回归分析时何时设置哑变量?如何设置?手把手教会SPSS分析 |
您所在的位置:网站首页 › spss虚拟变量是什么 › 回归分析时何时设置哑变量?如何设置?手把手教会SPSS分析 |
回归分析时何时设置哑变量?如何设置?手把手教会SPSS分析
|
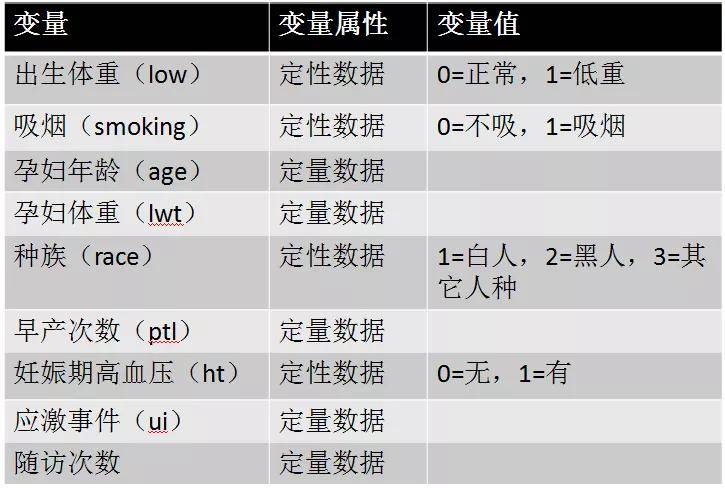
例1: Hosmer和Lemeshow于1989年研究了低出生体重婴儿的影响因素,结果变量为是否娩出低出生体重儿,考虑的自变量有产妇妊娠前体重、产妇年龄、种族、是否吸烟、早产次数、是否患高血压等。(数据文件见:logistic_step.sav。)
该数据库中有一个变量为种族,变量值为白人/黑人/其他人,为无序多分类资料(赋值分别是1、2、3)。如果该变量纳入回归模型,怎么解读回归系数b值呢?那么就是自变量从1到2对y的影响和从2到3影响的平均值。也就是白人到黑人,黑人到其他人种变化带来的影响的平均值。这个结果无法说明任何问题,既不能说明黑人相对白人出生缺陷的严重性,也不能说其他人种的影响。这个变量是无序分类变量,各变量之间没有等级关系。因此,取平均值没有任何实际意义。 因此,无序多分类变量不能直接纳入回归开展分析。 回归分析的哑变量设置 对于种族的影响,其实研究最想知道的是,(1)相对白人,黑人出生缺陷风险会提升多少? (2)相对白人,其它人种出生缺陷风险会提升多少? 因此,一个变量需要回答两个问题,最好的办法是把这个变量分为两个子变量,分别计算b值和OR值,这个子变量便是哑变量。
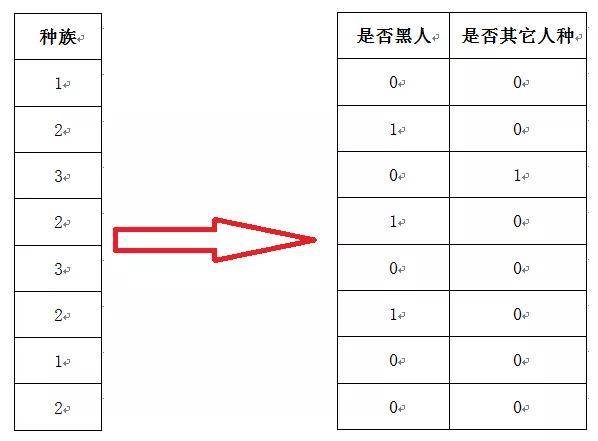
