[NeRF]代码+逻辑详细分析 |
您所在的位置:网站首页 › sr理论是什么 › [NeRF]代码+逻辑详细分析 |
[NeRF]代码+逻辑详细分析
|
0. 前言
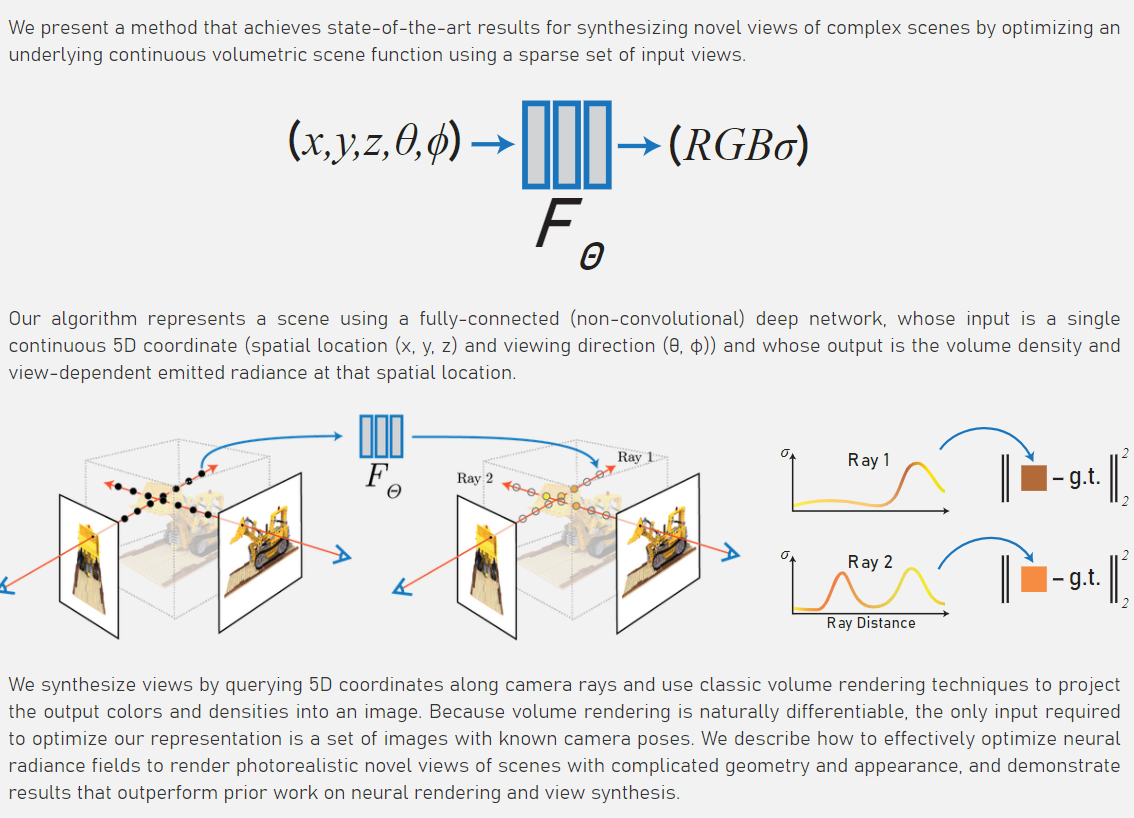
鉴于最近两年(2020,2021),隐式渲染(implicit rendering)技术非常火爆(以NeRF和GRAFFE为代表),而由于这种隐式渲染需要一点点渲染的基础,而且相较于正常的CV任务不是很好理解。为了方便大家学习和理解,我这里将以ECCV2020的NeRF(神经辐射场 NeRF: Neural Radiance Field)[1]为例,对其进行代码级(基于pytorch3d[3]的实现)的详细剖析,希望对需要的朋友有所帮助。 2022.12.23 更新 本篇博客只介绍了最基础的NeRF, 这几年有非常多的新工作陆续出来, 如果小伙伴有需要更系统、完善的的入门学习课程,推荐深蓝学院的专门课程: 神经辐射场(NeRF)系列分享 1. 什么是NeRF根据官方的项目[1], NeRF实质上就是构造一个隐式的渲染流程,其输入是某个视角下发射的光线的位置 o o o,方向 d d d以及对应的坐标 x , y , z x,y,z x,y,z。通过神经辐射场 F θ F_{\theta} Fθ, 得到体密度和颜色,最后再通过volumteric rendering渲染得到最终的图像。 关于通过位置,方向
d
\mathbf{d}
d和坐标
x
\mathbf{x}
x映射到体密度
σ
\sigma
σ和颜色
c
\mathbf{c}
c的方程,更formal的表达形式如下(来自nerf论文):
下图来自图宾根大学的Geiger教授[2](他也是CVPR2021最佳论文的指导老师!), 以grid_sampler为例(这个grid_sampler后面会讲), 我们从图像的每个位置出发,发射一条光线ray:
o
+
t
d
o + td
o+td. 接下来,经过神经辐射场
F
θ
F_{\theta}
Fθ的处理,我们得到了每一个小球的颜色
c
\mathbf{c}
c和密度
σ
\sigma
