 male 2 3000 | +---------------------------+ */示例 9: 多层级数据集代码语言:javascript复制use "$root\weights_long2.dta", clear list, sepby(id) // information at two different levels, daily measurements within Persons /* +--------------------------------------------+ | id female age race ed days wt | |--------------------------------------------| 1. | 1 1 22 1 9 7 166 | 2. | 1 1 22 1 9 14 163 | 3. | 1 1 22 1 9 21 164 | 4. | 1 1 22 1 9 28 162 | |--------------------------------------------| 5. | 2 0 43 2 13 9 188 | 6. | 2 0 43 2 13 13 184 | 7. | 2 0 43 2 13 22 185 | 8. | 2 0 43 2 13 27 182 | |--------------------------------------------| 9. | 3 0 63 3 11 6 158 | 10. | 3 0 63 3 11 12 155 | 11. | 3 0 63 3 11 31 157 | |--------------------------------------------| 12. | 4 1 26 2 15 8 192 | 13. | 4 1 26 2 15 17 190 | 14. | 4 1 26 2 15 22 191 | 15. | 4 1 26 2 15 30 193 | |--------------------------------------------| 16. | 5 1 29 1 12 5 145 | 17. | 5 1 29 1 12 11 142 | 18. | 5 1 29 1 12 20 140 | 19. | 5 1 29 1 12 26 137 | +--------------------------------------------+ */ *多层级数据其实是两个 level 数据集的合并 *a level-1 (time) dataset use "$root\weights_level1.dta", clear list, sepby(id) /* +-----------------+ | id days wt | |-----------------| 1. | 1 7 166 | 2. | 1 14 163 | 3. | 1 21 164 | 4. | 1 28 162 | |-----------------| 5. | 2 9 188 | 6. | 2 13 184 | 7. | 2 22 185 | 8. | 2 27 182 | |-----------------| 9. | 3 6 158 | 10. | 3 12 155 | 11. | 3 31 157 | |-----------------| 12. | 4 8 192 | 13. | 4 17 190 | 14. | 4 22 191 | 15. | 4 30 193 | |-----------------| 16. | 5 5 145 | 17. | 5 11 142 | 18. | 5 20 140 | 19. | 5 26 137 | +-----------------+ */ *a level-2 (person) dataset use "$root\weights_level2.dta", clear list, sepby(id) /* +-------------------------------+ | id female age race ed | |-------------------------------| 1. | 1 1 22 1 9 | |-------------------------------| 2. | 2 0 43 2 13 | |-------------------------------| 3. | 3 0 63 3 11 | |-------------------------------| 4. | 4 1 26 2 15 | |-------------------------------| 5. | 5 1 29 1 12 | +-------------------------------+ */ *合并数据集 merge 1:m id using "$root\weights_level1.dta", generate(merge) sort id days list, sepby(id) /* +----------------------------------------------------------+ | id female age race ed days wt merge | |----------------------------------------------------------| 1. | 1 1 22 1 9 7 166 Matched (3) | 2. | 1 1 22 1 9 14 163 Matched (3) | 3. | 1 1 22 1 9 21 164 Matched (3) | 4. | 1 1 22 1 9 28 162 Matched (3) | |----------------------------------------------------------| 5. | 2 0 43 2 13 9 188 Matched (3) | 6. | 2 0 43 2 13 13 184 Matched (3) | 7. | 2 0 43 2 13 22 185 Matched (3) | 8. | 2 0 43 2 13 27 182 Matched (3) | |----------------------------------------------------------| 9. | 3 0 63 3 11 6 158 Matched (3) | 10. | 3 0 63 3 11 12 155 Matched (3) | 11. | 3 0 63 3 11 31 157 Matched (3) | |----------------------------------------------------------| 12. | 4 1 26 2 15 8 192 Matched (3) | 13. | 4 1 26 2 15 17 190 Matched (3) | 14. | 4 1 26 2 15 22 191 Matched (3) | 15. | 4 1 26 2 15 30 193 