一般情况下,哑变量个数是原变量分类数的n-1个,比如种族变量是3分类变量,则一个种族变量产生了2个二分类(变量值为0、1)哑变量。这些哑变量是过程性变量,一般不体现在原始数据库中,但它们作为实体变量代替原变量进入到回归模型中。
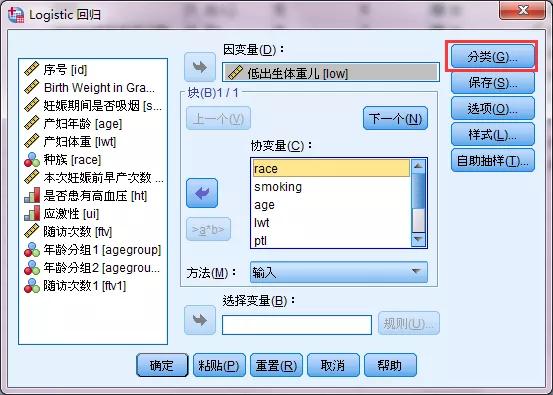
其中,b1反映的是相对于白人,黑人对y的影响,b2反映的是相对于白人,其他人种对y的影响。从而解决了无序分类变量回归系数b值无法进行取平均值的尴尬局面。 logistic回归哑变量设置logistic回归哑变量设置的十分简单,SPSS软件通过简单、菜单式的操作既可以完成。 1.logistic回归分析SPSS操作过程logistic回归SPSS分析的界面,选择“分类”
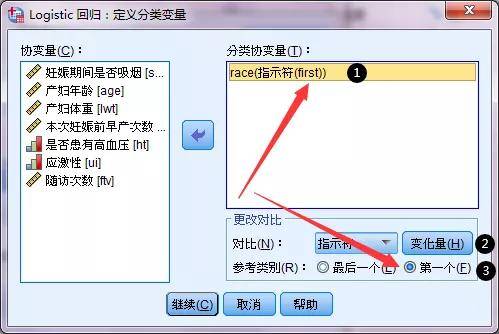
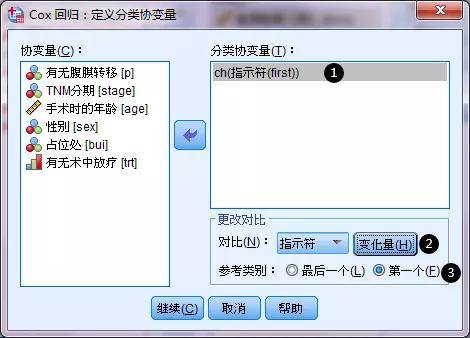
在"分类"界面, ①选择race(种族)到右选框, ②选择参照类别(第一个、还是最后一个),这里的第一还是最后,根据数据库赋值来定义。本数据库race赋值为1、2、3,若参考类别是第一个,则1为对照(白人),若参考类别是最后一个,则3为对照(其它人)。本例设定白人为对照。 ③最后需要点击“变化量”,确认是以第一个作为对照,此时选项框中race会显 示first。
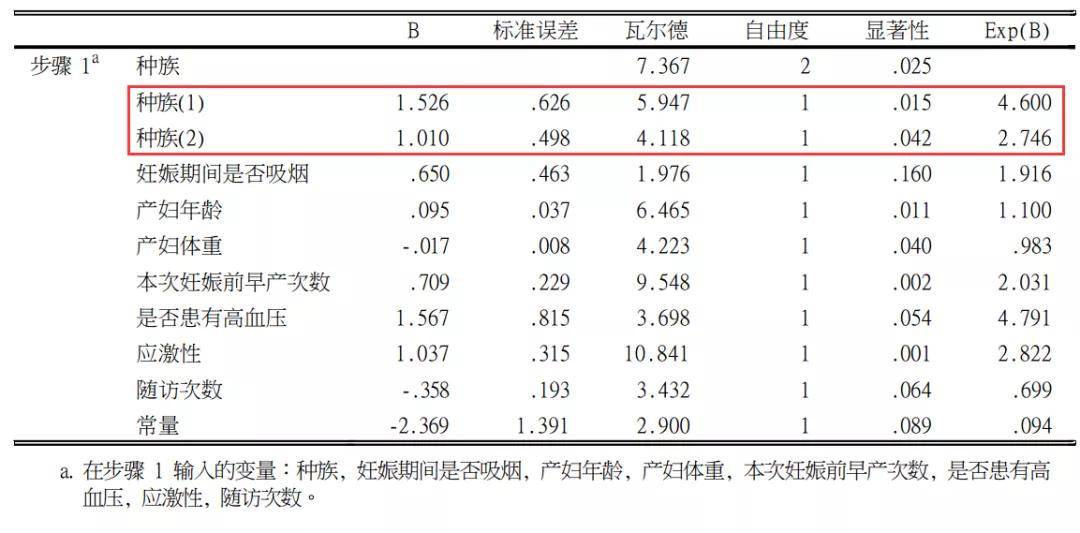
