SQL报错型注入原理 |
您所在的位置:网站首页 › sqlmap注入原理 › SQL报错型注入原理 |
SQL报错型注入原理
|
SQL报错型注入原理
一、xpath语法格式错误的报错: mysql5.1.5版本中添加了extractvalue()、updatexml()函数,它们两个分别能够对XML文档进行查询、修改操作,下面分别对这两个函数进行介绍。 这里是MYSQL对extractvalue()和updatexml()的官方介绍 1、extractvalue(xml_frag, xpath_expr):从一个使用xpath语法的xml字符串中提取一个值。 xml_frag:xml文档对象的名称,是一个string类型。 xpath_expr:使用xpath语法格式的路径。 SQL报错注入的应用:当使用extractvalue(xml_frag, xpath_expr)函数时,若xpath_expr参数不符合xpath格式,就会报错。 而~符号(ascii编码值:0x7e)是不存在xpath格式中的, 所以一旦在xpath_expr参数中使用~符号,就会产生xpath syntax error (xpath语法错误),通过使用这个方法就可以达到报错注入的目的。 2、updatexml(xml_target, xpath_expr, new_xml): xml_target:xml文档对象的名称,是一个string类型。 xpath_expr:使用xpath语法格式的路径。 new_xml:需要更新的内容。 SQL报错注入的应用:当使用updatexml(xml_target, xpath_expr, new_xml)函数时,若xpath_expr参数不符合xpath格式,就会报错。 而~符号(ascii编码值:0x7e)是不存在xpath格式中的, 所以一旦在xpath_expr参数中使用~符号,就会产生xpath syntax error (xpath语法错误),通过使用这个方法就可以达到报错注入的目的。 二、floor()、rand()、group by语句相结合的报错: 1、rand()函数: rand()返回0到1的随机数。 rand(0)返回一个固定的0到1的伪随机数。 2、floor()函数: floor(x)返回小于或等于 x 的最大整数。 3、group by语句: group by语句可以根据一个或多个列对结果集进行分组,在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。 SQL报错注入的应用:当count(*)、floor(rand(0))和group by x同时执行时,就会爆出duplicate entry错误。 原理:floor(rand(0)*2)的不确定性,可能为0也可能为1。 3.1、group by语句执行过程: SQL语句:select floor(rand(0)*2),count(*) from table gruop by floor(rand(0)*2) ; 创建内存临时表,表里有两个字段 floor(rand(0)*2) 和 count(*) ,主键是 floor(rand(0)*2) ; 扫描表的索引,依次取出叶子节点上的 floor(rand(0)*2) 值(执行floor(rand(0)*2),记为 number ; 2.1. 如果临时表中没有主键为 number 的行,就插入一个记录 (number,1) ,插入的过程中需要再取一次group by后面的值 (即再再执行一次 floor(rand(0)*2)) ; 2.2. 如果表中有主键为 number 的行,就将 number 这一行的 count(*) 值+1 ,此时仅是更新count(*)的值,不会再次执行floor(rand(0)*2) ; 遍历完成后,得到结果集返回给客户端。 SQL执行语句:select rand(0); 可以看到,rand(0) 会固定输出一个伪随机数,所以当执行SQL语句: select floor(rand(0)*2) from t_comment ,就会固定有 011011001 的顺序值 ,根据上面group by语句的执行过程,就可以知道,当执行SQL语句: select count(*), floor(rand(0)*2) from t_comment group by floor(rand(0)*2) 时有以下过程: 一、当第一次将数据存储到临时表时,扫描到的是 0 ,临时表中不存在 0 ,所有需要将 0 插入到临时表中,但是在插入时会再执行一次 floor(rand(0)*2 结果值为 1,就会将 1插入到临时表中,然后 count 的值就 +1 变成了1,这时临时表中就存在 1 (因为第一次扫描时,执行第 1 次 floor(rand(0)*2) 得到的是 0, 但是在插入时再次执行第 2 次 floor(rand(0)*2) 得到的是 1 ,所以插入的就是 1 )。 二、那么进行第二次扫描,执行的第 3 次 floor(rand(0)*2) 值就是 1 了,这时因为临时表中存在有 1 ,所以 1 的 count 值就再 +1 变成了 2。 三、那么到第三次扫描的时候,执行的就是第 4 次 floor(rand(0)*2) ,这时得到的值就是 0 了( 这是因为临时表中不存在有 0 ,所以需要进行插入操作,那么就需要执行第 4 次 floor(rand(0)*2) ,这时得到的值就是 1 ),这时就会出现问题,到底是插入 1 把 count 值变为 1 呢,还是将 1 的之前 count 值 +1 变为 3呢,到这里系统就会抛出异常报错了。 验证: 这里我们再测试一下,上面的说法合不合理,当表 t_article 只有两条数据的时候,可以看到执行SQL语句: select count(*), floor(rand(0)*2) from t_article group by floor(rand(0)*2) 时,只会进行到第二次扫描,也就是运行过程只到上面的第二步,那么也就是一共执行了 3 次 floor(rand(0)*2) ,所以 1 的 count 值就为 2 ,并且不会报错。 SQL执行语句:select count(*), floor(rand(0)*2) from t_article group by floor(rand(0)*2) SQL执行语句:select count(*), floor(rand(0)*2) from t_test group by floor(rand(0)*2) ?id=1’ and ( select 1 from ( select count(*),concat( ( select schema_name from information_schema.schemata limit 0,1 ), floor( rand( 0 )*2 ) ) x from information_schema.schemata group by x ) b ) --+