Matched (3) | |----------------------------------------------------------| 16. | 5 1 29 1 12 5 145 Matched (3) | 17. | 5 1 29 1 12 11 142 Matched (3) | 18. | 5 1 29 1 12 20 140 Matched (3) | 19. | 5 1 29 1 12 26 137 Matched (3) | +----------------------------------------------------------+ */ *可用于多层次回归分析 xtmixed wt days age || id: , noheader nolog /* ------------------------------------------------------------------------------ wt | Coefficient Std. err. z P>|z| [95% conf. interval] -------------+---------------------------------------------------------------- days | -.1294397 .0518173 -2.50 0.012 -.2309997 -.0278797 age | -.1586783 .5521687 -0.29 0.774 -1.240909 .9235525 _cons | 175.5771 21.85316 8.03 0.000 132.7457 218.4085 ------------------------------------------------------------------------------ ------------------------------------------------------------------------------ Random-effects parameters | Estimate Std. err. [95% conf. interval] -----------------------------+------------------------------------------------ id: Identity | sd(_cons) | 18.46033 5.853122 9.91638 34.36573 -----------------------------+------------------------------------------------ sd(Residual) | 1.871344 .3536388 1.292103 2.710255 ------------------------------------------------------------------------------ LR test vs. linear model: chibar2(01) = 58.04 Prob >= chibar2 = 0.0000 */示例 10: long 形数据的进一步处理使用 collapse 命令计算统计量代码语言:javascript复制*计算均值(默认) use "$root\cardio_long.dta", clear list, sepby(id) /* +------------------------------+ | id trial age bp pl | |------------------------------| 1. | 1 1 40 115 54 | 2. | 1 2 40 86 87 | 3. | 1 3 40 129 93 | 4. | 1 4 40 105 81 | 5. | 1 5 40 127 92 | |------------------------------| 6. | 2 1 30 123 92 | 7. | 2 2 30 136 88 | 8. | 2 3 30 107 125 | 9. | 2 4 30 111 87 | 10. | 2 5 30 120 58 | |------------------------------| 11. | 3 1 16 124 105 | 12. | 3 2 16 122 97 | 13. | 3 3 16 101 128 | 14. | 3 4 16 109 57 | 15. | 3 5 16 112 68 | |------------------------------| 16. | 4 1 23 105 52 | 17. | 4 2 23 115 79 | 18. | 4 3 23 121 71 | 19. | 4 4 23 129 106 | 20. | 4 5 23 137 39 | |------------------------------| 21. | 5 1 18 116 70 | 22. | 5 2 18 128 64 | 23. | 5 3 18 112 52 | 24. | 5 4 18 125 68 | 25. | 5 5 18 111 59 | |------------------------------| 26. | 6 1 27 108 74 | 27. | 6 2 27 126 78 | 28. | 6 3 27 124 92 | 29. | 6 4 27 131 99 | 30. | 6 5 27 107 80 | +------------------------------+ */ collapse bp pl, by(id) list, sep(0) /* +---------------+ | id bp pl | |---------------| 1. | 1 112 81 | 2. | 2 119 90 | 3. | 3 114 91 | 4. | 4 121 69 | 5. | 5 118 63 | 6. | 6 119 85 | +---------------+ */ *计算其他统计量 //supports many other statistics beyond mean, sd, min, max use "$root\cardio_long.dta", clear collapse (min) bpmin=bp plmin=pl (max) bpmax=bp plmax=pl, by(id) list, sep(0) /* +------------------------------------+ | id bpmin plmin bpmax plmax | |------------------------------------| 1. | 1 112 81 112 81 | 2. | 2 119 90 119 90 | 3. | 3 114 91 114 91 | 4. | 4 121 69 121 69 | 5. | 5 118 63 118 63 | 6. | 6 119 85 119 85 | +------------------------------------+ */ use "$root\cardio_long.dta", clear collapse (mean) bpmean=bp plmean=pl (sd) bpsd=bp plsd=pl, by(id) list, sep(0) /* +------------------------------------+ | id bpmean plmean bpsd plsd | |------------------------------------| 1. | 1 112 81 18 16 | 2. | 2 119 90 11 24 | 3. | 3 114 91 10 29 | 4. | 4 121 69 12 26 | 5. | 5 118 63 8 7 | 6. | 6 119 85 11 10 | +------------------------------------+ */计算组内滞后项差值代码语言:javascript复制use "$root\cardio_long.dta", clear sort id trial list, sepby(id) /* +------------------------------+ | id trial age bp pl | |------------------------------| 1. | 1 1 40 115 54 | 2. | 1 2 40 86 87 | 3. | 1 3 40 129 93 | 4. | 1 4 40 105 81 | 5. | 1 5 40 127 92 | |------------------------------| 6. | 2 1 30 123 92 | 7. | 2 2 30 136 88 | 8. | 2 3 30 107 125 | 9. | 2 4 30 111 87 | 10. | 2 5 30 120 58 | |------------------------------| 11. | 3 1 16 124 105 | 12. | 3 2 16 122 97 | 13. | 3 3 16 101 128 | 14. | 3 4 16 109 57 | 15. | 3 5 16 112 68 | |------------------------------| 16. | 4 1 23 105 52 | 17. | 4 2 23 115 79 | 18. | 4 3 23 121 71 | 19. | 4 4 23 129 106 | 20. | 4 5 23 137 39 | |------------------------------| 21. | 5 1 18 116 70 | 22. | 5 2 18 128 64 | 23. | 5 3 18 112 52 | 24. | 5 4 18 125 68 | 25. | 5 5 18 111 59 | |------------------------------| 26. | 6 1 27 108 74 | 27. | 6 2 27 126 78 | 28. | 6 3 27 124 92 | 29. | 6 4 27 131 99 | 30. | 6 5 27 107 80 | +------------------------------+ */ by id: generate pldiff1 = pl - pl[_n-1] //minus the previous by id: generate pldiff2 = pl - pl[_n-2] list, sepby(id) /* +--------------------------------------------------+ | id trial age bp pl pldiff1 pldiff2 | |--------------------------------------------------| 1. | 1 1 40 115 54 . . | 2. | 1 2 40 86 87 33 . | 3. | 1 3 40 129 93 6 39 | 4. | 1 4 40 105 81 -12 -6 | 5. | 1 5 40 127 92 11 -1 | |--------------------------------------------------| 6. | 2 1 30 123 92 . . | 7. | 2 2 30 136 88 -4 . | 8. | 2 3 30 107 125 37 33 | 9. | 2 4 30 111 87 -38 -1 | 10. | 2 5 30 120 58 -29 -67 | |--------------------------------------------------| 11. | 3 1 16 124 105 . . | 12. | 3 2 16 122 97 -8 . | 13. | 3 3 16 101 128 31 23 | 14. | 3 4 16 109 57 -71 -40 | 15. | 3 5 16 112 68 11 -60 | |--------------------------------------------------| 16. | 4 1 23 105 52 . . | 17. | 4 2 23 115 79 27 . | 18. | 4 3 23 121 71 -8 19 | 19. | 4 4 23 129 106 35 27 | 20. | 4 5 23 137 39 -67 -32 | |--------------------------------------------------| 21. | 5 1 18 116 70 . . | 22. | 5 2 18 128 64 -6 . | 23. | 5 3 18 112 52 -12 -18 | 24. | 5 4 18 125 68 16 4 | 25. | 5 5 18 111 59 -9 7 | |--------------------------------------------------| 26. | 6 1 27 108 74 . . | 27. | 6 2 27 126 78 4 . | 28. | 6 3 27 124 92 14 18 | 29. | 6 4 27 131 99 7 21 | 30. | 6 5 27 107 80 -19 -12 | +--------------------------------------------------+ */以上 10 例是对 reshape 命令的介绍。正如我们看到的那样,有时发生错误会报错,但有时不会,这便需要我们对数据形态有一个充分的把握。此外,数据处理的过程除了耐心和细心,技术上看,还体现了对众多命令工具的组合能力以及对单一命令的扩展能力。 鉴于水平有限,如有错误还请读者不吝指教! 补充材料: Data_PAS_Stata_reshape.rar版本信息: 2023-10-04(初稿) |
【本文地址】
今日新闻 |
推荐新闻 |