哑变量设置之后,统计分析首先非常重要的是看“分类变量编码”的表格,以确定哑变量的分配设置。 在该表中,列出了两个哑变量(1)、(2),(1)和(2)均已白人作为对照,(1)这一列数字1.000所在行是黑人,因此表明(1)是是否黑人的变量,实际将开展黑人vs白人的比较。,(2)这一列数字1.000所在行是其它种族,因此表明(1)是是否其他人的变量,实际将开展其它人vs白人的比较。 然后我们就可以观察SPSS logistic分析结果。
上图SPSS分析结果,更详细的内容可以学习logistic回归的推文: Logistic 回归简明教程:原理、SPSS操作、结果解读与报告撰写 这里只介绍哑变量的分析结果。种族(1)和种族(2)在上表已经说明,分别代表黑人vs白人的比较、其他人vs白人的比较。结果显示,相对白人,黑人与低出生体重存在着关联(OR=4.60,P=0.015);相对白人,其它种族与低出生体重存在着关联(OR=2.75,P=0.042)。 Cox回归哑变量的SPSS操作Cox回归哑变量设置的十分简单,且方式与logistic回归完全一致,SPSS软件通过简单、菜单式的操作既可以完成。这里引用之前的案例开展分析。 1.分析案例案例2:这是一项关于胰腺癌病人术后生存时间的队列研究。该研究的终点为死亡,包括很多可能影响生存的因素。数据库见pancer.sav
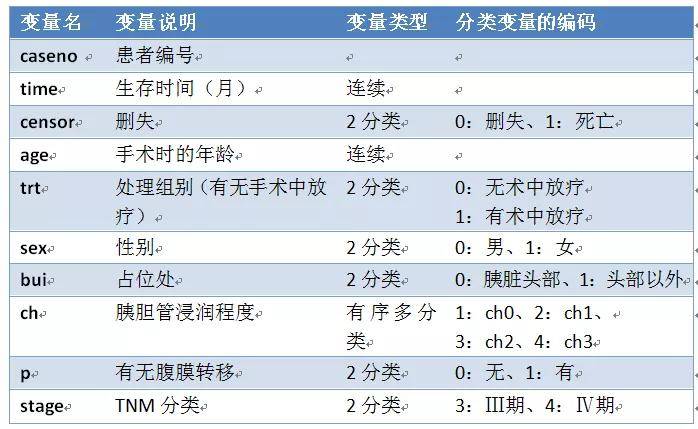
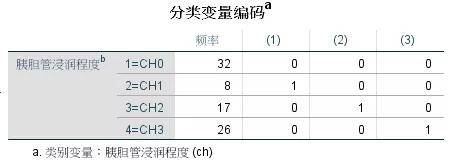