σ(颜色已经不一样了~),那么根据体渲染(volumetric rendering)的机制,就可以进行渲染了。 渲染的可视化效果如下, 我个人感觉已经很直观了~,关于体渲染的具体理论我在这里不展开,本篇博客的主要目的是介绍NeRF所涉及代码的每个方面。 总的来说,NeRF的流程分为3步,下面的代码也会按照这个流程进行展开: (a) 使用raysampler生成光线rays (包含输入的光线方向, 起点, 位置). (b) 对生成的sampled rays, 调用volumetric函数(即NeuralRadianceField-nerf/nerf/implicit_function.py), 得到rays_densities σ \sigma σ和rays_features c \mathbf{c} c. © 最后, 沿着光线积分颜色, 得到最终图像(如上gif图) 2. NeRF代码框架研究目标: 研究训练和推理中, 每个环节的输入&输出.借此机会仔细分析下PyTorch3D的ImplicitRenderer以及Volumetric Function(可self define)的设计.研究内容: 我们主要关注数据的处理流程和NeRF的关键步骤, 一些可视化和工具化的脚本和函数在本blog里将不会展开介绍。
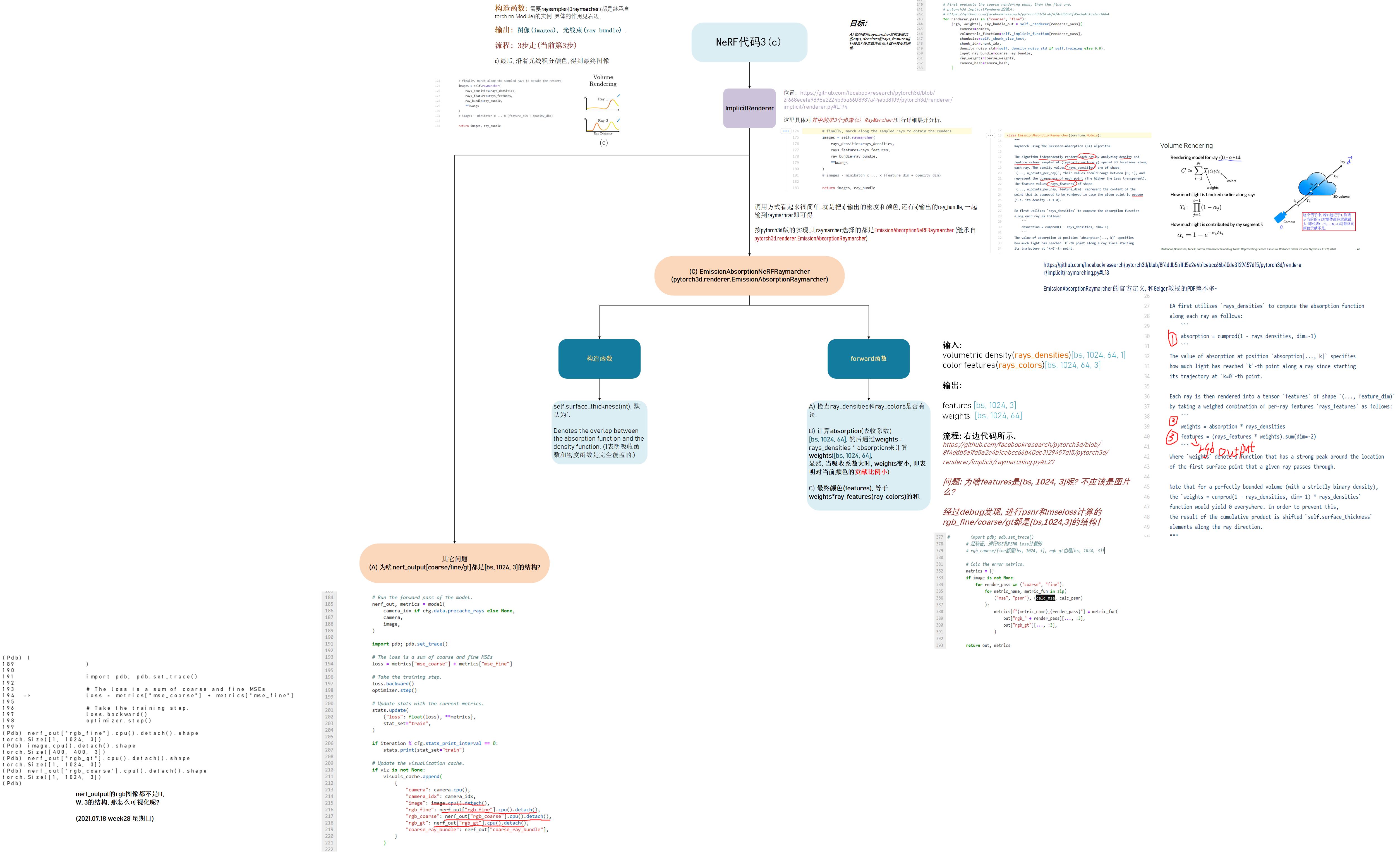
位置: nerf/nerf/datasets.py/get_nerf_datasets函数 说明: 返回图像, 相机参数, 相机编号3个东西组成的数据结构: [{“image”:xxx, “camera”:xxx, “camera_idx”: int}] image: 8bit原始图像归一化到[0,1]的(torch.FloatTensor) [H, W, 3] (本例取H=W=400) camera是pytorch3d.renderer.cameras.PerspectiveCameras的实例, 详细参数见下面的介绍. camera_idx则是标识相机序号的int型(0, 1, 2, ..., 99).以Lego(乐高)的小车数据为例, 位置: nerf/nerf/nerf_renderer.py/pytorch模块(继承torch.nn.Module)RadianceFieldRenderer 说明: 包含pytorch3d.renderer.ImplicitRenderer的instance & 表征NeRF的网络的instance. 渲染过程: coarse2fine(分为3大步, 7小步) 由于结构远比数据处理的部分复杂, 因此新开一个section进行分析. 3. Structure这里是结构的整体示意图,为了方便理解,我把相关的代码,图示都放在一起了。请大家放大查看。