“select * from users where id=‘1’ and ( select 1 from ( select count(*),concat( ( select schema_name from information_schema.schemata limit 0,1 ), floor( rand( 0 )*2 ) ) x from information_schema.schemata group by x ) b ) --+ ’ LIMIT 0,1” 这时,一步一步分解 sql 语句可以看到 concat( ( select schema_name from information_schema.schemata limit 0,1 ), floor( rand( 0 )*2 ) ) 的目的是将要查询信息的语句 select schema_name from information_schema.schemata limit 0,1 和 floor( rand( 0 )*2 ) 用 concat() 连接起来,这样就可以通过报错,将要查询的信息爆出来了。 concat( ( select schema_name from information_schema.schemata limit 0,1 ), floor( rand( 0 )*2 ) ) x 当中的 x 是相当于给这一串字符添加了一个别名,就是 x 就等于 concat( ( select schema_name from information_schema.schemata limit 0,1 ), floor( rand( 0 )*2 ) ), 这样做的目的是,省得后面再次使用这一长条字符的时候麻烦,可以直接使用它的别名来代替。 所以,这条语句 select count(*),concat( ( select schema_name from information_schema.schemata limit 0,1 ), floor( rand( 0 )*2 ) ) x from information_schema.schemata group by x 就可以分解简单的看成 select count(*), x from information_schema.schemata group by x 这里的 x 就是上面讲到的一长串字符的别名,x 里面连接包含了要查询的语句和floor(rand(0)*2),这不就是 floor() 报错的关键核心SQL语句嘛。 但是如果就这样放到URL里面去执行肯定不行,因为没有能和 select * from users where id=‘1’ 拼接到一起,不能一起执行,所以我们需要用到 and 运算符。 and 运算符简介: and 运算符通常用在select,update,detele 语句的 where 子句中以形成布尔表达式。 and 运算符是组合两个或多个布尔表达式的逻辑运算符。 sql语句要求在查询结果的基础上再执行查询时,必须给定一个别名。这时,我们先将我们的语句变成这样: ( select count(*),concat( ( select schema_name from information_schema.schemata limit 0,1 ), floor( rand( 0 )*2 ) ) x from information_schema.schemata group by x ) b 就是给了这一长串字符一个别名:b 最后我们用到的 and 运算符,将 id = ‘1’ 与 这边结果连着一起,但是又必须是布尔型,就是说返还的结果不是 1,就是 0。所以我们就在 b 的基础上再执行查询,也就响应了为什么上面要给一个别名 b 了,因为sql语句要求在查询结果的基础上再执行查询时, 必须给定一个别名,这时用 select 1 from b 语句,返还布尔值,与 select * from users where id=‘1’ 连接在一起,这样就可以执行成功了。 可以更改 limt 子句后面的参数来决定显示出来的信息,因为报错信息的长度有限,不能直接全部输出出来。
三、整形溢出报错注入: 条件:5.5 |
 SQL执行语句:select floor(rand(0)*2) from t_comment;
SQL执行语句:select floor(rand(0)*2) from t_comment; 
 SQL执行语句:select count(*), floor(rand(0)*2) from t_comment group by floor(rand(0)*2)
SQL执行语句:select count(*), floor(rand(0)*2) from t_comment group by floor(rand(0)*2) 
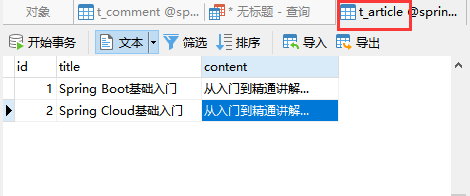
 验证: 当表 t_est 有 3 条数据的时候,可以看到执行SQL语句: select count(*), floor(rand(0)*2) from t_test group by floor(rand(0)*2) 时,会进行第 3 次扫描,也就是运行过程刚好到上面的第三步,那么也就是一共执行了 4 次 floor(rand(0)*2) ,执行第 4 次 floor(rand(0)*2) 时,就会因为 0 与 1 的冲突,从而抛出异常报错。
验证: 当表 t_est 有 3 条数据的时候,可以看到执行SQL语句: select count(*), floor(rand(0)*2) from t_test group by floor(rand(0)*2) 时,会进行第 3 次扫描,也就是运行过程刚好到上面的第三步,那么也就是一共执行了 4 次 floor(rand(0)*2) ,执行第 4 次 floor(rand(0)*2) 时,就会因为 0 与 1 的冲突,从而抛出异常报错。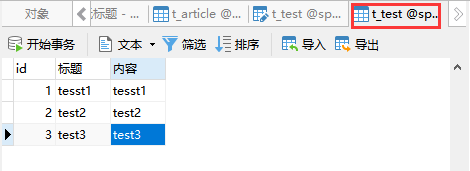
 4、sqli-labs 靶场 Less-5 使用 floor() 报错举例及解释: 首先看使用 floor()、count()、group by 的SQL 注入语句:
4、sqli-labs 靶场 Less-5 使用 floor() 报错举例及解释: 首先看使用 floor()、count()、group by 的SQL 注入语句: 上图是,Less-5的源码,可以看到,我们输入的URL放入到sql语句中,就成了:
上图是,Less-5的源码,可以看到,我们输入的URL放入到sql语句中,就成了:
【本文地址】