这个数据库中ch(胰胆管浸润程度)是分类变量,同样可以进行哑变量设置。该变量有4个水平,可以设置哑变量,并以ch0作为对照。 2.SPSS操作界面Cox回归SPSS分析的界面,选择“分类”
分类界面与logistic回归分析的操作手法完全一致,也分为①、②、③
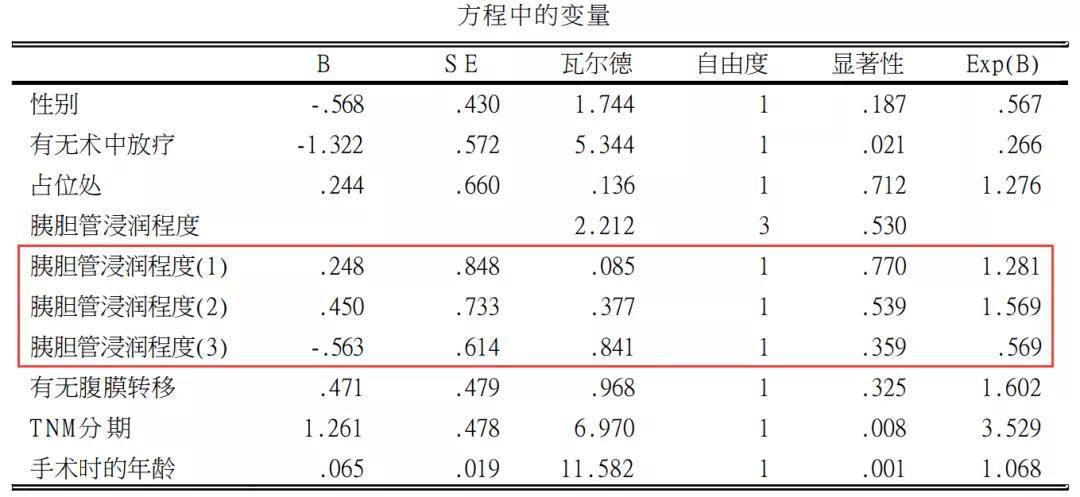
同样,Cox回归也给出“分类变量编码”的表格,以确定哑变量的分配设置。 在该表中,列出了3个哑变量(1)、(2),(3),三个变量中,对照组都是CH0的等级。(1)为是否CH1的变量,实际将开展CH1vsCH0的比较;(2)为是否CH2的变量,实际将开展CH2vsCH0的比较;(3)为是否CH3的变量,实际将开展CH3vsCH0的比较。
上图SPSS分析结果,更详细的内容可以学习Cox回归的推文 初学者如何理解Cox回归和HR值 这里只介绍哑变量的分析结果。结果显示,相对ch0,CH1、CH2、CH3不会增加胰腺癌的死亡风险(P值分别是0.770、0.539、0.359)。
线性回归SPSS操作有两种方法,常规的线性回归的哑变量设置十分复杂,此外还可以采用广义线性模型的模块进行哑变量的设置分析。 1.分析案例例3:研究究高血压患者血压与性别、年龄、身高、体重、户籍等变量的关系,随机测量了32名40岁以上的血压y、年龄X1、体重指数X2、性别X3,户籍X4试建立多重线性回归方程。数据文件见reg.sav。
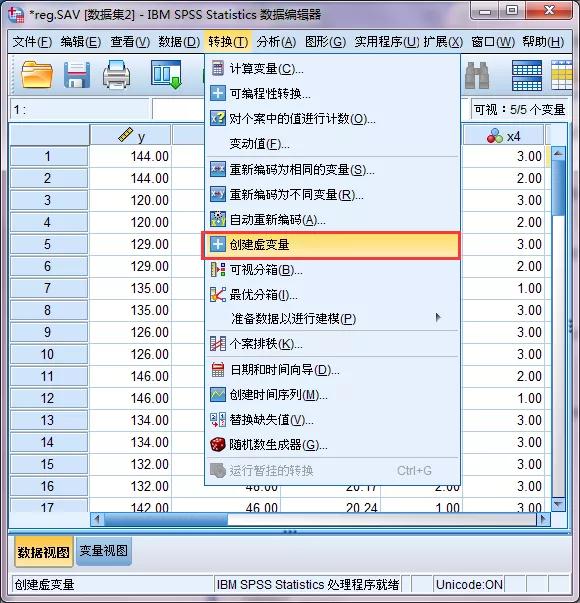
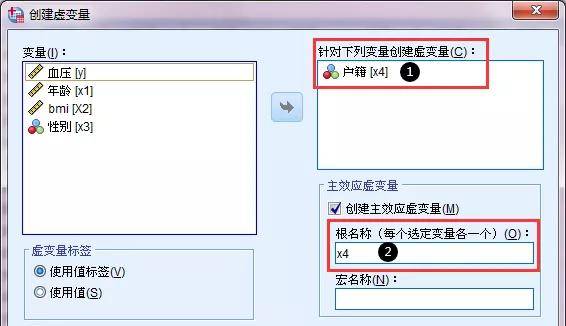