Q1: 为什么生成出来的rgb_coarse, rgb_fine, rgb_gt都是[bs, 1024(n_rays_per_image), 3],而不是[bs, H, W, 3]呢? A1: 因为体渲染的计算量非常大, 所以一次只计算一部分光线渲染的结果(即对应于图像中的局部patch), 然后再把这个patch结合起来,最终得到渲染的图像. 以H=W=400为例,训练时一直用的是[bs, 1024, 3]进行loss的计算和网络的迭代。 测试时,首先先按照GPU容许的chunk_size进行计算, 得到需要计算的光线束的总量: step1: nerf/nerf/nerf_renderer.py的第340行左右 if not self.training: # Full evaluation pass. # self._renderer['coarse'].raysampler.get_n_chunks是根据xy_grid来计算需要多少个 # chunk (比如400*400, chunk_size_test=6000, 那n_chunks就等于 # (Pdb) math.ceil(160000 / 6000) # 27 n_chunks = self._renderer["coarse"].raysampler.get_n_chunks( self._chunk_size_test, camera.R.shape[0], ) # print("[n chunks] shape", n_chunks) # 测试阶段, n_chunks等于27 else: # MonteCarlo ray sampling. n_chunks = 1step2: 根据每次渲染的光线数量(6000)以及总光束的数量(27), 进行渲染,最终将其进行拼接: 26 x 6000+ 1 x 4000 = 160000, 再reshape为400*400的图像即可~ # Process the chunks of rays. # chunk_outputs[0]是训练的输出, 因为n_chunks=1. # 测试阶段, 以lego为例, n_chunks=27, chunk_outputs是个list, # 