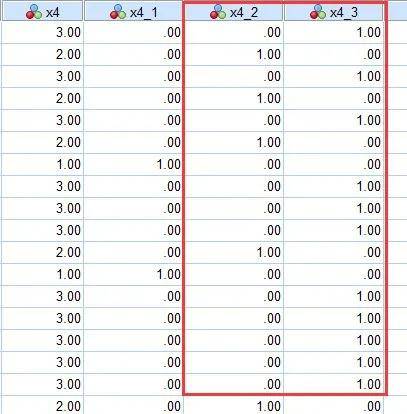
本例中户籍是无序多分类变量,其变量值1=农村,2=城镇,3=城市,在这种情况下,线性回归方程也无法直接将它纳入模型进行分析。需要对此进行哑变量的设置。 2.常规的线性回归分析方法常规线性回归是相对于广义线性模型而言,采用最小二乘法原则对回归系数进行估计的一种方法。 对于这个内容,先前课程已经进行详细介绍: 多因素线性回归分析,为什么和单因素回归结果不一样? 这里介绍下如何解决哑变量的问题。 对线性回归,没有现成的简易的软件自动设置的方法,需要首先进行计算产生哑变量,再进行回归分析。 (1)哑变量设置 SPSS软件哑变量设置有人工法和软件法,常见的是软件法:首先,点击转换--创建虚变量,接着①选择X4进行哑变量设置,②设置哑变量的名称X4( 系统将产生X4_1,X4_2,X4_3三个变量)
然后得到3个哑变量的结果,本文将去X4_2、X4_3进行分析。其中X4_2代表城镇,对照组是农村;X4_3代表城市,对照组是农村。
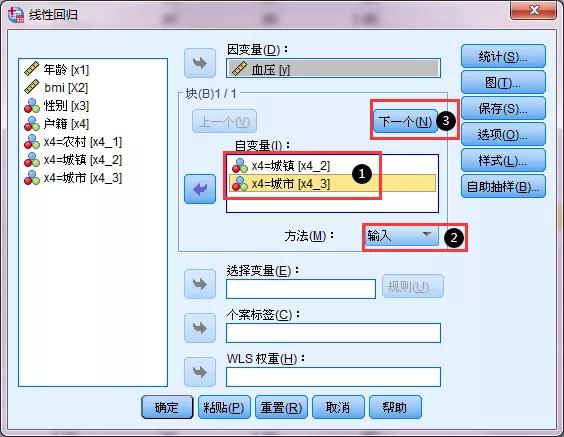
(2)线性回归分析 接着开展线性回归分析,哑变量设置之后,线性回归分析自变量筛选的方式不再和常规的方式一致,它需要分两部分进行。第一,①将X4_2、X4_3纳入自变量范畴(X4,和X4_1请忽略),②方法中必须保持"输入(Enter)",③点击“下一个”
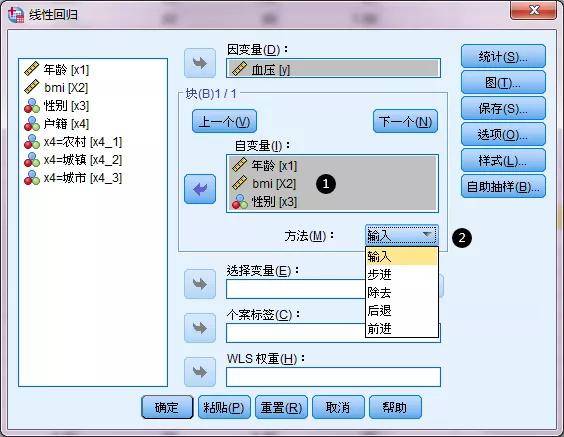
点击“下一个之后”,①在自变量继续填入其它自变量,②方法中保持"输入(Enter)或者下来其它自变量删选的方法。
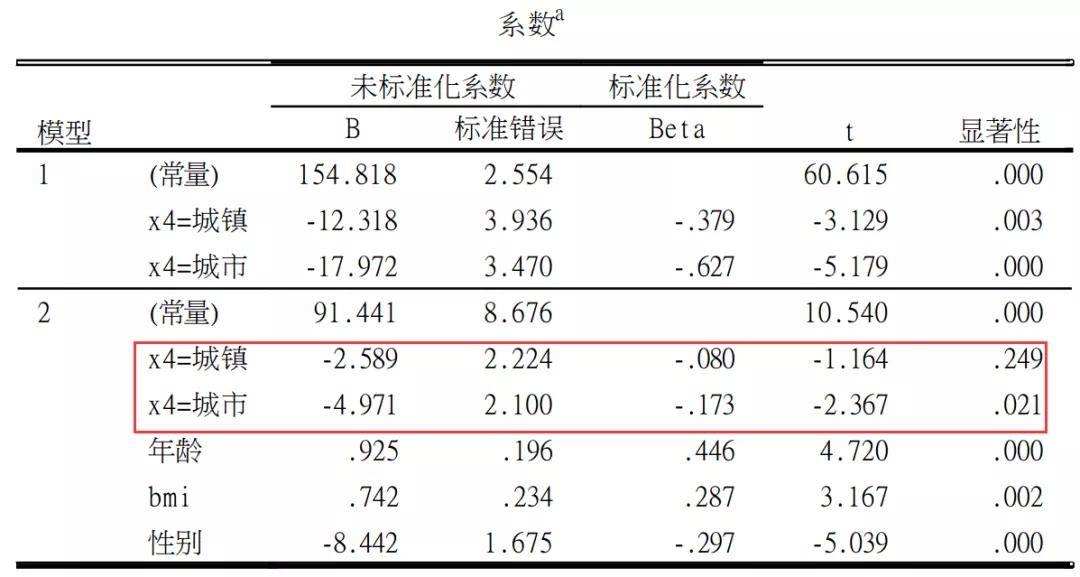
最后,在回归分析第2步基础上,得到两个哑变量的结果,分别是城镇VS农村和城市VS农村的回归系数b值。结果显示,与对农村相比,城镇居民血压值无统计学意义(P=0.249),城市血压值具有统计学差异(P=0.021)。
广义线性模型自动设置哑变量并进行分析,对于进行多次哑变量设置的场景具有优势。 (1)SPSS软件设置 首先,进入广义线性模型的界面
然后,模型类型选择“线性”
“响应”选择“血压”作为应变量Y
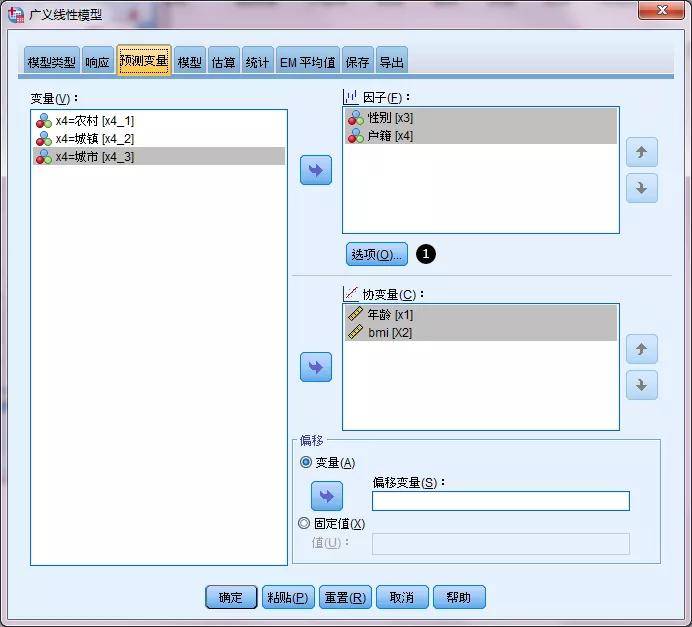
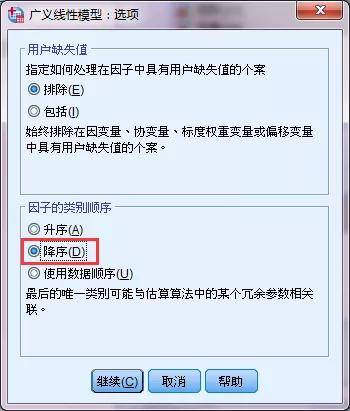
“预测变量”中,选择年龄X1、BMI X2是定量数据,进入协变量;性别X3和户籍X4分类变量进入因子;因子下方“选项”①,一般选择“降序”。
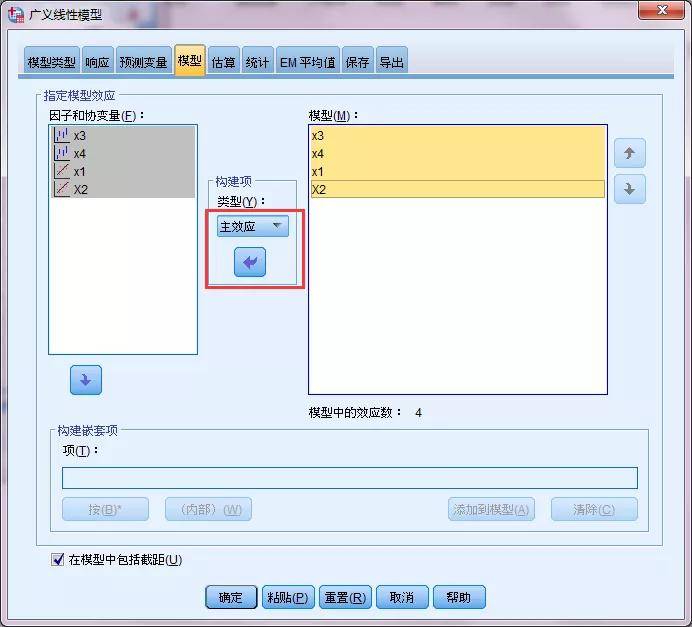
“模型”将四个变量作为主效应选入右框;
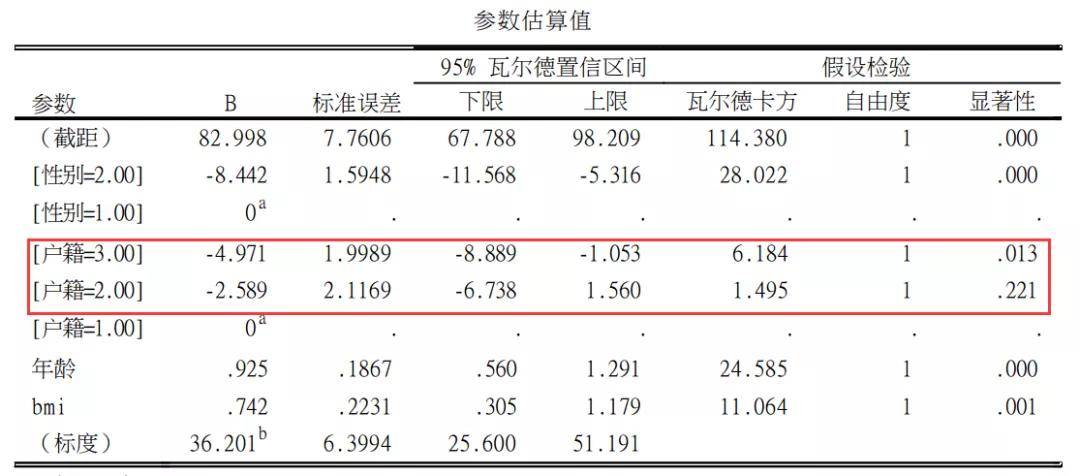
其它设置默认设置,当然需要得到更多信息者,需要更多的设置。 (2)分析结果 广义线性模型给出了关键的结果如下:
广义线性模型基本上与最小二乘法得到线性回归方法结果一致。上表结果显示,与对农村相比,城镇居民血压值无统计学意义(P=0.221),城市血压值具有统计学差异(P=0.013)。 