其中的每个item都是dict, keys为[rgb_coarse, rgb_fine, rgb_gt]. # rgb_coarse/rgb_fine/rgb_gt都是[bs(1), 6000, 3]. chunk_outputs = [ self._process_ray_chunk( camera_hash, camera, image, chunk_idx, ) for chunk_idx in range(n_chunks) ] import pdb; pdb.set_trace() # (Pdb) len(chunk_outputs) # 27 # (Pdb) for item in chunk_outputs: print(item['rgb_fine'].shape) # 可以看到, 26*6000+1*4000 = 160000 = 400*400, 这就是H*W! # torch.Size([1, 6000, 3]) # torch.Size([1, 6000, 3]) # torch.Size([1, 6000, 3]) # ... # torch.Size([1, 6000, 3]) # torch.Size([1, 4000, 3]) if not self.training: # For a full render pass concatenate the output chunks, # and reshape to image size. # 拼接即可. out = { k: torch.cat( [ch_o[k] for ch_o in chunk_outputs], dim=1, ).view(-1, *self._image_size, 3) if chunk_outputs[0][k] is not None else None for k in ("rgb_fine", "rgb_coarse", "rgb_gt") } else: out = chunk_outputs[0][1] NeRF [2]:GRAF介绍 [3]: pytorch3d/nerf [4]: pytorch3d/PerspectiveCamera |
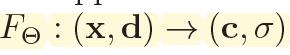