总的来说广义线性模型相对于简单的线性回归来说,过程虽复杂,但少了设置哑变量的过程,而且结果成列更容易阅读,同时可以快速处理多个哑变量的场景,是推荐的处理方法。 哑变量设置的注意事项 1.线性条件不成立是哑变量设置的第一原因 无论线性、logistic还是Cox回归,都要求自变量与y或者y转换值存在着线性关系。如果线性条件不成立,则一种研究方案是对自变量进行哑变量化。其中,无序多分类数据由于不存在着线性的可能性,必须要设定哑变量、有序多分类变量若线性关系成立则可以不设哑变量,若关系不成立,则需要设置哑变量,而当自变量是定量变量,若线性关系不成立,则可以先将自变量分类化处理,再考虑进行哑变量设置分析。关于自变量是定量变量的回归分析方法,本系列将在下一讲着重进行介绍。 如何判断线性条件是否成立呢?具体可以回顾本系列上一讲的链接。 一文汇总三大回归的基本应用条件、诊断与处理方法(线性、logistic、Cox) 这其中,针对有序分类变量,判断线性关系非常重要的一种方法是,分别进行哑变量设置和不进行哑变量设置;比如有三分组变量,首先进行哑变量设置计算。得到回归系数b1和b2,接着进行不设哑变量分析得到b值,若b2-b1=b1或者b2-b1=b大致成立,则说明线性条件成立。具体案例,我将在下一讲再进行进一步陈述。 2. 哑变量设置对照组的考虑 哑变量设置需要考虑的问题包括,第一哑变量设置必须要选择合适的对照,可能是第一组,也可能是最后一组,基本原则一般是,对照组样本量不能过少,对照应该是主流人群、具有特地意义的人群、或者临床研究的正常水平。 例如:我们在研究BMI指数,将BMI指数分为四组进行分析时,一般情况下,是以18.5-24这一组正常人群作为对照。很多人统计分析偷懒,将28的一组作为对照,是非常不合适的。 3. 有序分类变量要不要设置哑变量? 在本文的COX回归中,我针对胰胆管浸润程度进行了哑变量设置分析,实际上,之前推文有对该案例进行分析,没有进行哑变量设置。胰胆管浸润程度是有序变量,允许两种情况同时存在。那么何时考虑何种方法呢? 初学者如何理解Cox回归和HR值 首先,我们需要考虑有序分类变变量与结局的线性关系是否成立,若线性关系成立,则可以不设哑变量,若线性关系不成立,必须设置哑变量。 其次,若线性关系成立,则需要考虑有序自变量等级关系是否等距,很多情况下,等级变量严重不等距,也应该考虑设置哑变量。 再次,如果上述条件都成立,则可以考虑两种分析结果同时进行分析,或者选择一种更有利于专业应用的结果,或者选择一种更有利于论文写作结果解读的的方式进行分析。 关于哑变量更多的细节,我在下一讲再继续介绍。 -本文结束- 系列撰写者:郑卫军,浙江中医药大学医学统计学教研室主任。这里不妨广而告之,如果您有一个临床试验项目,正处于设计阶段,并且将要过医院伦理委员会审核的,不妨联系郑老师统计团队,我们可以帮助您更好的改善临床试验。微信号ZZ566665。 本篇是SPSS 教程之回归建模策略第3篇,更多回归教程请点击下文阅读 1. 一道饕餮大餐来了!手把手教你如何科学地构建回归模型! 2. 一文汇总三大回归的基本应用条件、诊断与处理方法(线性、logistic、Cox)
|

 返回搜狐,查看更多
返回搜狐,查看更多【本文地址】
今日新闻 |
推荐新闻 |