 这里面涉及到了不少关于渲染相关的概念,比如说: 光线是什么鬼?怎么发射的?方向是什么?对于任意视角给定的图片,我们应该怎么去按照这个流程进行渲染呢?
这里面涉及到了不少关于渲染相关的概念,比如说: 光线是什么鬼?怎么发射的?方向是什么?对于任意视角给定的图片,我们应该怎么去按照这个流程进行渲染呢?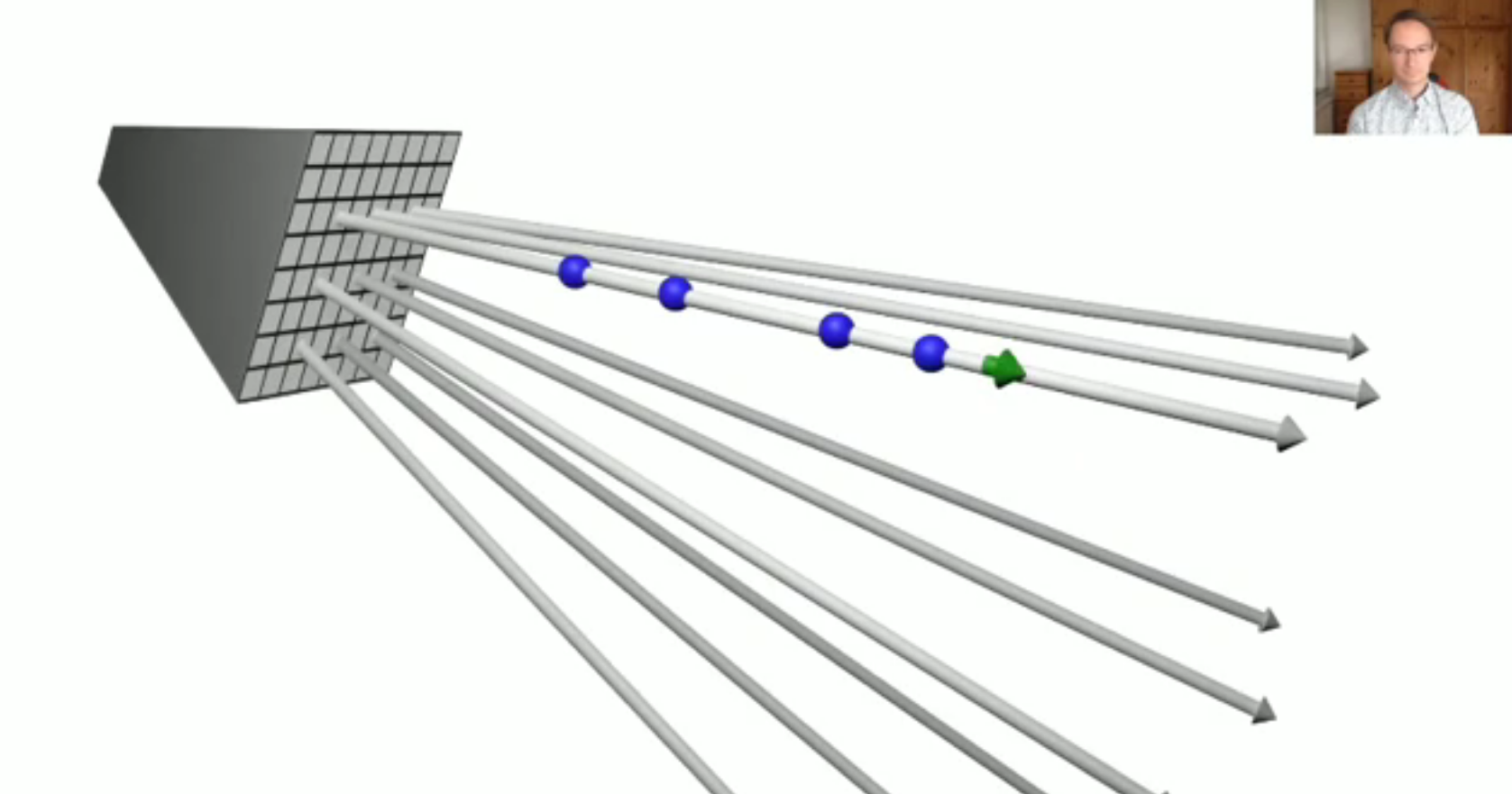 由上图可以看到,蓝色的小球(或如图[1]的黑色小球)就是我们在光线方向上,根据不同的
t
t
t(可以理解为深度)采样得到的点,最后输入网络的内容,其实就是经过位置编码
γ
\gamma
γ(positional encoding)的这些蓝色点的坐标
x
,
y
,
z
x,y,z
x,y,z以及方向
d
d
d。
由上图可以看到,蓝色的小球(或如图[1]的黑色小球)就是我们在光线方向上,根据不同的
t
t
t(可以理解为深度)采样得到的点,最后输入网络的内容,其实就是经过位置编码
γ
\gamma
γ(positional encoding)的这些蓝色点的坐标
x
,
y
,
z
x,y,z
x,y,z以及方向
d
d
d。


 训练数据为100个相机视角下(Idx分别标识不同的相机视角)的图片.下面选择3个例子展示一下: 这里的相机模型用的是透视相机[4](PerspectiveCamera)
训练数据为100个相机视角下(Idx分别标识不同的相机视角)的图片.下面选择3个例子展示一下: 这里的相机模型用的是透视相机[4](PerspectiveCamera)  可以对照文档,分析透视投影相机的参数,这里我们主要用到的是选择矩阵
R
R
R, 平移矩阵
T
T
T, 焦距
f
o
c
a
l
_
l
e
n
g
t
h
focal\_ length
focal_length以及主视点
p
r
i
n
c
i
p
l
e
_
p
o
i
n
t
principle\_point
principle_point(具体的数值见上图).
可以对照文档,分析透视投影相机的参数,这里我们主要用到的是选择矩阵
R
R
R, 平移矩阵
T
T
T, 焦距
f
o
c
a
l
_
l
e
n
g
t
h
focal\_ length
focal_length以及主视点
p
r
i
n
c
i
p
l
e
_
p
o
i
n
t
principle\_point
principle_point(具体的数值见上图). 
 其中 Coarse: 1,2,3 Fine: 4,5,6 Optimization: 7
其中 Coarse: 1,2,3 Fine: 4,5,6 Optimization: 7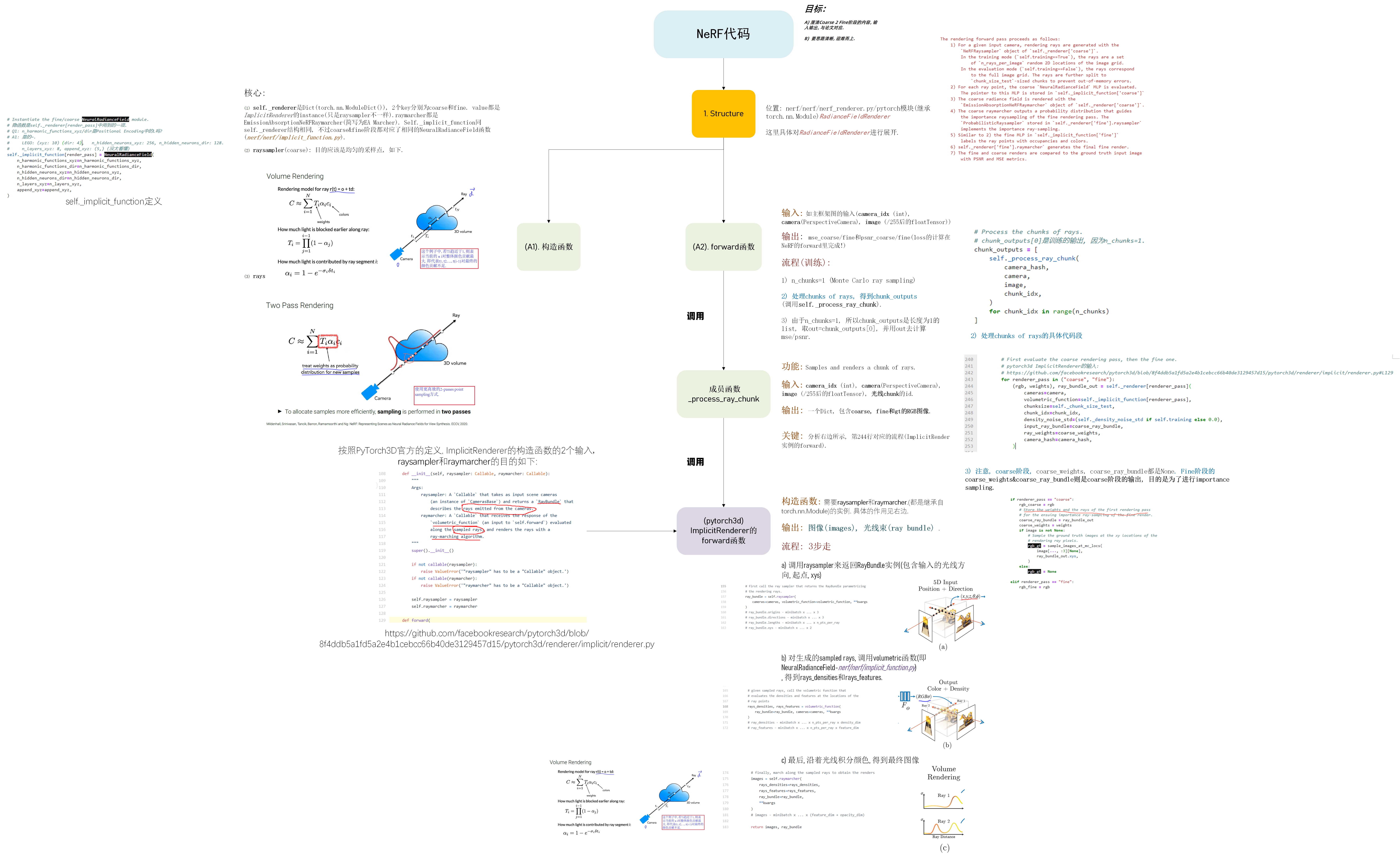


【本文地址】
今日新闻 |
推荐新闻 |